创建csdn博客scrapy
 为了避免冲突,独立将生成的csdnSpider文件夹打开
为了避免冲突,独立将生成的csdnSpider文件夹打开
1编写csdn.py
# -*- coding: utf-8 -*-
import scrapy
class CsdnSpider(scrapy.Spider):
name = 'csdn'
allowed_domains = ['csdn.net']
start_urls = ['https://blog.csdn.net/weixin_40543283',
# https: // blog.csdn.net / weixin_40543283
]
def parse(self, response):
pass
2.item.py
import scrapy
class csdnItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
content = scrapy.Field()
3.解析页面csdn.py—>parse
审查元素–>查找规律—>解析页面
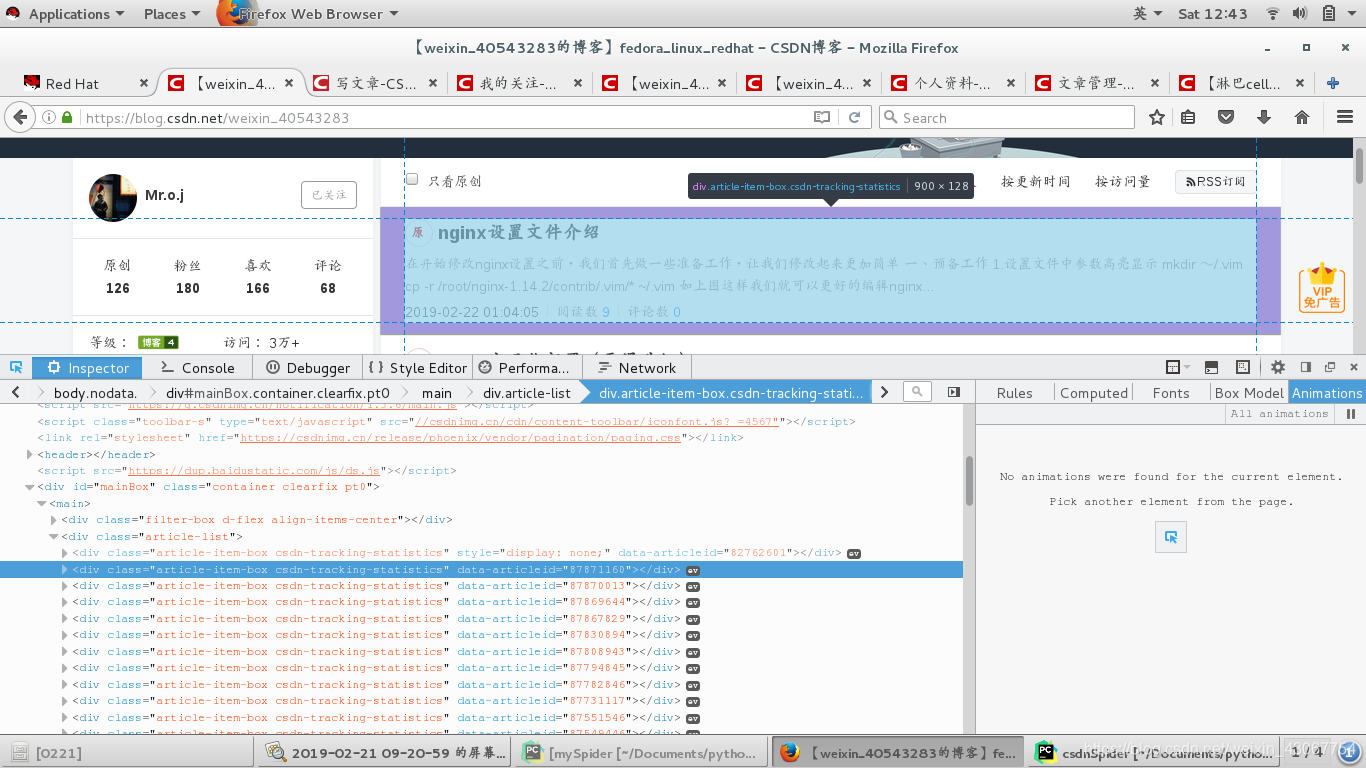
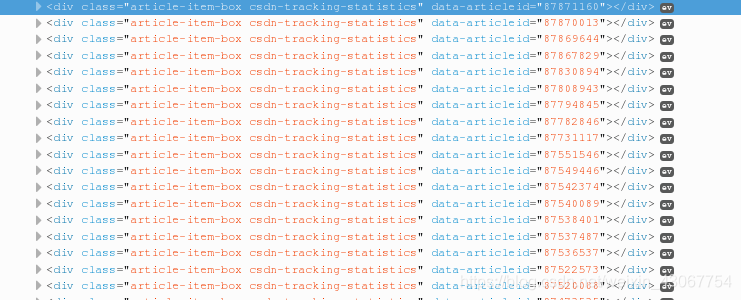 发现每篇博客都存放在
发现每篇博客都存放在<div class="article-item-box csdn-tracking-statistics" data-articleid="87871160">这个标签里
点开分析:

我们需要标题(a标签里)和url地址(href)
def parse(self, response):
boxs = response.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
for box in boxs:
item = CsdnspiderItem()
# 类似于字典的对象
# ************将item对象实例化在for循环里面, 否则每次会覆盖之前item的信息;*******
item['title'] = box.xpath('./h4/a/text()')[1].extract().strip()
# 当前div标签里的h4标签下的a标签里的文本信息,有两个文本信息取索引为1的,
# 不加extract()将生成一个对象,因为标题中打印左右两侧右空格 所以用strip去掉
# html代码
# <h4 class="">
# <a href="https://blog.csdn.net/weixin_40543283/article/details/87871160" target="_blank">
# <span class="article-type type-1">
# 原 </span>
# nginx设置文件介绍 </a>
# </h4>
item['url'] = box.xpath('./h4/a/@href')[0].extract()
