文章目录
1. Hive 入门
1.1 什么是 Hive
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计,现已归于 Apache。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
本质是:将 HQL 转化成 MapReduce 程序。
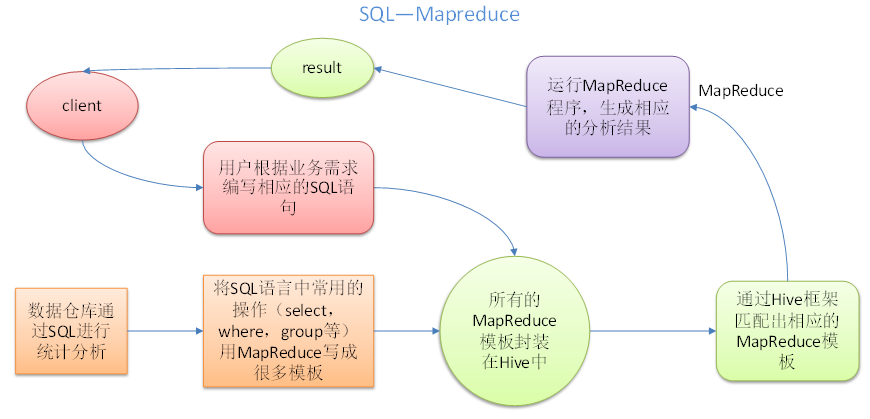
- Hive 处理的数据存储在 HDFS
- Hive 分析数据底层的实现是 MapReduce
- 执行程序运行在 Yarn 上
1.2 Hive 的优缺点
-
优点
① 操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
② 避免了去写 MapReduce,减少开发人员的学习成本。
③ Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
④ Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
⑤ Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。 -
缺点
① Hive 的 HQL 表达能力有限
⑴ 迭代式算法无法表达
⑵ 数据挖掘方面不擅长② Hive 的效率比较低
⑴ Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
⑵ Hive 调优比较困难,粒度较粗
1.3 Hive 架构原理
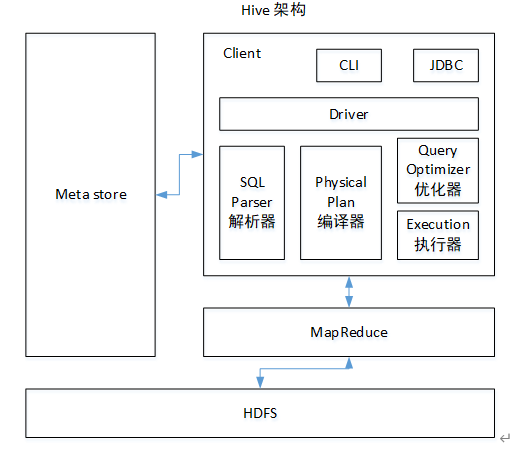
-
用户接口:Client
CLI(hive shell)、JDBC/ODBC(java 访问 hive)、WEBUI(浏览器访问 hive)
-
元数据:Meta store
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Meta store -
Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
-
驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是MR/Spark。
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
1.4 Hive 和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的。
-
查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发可以很方便的使用 Hive 进行开发。
-
数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
-
数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的。
-
索引
Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 Key 建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
-
执行
Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
-
执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
-
可扩展性
由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo,2009 年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
-
数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
2. Hive 安装
2.1 下载地址
2.2 Hive 安装部署
-
Hive 安装及配置
① 将 hive 的安装包上传到 Linux 服务器上(apache-hive-2.3.6-bin.tar.gz)
② 解压安装包到指定目录下
tar -zxvf apache-hive-2.3.6-bin.tar.gz -C /hadoop/
③ 重命名解压后的目录
mv apache-hive-2.3.6-bin/ hive-2.3.6
④ 修改 /hadoop/hive/conf 目录下的 hive-env.sh.template 名称为 hive-env.sh
mv hive-env.sh.template hive-env.sh
⑤ 配置 hive-env.sh 文件
配置 HADOOP_HOME 路径
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/hadoop/hadoop-2.7.7
配置 HIVE_CONF_DIR 路径
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/hadoop/hive-2.3.6/conf
⑥ 配置 hive 环境变量
vim /etc/profile
#HIVE
export HIVE_HOME=/hadoop/hive-2.3.6
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
-
Hadoop 集群配置
