原文地址丢失,请谅解!
1.准备训练样本图片
1.1样本的采集:
样本图片最好使用灰度图,且最好根据实际情况做一定的预处理;样本数量越多越好,尽量高于1000,样本间差异性越大越好
正负样本比例为1:3最佳;尺寸为20x20最佳。
1.1.1正样本
训练样本的尺寸为20*20(opencv推荐的最佳尺寸),且所有样本的尺寸必须一致。如果不一致的或者尺寸较大的,可以先将所有样本统一缩放到20*20。
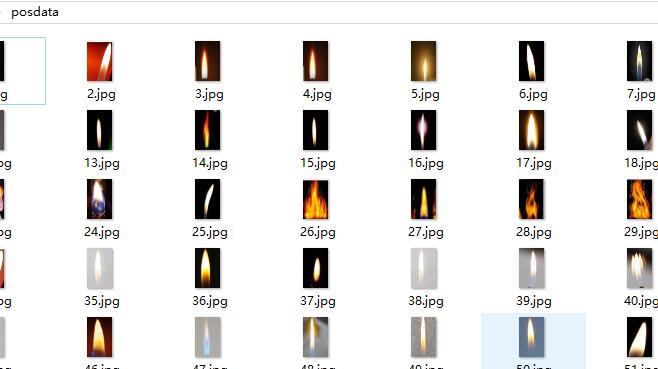
以下就是我用来训练的正样本:
1.1.2负样本
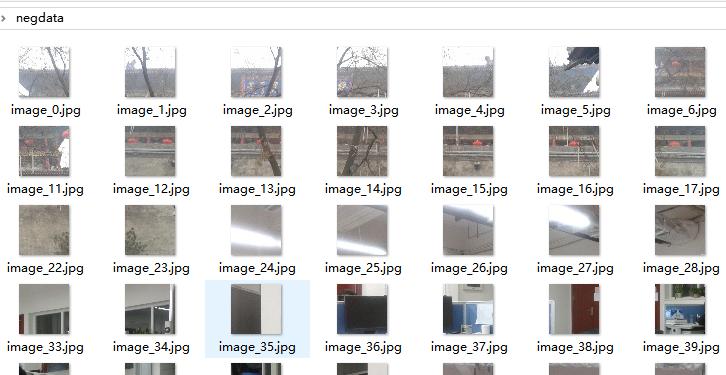
这里要提醒一下,虽然负样本就是样本中不存在正样本的内容。但也不能随意的找些图片来作为负样本,比如什么天空,大海,森林等等。最好是根据不同的项目选择不同的负样本,比如一个项目是做机场的人脸检测,那么就最好从现场拍摄一些图片数据回来,从中采集负样本。其实正样本的采集也应该这样。不同的项目,就采集不同的正样本和负样本。因为项目不同,往往相机的安装规范不同,场景的拍摄角度就不同。
1.1.3 准备好工作目录
negdata目录: 放负样本的目录
posdata目录: 放正样本的目录
xml目录: 新建的一个目录,为之后存放分类器文件使用
negdata.txt: 负样本路径列表
posdata.txt: 正样本路径列表
pos.vec: 后续自动生成的样本描述文件
opencv_createsamples.exe: 生成样本描述文件的可执行程序(opencv自带)
opencv_haartraining.exe: 样本训练的可执行程序(opencv自带)
将下图中的所有文件拷贝到样本同级目录

1.1.4生成样本描述文件
1,生成正样本描述文件
进入posdata目录
执行dir /b/s/p/w *.jpg > pos.txt
2,生成负样本描述文件
进入negdata目录
执行dir /b/s/p/w *.jpg > neg.txt
打开正负样本描述文件如图:
将jpg全部替换成下面的格式
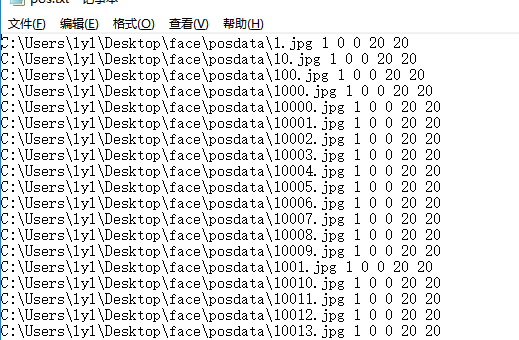
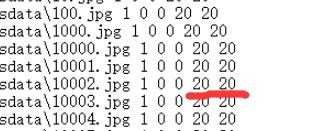
图中划线处为图片像素大小
将正负样本描述文件拷贝到与opencv_createsamples.exe文件同一目录
1.1.5生成.vec文件
opencv_createsamples.exe -vec pos.vec -info pos.txt -num 18500 -w 20 -h 20
opencv_createsamples.exe -vec neg.vec -info neg.txt -num 10500 -w 50 -h 50
出现以下信息即是生成成功(样本不标准会出错)

说明:
-info,指样本说明文件
-vec,样本描述文件的名字及路径
-num,总共几个样本,要注意,这里的样本数是指标定后的20x20的样本数,而不是大图的数目,其实就是样本说明文件第2列的所有数字累加
-w -h指明想让样本缩放到什么尺寸。这里的奥妙在于你不必另外去处理第1步中被矩形框出的图片的尺寸,因为这个参数帮你统一缩放!(我们这里准备的样本都是20*20)
1.1.6训练样本
新建文件traincascade.bat
把
opencv_traincascade.exe -data xml -vec pos.vec -bg neg.txt -numPos 500 -numNeg 656 -numStages 20 -w 20 -h 20 -mode ALL
pause
复制进去保存
准备好数据后,就该训练了,根据官网参数的提示进行设置。一下是我的设置,可参考:
opencv_traincascade -data cascade_license_dir -vec licenseVec -bg LicenseText.txt -numPos 800 -numNeg 4000 -numStages 15 -featureType LBP -w 45 -h 25 -minHitRate 0.99 -maxFalseAlarmRate 0.3 -bt DAB -maxDepth 2
1
记得-w 和-h就是小写的,还有-minHitRate和-maxFlaseAlarmRate参数,不然训练速度很快,而且训练的效果不理想。 -numNeg会比实际准备的负样本个数大两三倍,并且-w和-h和用opencv_createsamples中用的-w和-h保持一致,不然会报错。
训练完之后,进行测试,分类器效果还是不够理想,会把相近的都选中,降低 -maxFlaseAlarmRate的参数,提高-numPos参数,以及把负样本也做一次直方图均衡化,在加些标准的负样本。再次进行训练。
中途报错:Can not get new positive sample.The most possible reason id insufficient count of samples is given veg-file.
出现这种错的原因提示中很明显,正样本的数目不够,也就是-numPos设置的大了。加入正样本的数目一共有1900张,-numPos设置的是1800张,那么在第一级分类器中,会在1900张图片中选择1800张,在准确率达到0.99时结束第一级训练,那么分类器认为正样本还有18000.99张;到了第二级分类器,依旧需要输入1800张图片,那么还得从剩余的(1900-1800)张图片中选择(1800-18000.99)张,加上第一级分类器筛选出的正样本一起去训练,依次类推,假如你剩余的样本少于分类器需要的正样本数目,就会报错。所以设置-numPos的时候尽量是正样本数目的80%左右。
错误:Train dataset for temp stage can not be filled. Branch training terminated.
若出现这种错误,是负样本的路径有问题,-bg 后面的参数只能是文件名称,不能是路径+文件名称,需要把负样本的txt文件放到当前目录下,并在txt文件中的路径加上负样本图片的文件名。
把pos.txt和neg.txt改回如图格式(注意:这一步至关中重要)
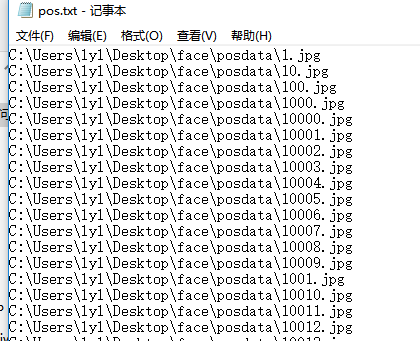
然后双击traincascade.bat进行训练
说明:

点击训练后会出现如图所示代表正确训练中

训练结束后会在xml目录下生成如图文件(其中cascade.xml就是我们训练得到的分类器)
