1、如图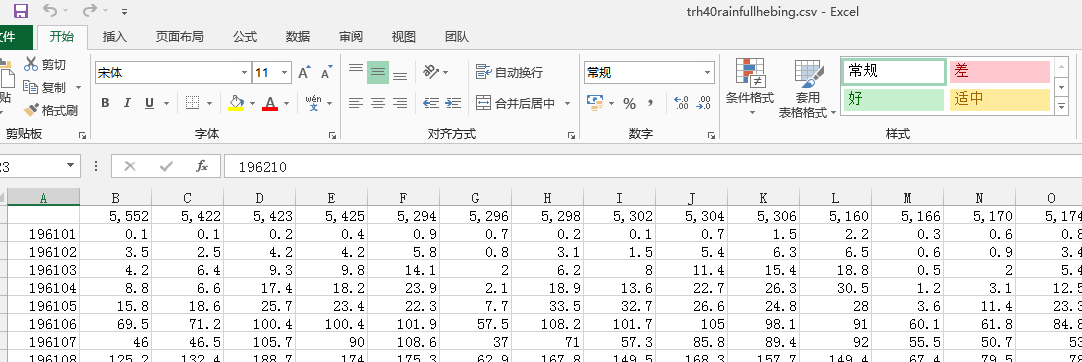 为所有站点数据,现在需要将该数据处理成按照年份拆分成每年的数据文件。
为所有站点数据,现在需要将该数据处理成按照年份拆分成每年的数据文件。
代码如下:
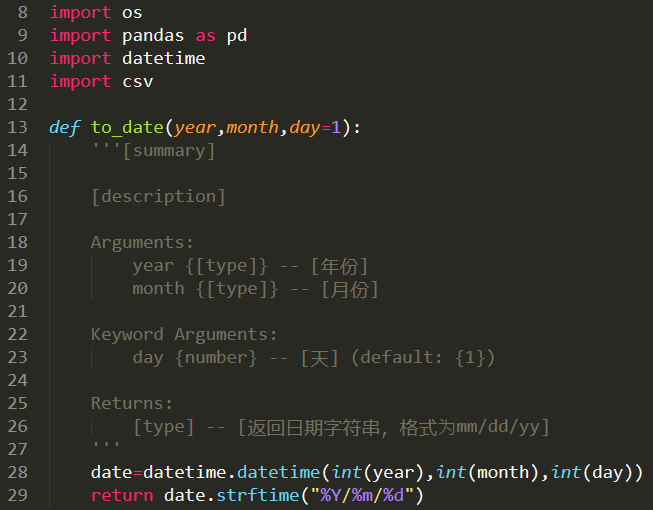
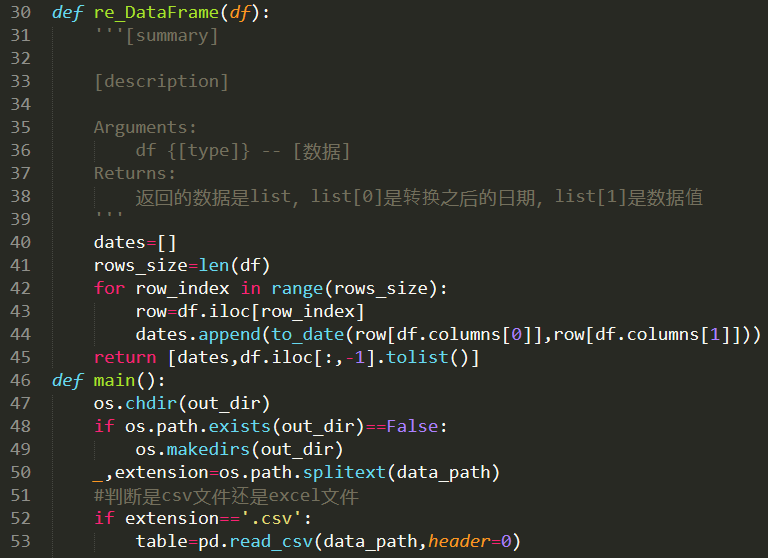
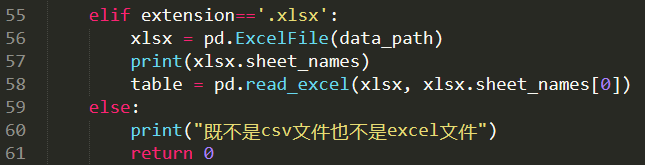
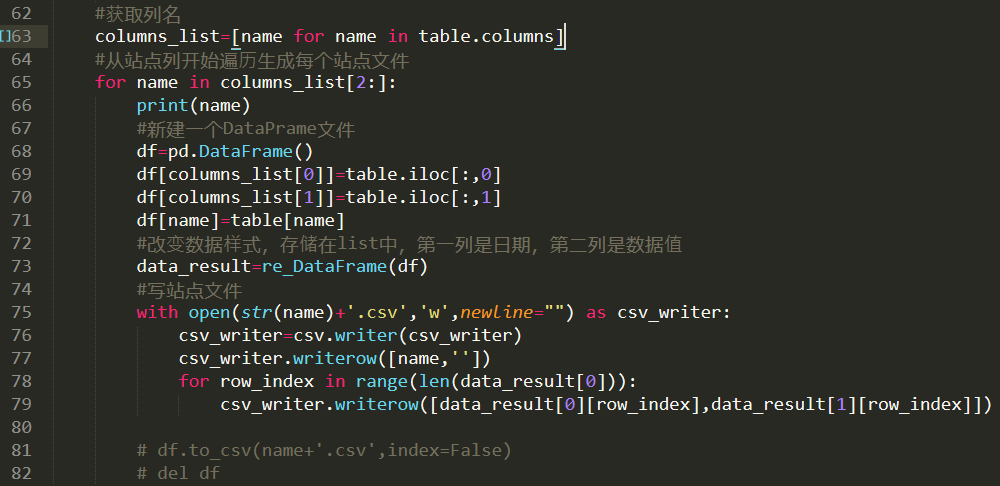
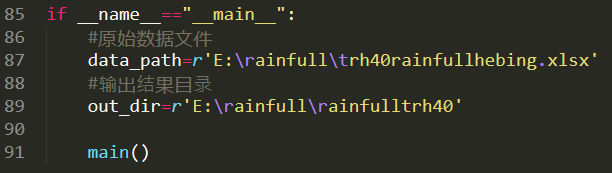
2、经过上述代码运行,得到数据列表。具体代码如下:
1 import os 2 import pandas as pd 3 import datetime 4 import csv 5 6 def to_date(year,month,day=1): 7 '''[summary] 8 9 [description] 10 11 Arguments: 12 year {[type]} -- [年份] 13 month {[type]} -- [月份] 14 15 Keyword Arguments: 16 day {number} -- [天] (default: {1}) 17 18 Returns: 19 [type] -- [返回日期字符串,格式为mm/dd/yy] 20 ''' 21 date=datetime.datetime(int(year),int(month),int(day)) 22 return date.strftime("%Y/%m/%d") 23 def re_DataFrame(df): 24 '''[summary] 25 26 [description] 27 28 Arguments: 29 df {[type]} -- [数据] 30 Returns: 31 返回的数据是list,list[0]是转换之后的日期,list[1]是数据值 32 ''' 33 dates=[] 34 rows_size=len(df) 35 for row_index in range(rows_size): 36 row=df.iloc[row_index] 37 dates.append(to_date(row[df.columns[0]],row[df.columns[1]])) 38 return [dates,df.iloc[:,-1].tolist()] 39 def main(): 40 os.chdir(out_dir) 41 if