# 这个url进去就是博客内容
# print("1. *****************", item['title'])
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.parse_article)
# 返回一个请求给parse_article,将item中获得的url地址返回,meta 传递的内容
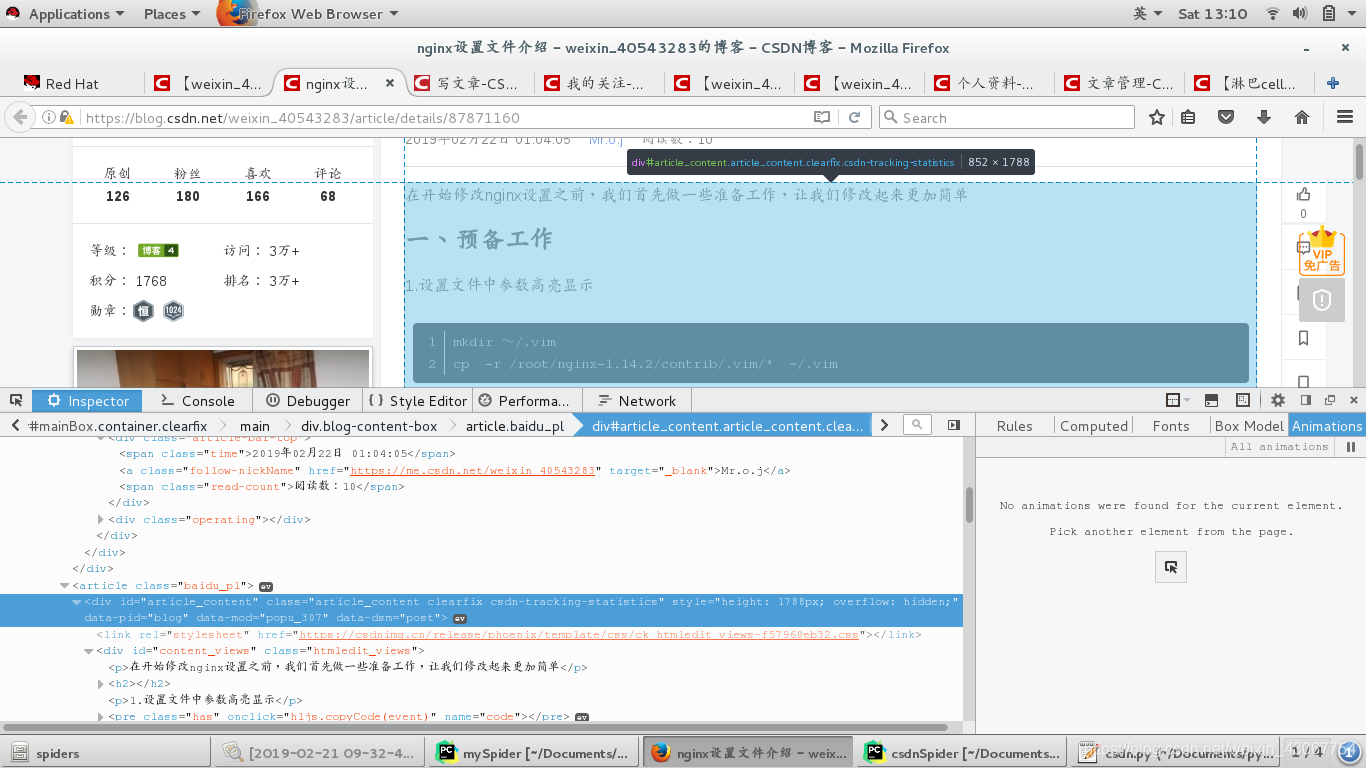
这里url保存的就是博客内容,所以我们需要再对url这个新页面进行解析:这里我们不需要标题信息,直接需要博客内容所以我们找到博客内容的标签:
<div style="height: 1788px; overflow: hidden;" id="article_content" class="article_content clearfix csdn-tracking-statistics" data-pid="blog" data-mod="popu_307" data-dsm="post">
# 解析content
def parse_article(self,response):
item = response.request.meta['item']
content = response.xpath('//div["article_content"]').extract()[0]
item['content'] = content
yield item
因为我们需要爬取的是博客里所有内容,所以还应该实现一个翻页功能。我翻页到第二页发现有规律:只要改变页码2就可以翻页。

所以在settings里面添加一个页码csdnpage,我这个爬取的博客有9页。
 在csdn.py文件中导入
在csdn.py文件中导入
from csdnSpider.settings import CsdnPage
# 实现翻页的功能
for page in range(2, CsdnPage+1):
url = "https://blog.csdn.net/weixin_40543283/article/list/%s" %(page)
yield scrapy.Request(url, callback=self.parse)
# 解析content
完整的csdn.py文件:
import scrapy
from csdnSpider.items import CsdnspiderItem
from csdnSpider.settings import CsdnPage
class CsdnSpider(scrapy.Spider):
name = 'csdn'
allowed_domains = ['csdn.net']
start_urls = ['https://blog.csdn.net/weixin_40543283',
# 如果想爬去多个网址可以在下面添加
# 'https://blog.csdn.net/gf_lvah',
]
def parse(self, response):
boxs = response.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
for box in boxs:
item = CsdnspiderItem()