① 必须启动 hdfs 和 yarn
② 在 HDFS 上创建 /tmp 和 /user/hive/warehouse 两个目录并修改他们的同组权限可写
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
2.3 MySql 安装
- 查看 mysql 是否安装,如果安装了,卸载 mysql
rpm -qa|grep mysql
rpm -qa|grep mariadb
使用以下命令进行移除操作
rpm -e --nodeps {file-name}
- 解压 mysql 安装包(mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar)
tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C mysql/
- 按照依赖关系依次安装 rpm 包,依赖关系依次为 common→libs→client→server
rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
注:ivh 中, i-install 安装;v-verbose 进度条;h-hash 哈希校验
-
mysql 初始化配置,设置 root 密码
① 停止 mysql 服务
systemctl stop mysqld.service
② 设置免密登陆
vim /etc/my.cnf
添加这句话,这时候登入 mysql 就不需要密码
skip‐grant‐tables
③ 重启 mysql 服务
systemctl start mysqld.service
④ 进入 mysql,更改密码
mysql -u root
use mysql;
update user set authentication_string=PASSWORD("19990628") where user="root";
quit;
⑤ 退出免密登陆
systemctl stop mysqld.service
vim /etc/my.cnf
注释免密登录
#skip‐grant‐tables
systemctl start mysqld.service
⑤ 密码登录 mysql
mysql -u root -p
接下来根据提示,输入刚才修改的密码即可
;
2.4 MySql 中 user 表中主机配置
配置只要是 root 用户 + 密码,在任何主机上都能登录 MySQL 数据库。
- 进入 mysql
mysql -u root -p
- 使用 mysql 数据库
use mysql;
- 查询 user 表
select User, Host from user;
- 修改 user 表,把 Host 表内容修改为 %
update user set host='%' where host='localhost';
-
根据查询结果,删除 root 用户的其他 host
-
刷新
flush privileges;
- 退出
quit
2.4 Hive 元数据配置到 MySql
- 驱动拷贝,将驱动拷贝到到 /hadoop/hive-2.3.6/lib/ 目录下(mysql-connector-java-5.1.46.jar)
cp mysql-connector-java-5.1.46.jar /hadoop/hive-2.3.6/lib/
-
配置 Meta store 到 MySql
① 在 /hadoop/hive-2.3.6/conf 目录下创建一个 hive-site.xml
touch hive-site.xml
② 在文件中,拷贝以下数据
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>19990628</value>
<description>password to use against metastore database</description>
</property>
</configuration>
③ 初始化元数据库
schematool -dbType mysql -initSchema
- 测试 hive 是否可用
hive
show databases;
2.5 Hive 基本操作
2.5.1 Hive 基本操作
- 启动 hive
hive
- 查看数据库
show databases;
- 打开默认数据库
use default;
- 显示 default 数据库中的表
show tables;
- 创建一张表
create table student(id int, name string);
- 查看表的结构
desc student;
- 向表中插入数据
insert into student values(1000,"xiaoming");
- 查询表中数据
select * from student;
- 删除已创建的 student 表
drop table student;
- 退出 hive
quit;
2.5.2 将本地文件导入 Hive 案例
需求: 将本地 /root/data/student.txt 这个目录下的数据导入到 hive 的 student(id int, name string) 表中。
- 创建 student.txt 数据(以 tab 键间隔)
1001 zhangshan
1002 lishi
1003 zhaoliu
- 启动 hive
hive
- 使用 default 数据库
use default;
- 创建 student 表, 并声明文件分隔符 ’\t’
