需求
爬取csdn账户下所有博客的内容,按照时间排序,把每篇博客生成一份txt文件。
分析
首先需要知道csdn博客中文章列表的格式,以及文章内容页面的格式,如下图:
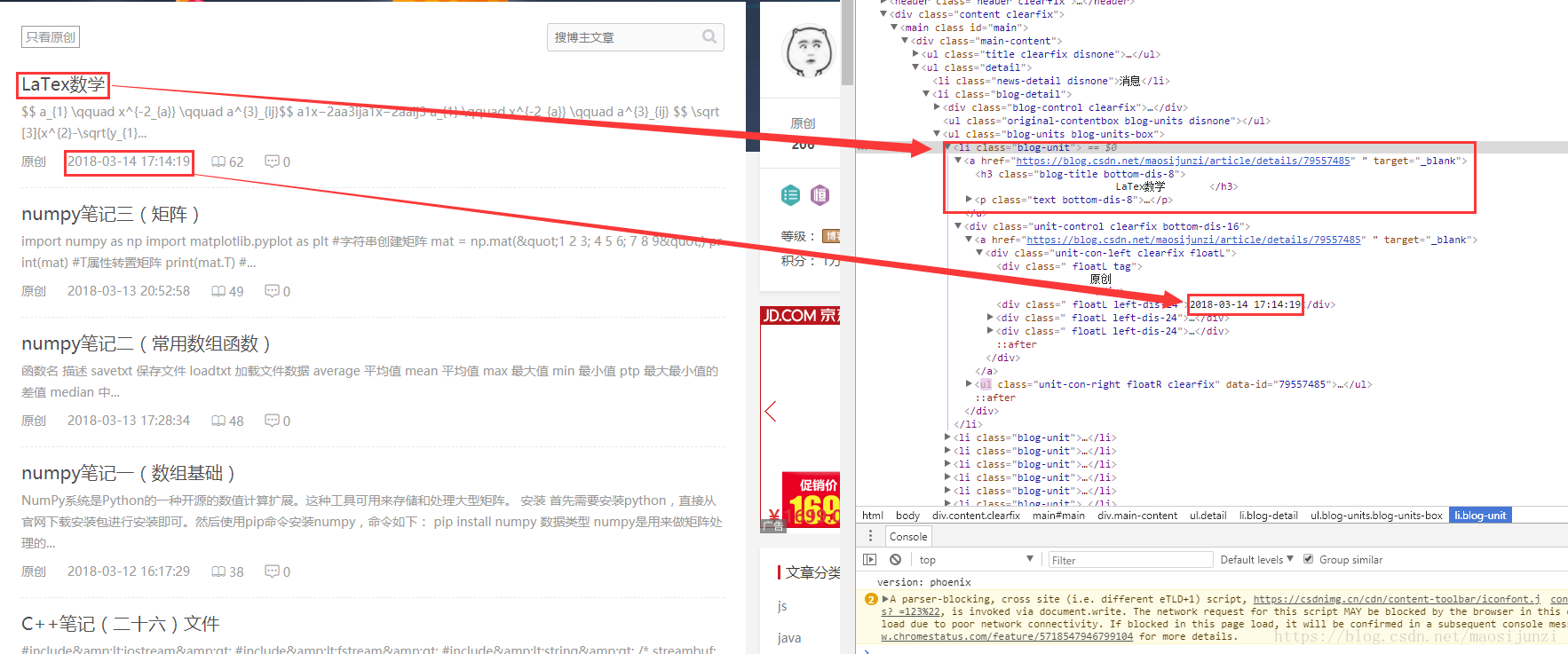
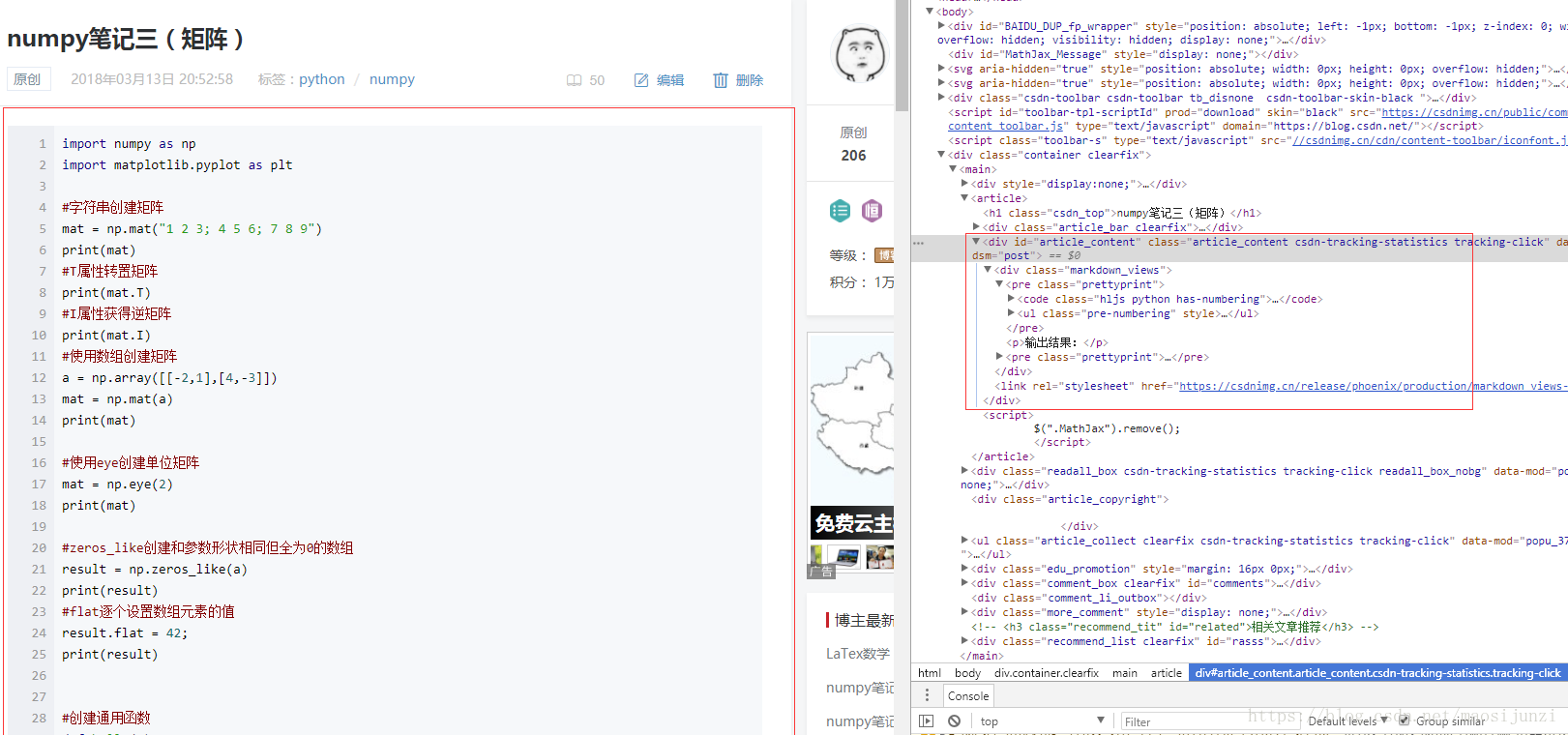
我们要做的就是下载网页内容,然后使用正则表达式来获取网页中我们需要的内容。【文章标题】、【创建时间】,【文章链接】,【文章内容】。另外还要使用正则去除文章内容中的html标签。
爬虫代码
下载网页内容
import urllib.request as request
import urllib.error as error
import time
import re
'''
下载页面
'''
def download(url,user_agent="wswp",num_retries=1 ):
print("download url:",url)
#设置用户代理
headers = {"User-agent":user_agent}
req = request.Request(url,headers=headers)
try:
html = request.urlopen(req).read().decode("utf-8")
except error.URLError as e:
print("download error:",e.reason)
html = None
if num_retries > 0:
if hasattr(e,"code") and 500 <= e.code <= 600:
return download(url,num_retries-1)
return html解析文章标题,时间和连接
'''
解析页面上的文章标题,连接和时间
'''
def parsePage(pageHTML):
links = re.findall("<li class=\"blog-unit\">.*?<a href=\"(.*?)\".*?>.*?<h3.*?>(.*?)</h3>.*?([0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}).*?</li>",html,re.M|re.S) #
for link in links:
datas = []
for data in link:
data = data.replace("\n","")
data = data.replace("\t","")
datas.append(data)
writeAricleToFile(datas)解析网页上的文章
'''
解析文章内容
'''
def parseArticleContent(pageHTML):
return re.findall("<div class=\"(markdown_views|htmledit_views).*?>(.*?)</div[^\"]",pageHTML,re.M|re.S)
'''处理文章内容写入文件
def writeAricleToFile(aparams):
html = download(aparams.pop(0))
#文件名称
atitle = aparams.pop(0)
atitle = atitle.replace("/","-")
atitle = atitle.replace(":","-")
adate = aparams.pop(0)
adate = adate.replace(" ","_")
adate = adate.replace(":","-")
fileName = "C:/Users/Administrator/Desktop/maosijunzi/"+adate+"_"+atitle+".txt"
#文件内容
content = parseArticleContent(html)
content = content[0][1]
#文件内容中去掉html标签
content = re.sub("<.*?>", "", content, flags=re.M|re.S)
content = content.replace("<","<")
content = content.replace(">",">")
print(fileName)
f = open(fileName,"w+",encoding="utf8")
f.write(content)
f.close()程序入口
if __name__ == '__main__':
url = "https://blog.csdn.net/maosijunzi"
html = download(url)
parsePage(html)
page_links = re.findall("<li class=\"page-item.*?<a href=\"(.*?)\".*?</li>",html,re.M|re.S)
maxPageNum = 1
for page_link in page_links:
pageNum = int(page_link[page_link.rfind("/")+1:])
if pageNum > maxPageNum:
maxPageNum = pageNum
pageUrl = "https://blog.csdn.net/maosijunzi/article/list/"
pageNum = 2
while pageNum <= maxPageNum:
newPageUrl = pageUrl + str(pageNum)
html = download(newPageUrl)
parsePage(html)
pageNum = pageNum + 1