# 类似于字典的对象
# ************将item对象实例化在for循环里面, 否则每次会覆盖之前item的信息;*******
item['title'] = box.xpath('./h4/a/text()')[1].extract().strip()
# 当前div标签里的h4标签下的a标签里的文本信息,有两个文本信息取索引为1的,
# 不加extract()将生成一个对象,因为标题中打印左右两侧右空格 所以用strip去掉
# <h4 class="">
# <a href="https://blog.csdn.net/weixin_40543283/article/details/87871160" target="_blank">
# <span class="article-type type-1">
# 原 </span>
# nginx设置文件介绍 </a>
# </h4>
item['url'] = box.xpath('./h4/a/@href')[0].extract()
# 这个url进去就是博客内容
# print("1. *****************", item['title'])
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.parse_article)
# 返回一个请求给parse_article,将item中获得的url地址返回,meta 传递的内容
# 实现翻页的功能
for page in range(2, CsdnPage+1):
url = "https://blog.csdn.net/weixin_40543283/article/list/%s" %(page)
yield scrapy.Request(url, callback=self.parse)
# 解析content
def parse_article(self,response):
item = response.request.meta['item']
content = response.xpath('//div["article_content"]').extract()[0]
item['content'] = content
yield item
4.保存为csv文件,pipeline.py
class CsvspiderPipeline(object):
def __init__(self):
self.f = open('csdn.csv','w')
def process_item(self, item, spider):
item=dict(item)
self.f.write("{0}:{1}:{2}\n".format(item['title'],item['url'],item['content']))
return item
def open_spider(self,spider):
pass
def close_spider(self,spider):
self.f.close()
在settings.py设置文件中设置

这里为了观察结果我只打印了item[‘title’]、item[‘url’]