os.path.exists(out_dir)==False: 42 os.makedirs(out_dir) 43 _,extension=os.path.splitext(data_path) 44 #判断是csv文件还是excel文件 45 if extension=='.csv': 46 table=pd.read_csv(data_path,header=0) 47 48 elif extension=='.xlsx': 49 xlsx = pd.ExcelFile(data_path) 50 print(xlsx.sheet_names) 51 table = pd.read_excel(xlsx, xlsx.sheet_names[0]) 52 else: 53 print("既不是csv文件也不是excel文件") 54 return 0 55 #获取列名 56 columns_list=[name for name in table.columns] 57 #从站点列开始遍历生成每个站点文件 58 for name in columns_list[2:]: 59 print(name) 60 #新建一个DataPrame文件 61 df=pd.DataFrame() 62 df[columns_list[0]]=table.iloc[:,0] 63 df[columns_list[1]]=table.iloc[:,1] 64 df[name]=table[name] 65 #改变数据样式,存储在list中,第一列是日期,第二列是数据值 66 data_result=re_DataFrame(df) 67 #写站点文件 68 with open(str(name)+'.csv','w',newline="") as csv_writer: 69 csv_writer=csv.writer(csv_writer) 70 csv_writer.writerow([name,'']) 71 for row_index in range(len(data_result[0])): 72 csv_writer.writerow([data_result[0][row_index],data_result[1][row_index]]) 73 74 # df.to_csv(name+'.csv',index=False) 75 # del df 76 77 78 if __name__=="__main__": 79 #原始数据文件 80 data_path=r'E:\rainfull\trh40rainfullhebing.xlsx' 81 #输出结果目录 82 out_dir=r'E:\rainfull\rainfulltrh40' 83 84 main()