create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
- 加载 /root/data/student.txt 文件到 student 数据库表中。
load data local inpath '/root/data/student.txt' into table student;
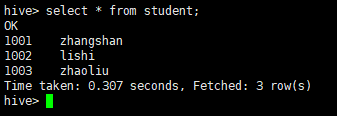
- Hive 查询结果
select * from student;
2.5.3 Hive 常用交互命令
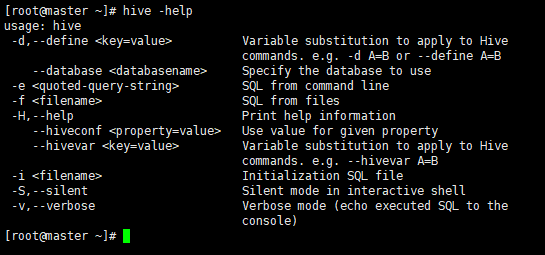
- “-e” 不进入 hive 的交互窗口执行 sql 语句
hive -e "select id from student;"
-
“-f” 执行脚本中 sql 语句
① 创建 hive.sql 文件
select id from student;
② 执行文件中的 sql 语句
hive -f hive.sql
③ 执行文件中的 sql 语句并将结果写入文件中
hive -f hive.sql > hive_result.txt
2.5.4 Hive 其他命令操作
- 退出 hive 窗口:
exit;
quit;
- 在 hive client 命令窗口中如何查看 hdfs 文件系统
dfs -ls /;
- 在 hive client 命令窗口中如何查看本地文件系统
! ls /root;
-
查看在 hive 中输入的所有历史命令
① 进入到当前用户的根目录
② 查看 .hivehistory 文件
cat .hivehistory
2.6 HiveJDBC 访问
- 启动 hiveserver2 服务
hiveserver2
- 启动 beeline
beeline
- 连接 hiveserver2
!connect jdbc:hive2://master:10000
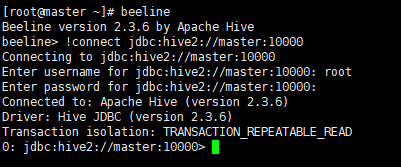
注意:这里可能出现报错:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://master:10000: Failed to open new session: java.lang.RuntimeException:org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous root(state=08S01,code=0)
解决方法:参考博客
2.7 Hive 常见属性配置
2.7.1 Hive 数据仓库位置配置
- 默认数据仓库的最原始位置是在 hdfs 上的:/user/hive/warehouse 路径下。
- 在仓库目录下,没有对默认的数据库 default 创建文件夹。如果某张表属于 default 数据库,直接在数据仓库目录下创建一个文件夹。
- 修改 default 数据仓库原始位置(将 hive-default.xml.template 如下配置信息拷贝到 hive-site.xml 文件中)。
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
配置同组用户有执行权限
hdfs dfs -chmod g+w /user/hive/warehouse
2.7.2 查询后信息显示配置
- 在 hive-site.xml 文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
-
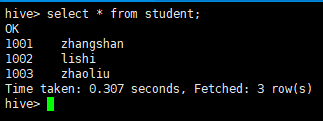
重新启动 hive,对比配置前后差异。
① 配置前
② 配置后

2.7.3 Hive 运行日志信息配置
-
Hive 的 log 默认存放在 /tmp/root/hive.log目录下(当前用户名下)
-
修改 hive 的 log 存放日志到 /hadoop/hive-2.3.6/logs
① 修改 /hadoop/hive-2.3.6/conf/hive-log4j2.properties.template 文件名称为 hive-log4j2.properties
mv hive-log4j2.properties.template hive-log4j2.properties
② 在 hive-log4j2.properties 文件中修改 log 存放位置
property.hive.log.dir = /hadoop/hive-2.3.6/logs
2.7.4 参数配置方式
- 查看当前所有的配置信息(在 hive client 下)
set;
-
参数的配置三种方式
① 配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml注意: 用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件的设定对本机启动的所有 Hive 进程都有效。
② 命令行参数方式
启动 Hive 时,可以在命令行添加 -hiveconf param=value 来设定参数。(仅对本次hive启动有效)
hive -hiveconf mapred.reduce.tasks=10;
③ 参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
set mapred.reduce.tasks=100;
查看参数设置
set mapred.reduce.tasks;