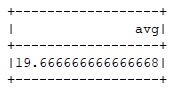一、UDAF简介
先解释一下什么是UDAF(User Defined Aggregate Function),即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组(一般是多行)输入然后产生一个输出,即将一组的值想办法聚合一下。
关于UDAF的一个误区
我们可能下意识的认为UDAF是需要和group by一起使用的,实际上UDAF可以跟group by一起使用,也可以不跟group by一起使用,这个其实比较好理解,联想到mysql中的max、min等函数,可以:
| 1 |
|
表示根据bar字段分组,然后求每个分组的最大值,这时候的分组有很多个,使用这个函数对每个分组进行处理,也可以:
| 1 |
|
这种情况可以将整张表看做是一个分组,然后在这个分组(实际上就是一整张表)中求最大值。所以聚合函数实际上是对分组做处理,而不关心分组中记录的具体数量。
二、UDAF使用
2.1 继承UserDefinedAggregateFunction
使用UserDefinedAggregateFunction的套路:
1. 自定义类继承UserDefinedAggregateFunction,对每个阶段方法做实现
2. 在spark中注册UDAF,为其绑定一个名字
3. 然后就可以在sql语句中使用上面绑定的名字调用
下面写一个计算平均值的UDAF例子,首先定义一个类继承UserDefinedAggregateFunction:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
|
然后注册并使用它:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
使用到的数据集:
| 1 2 3 4 5 6 |
|
运行结果:

2.2 继承Aggregator
还有另一种方式就是继承Aggregator这个类,优点是可以带类型:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
|
调用:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
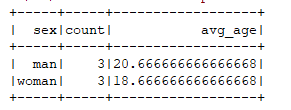
运行结果: