代码:https://github.com/wuhuikai/DeepGuidedFilter
该论文将何凯明的引导滤波思想引入了深度学习。我们都知道引导滤波的引导矩阵,根据不同的任务需要手工选定。在这篇文章里,作者将引导图片作为神经网络的学习的一部分,根据不同的任务会自动学习出该引导矩阵。
在利用神经网络生成图片中,特别是高分辨率图片,一般其速度非常慢,比如pix2pix。该论文在引入引导滤波后只需要先生产低分辨率图片,然后将引导矩阵上采样,接着利用引导滤波公式就能够生产高分辨率的图片。这样一来主要计算都集中在低分辨率的图片上,高分辨图片生成的计算量就变得很少。其实在pix2pixHD中也有类似的设计,只不过不是用引导滤波。下图是论文的主要思想:
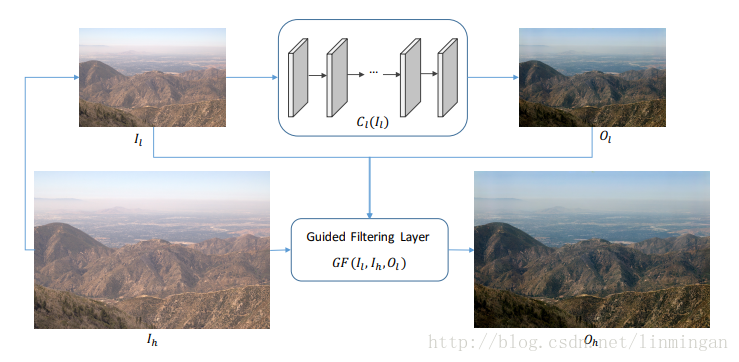
其中
高分辨率输出图片
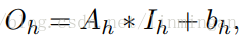
其中
OK,其实我们最关心的还是引导滤波层的设计或者说
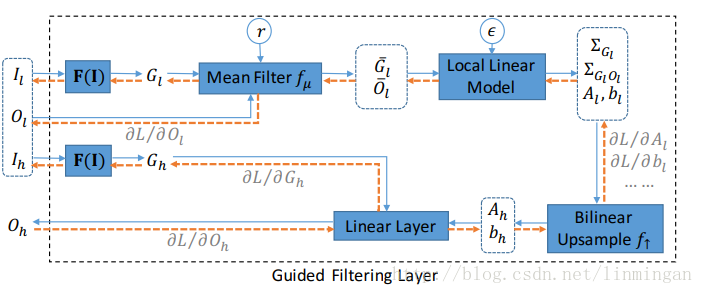
图中蓝色箭头代表正向传播,橙色箭头代表反向传播,我们只关注正向传播。
F(I)也是由卷积层构成,不过比较小,就两层而已。

其中
将算法中的第3,4步,与引导滤波中求解a和b公式对比一下,发现几乎完全一样。
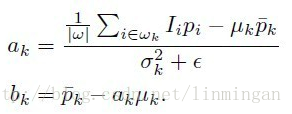
其中
实验结果
速度和占用内存比较:
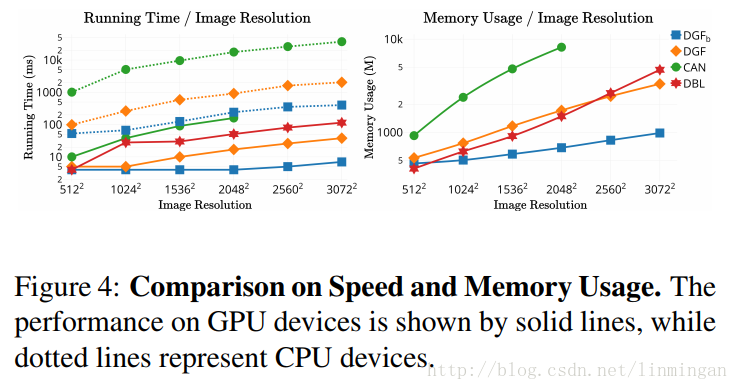
虚线代表CPU,实线代表GPU。DGF代表论文的模型。可以发现论文的算法速度非常快,特别是在高分辨率情况下。
效果:
