第三章 关系数据库标准语言SQL
本章主要讲解SQL语言的操作,主要介绍了用SQL语言怎么实现第二章中介绍的关系操作。对本章的笔记主要记录一下,各操作的分类和需要特别重要的点,便于我记忆和以后扫描一下能回忆起来。具体语法其实可以上菜鸟教程学习。
3.1 概述
3.1.2 SQL的特点
SQL主要包括以下特点:
综合统一
非关系模型(层次模型、网状 模型)的数据语言一般分为 模式数据定义语言(模式DDL)、外模式DDL、数据存储有关的描述语言(DSDL)、数据操纵语言(DML)
SQL集数据定义语言、数据操纵语言、数据控制语言的功能于一体,语言风格统一,可以独立完成数据库生命周期中的全部活动
高度非过程化
非关系数据模型的数据操纵语言是 面向过程 的语言,用过程化的语言完成某项请求必须指定存取路径
用SQL进行数据操作时,无需指明和了解存储路径,存储路径的选择以及SQL的操作过程由系统自动完成。
面向集合的操作方式
非关系数据模型采用的是面向记录的操作方式,操作对象是一条记录;查询数据要说明按照哪条路径、如何循环等,将记录一条一条找出来。
SQL采用集合操作方式,不仅操作对象,查找结果可以是元组的集合,插入、删除、更新的对象也可以是元组的集合。
以同一中语法结构提供多种使用方式
SQL即是独立的语言,又是嵌入式语言;即能独立用于联机交互使用方式,又能嵌入高级语言(如C++,Java)中
语言简洁,易学易用
完成核心功能只用了9个动词(Select,Create,Drop,Alter,Insert, Update,Delete,Grant, Revoke),而且语法接近英语口语,易于学习使用。
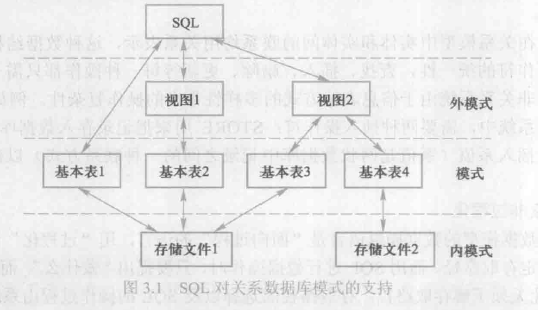
支持SQL的关系数据库管理系统同样支持关系数据库管理系统的三级模式结构:
- 外模式包括若干是视图和部分基本表 视图是从一个或几个基本表导出的表,本生不独立存储再数据库中,数据库中只存放视图定义而不存放视图对应数据,因此视图只是虚表。
- 模式包括若干基本表
- 内模式包括若干存储文件
3.3 数据定义
关系数据库系统支持三级模式结构,其模式、外模式和内模式中的基本对象有模式、表、视图和索引等。
因此SQL的数据定义功能包括模式定义、表定义、视图和索引的定义: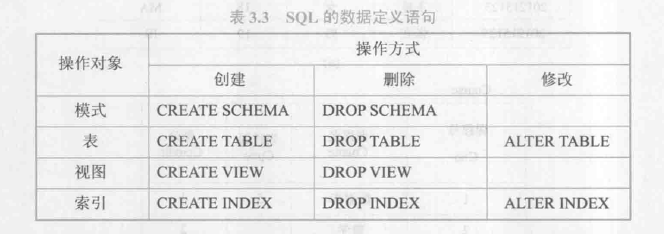
3.3.1 模式的定义与删除
定义模式实际上是定义了一个命名空间,再这个空间中可以进一步定义该模式包含的数据库对象,例如基本表、视图、索引等。
定义模式
创建模式时,如果没有指定模式名,那么模式名隐含为用户名
删除模式
CASCADE(级联)和RESTRICT(限制)二者必选其一
级联表示删除模式的同时把模式中所有的数据库对象全部删除
限制白哦是如果模式中定义了下属的数据库对象(表、视图等),则拒绝执行删除语句
3.3.2 基本表的定义、删除与修改
定义基本表
注意数据类型
注意列级完整性约束条件
注意表级约束条件
模式与表
定义基本表所属模式的三种方式:
- 创建表时,在表名中显示地给出模式名(模式名.表名)
- 在创建模式地语句中同时创建表
- 设置当前所属的模式
修改基本表
需要注意Drop列的时候,可选CASCADE(级联)和RESTRICT(限制),前者会导致引用了该列的对象被级联删除,后者则如果发生引用,将拒绝删除
删除基本表
同样需注意可选条件CASCADE(级联)和RESTRICT(限制),默认RESTRICT
3.3.3 索引的建立与删除
当表的数据量比较大时,查询操作会比较耗时。建立索引时加快查询速度的有效手段。
用户可以根据应用环境的需要在基本表上建立一个或多个索引,以提供多种存取路径,加快查找速度。
索引是关系数据库管理系统的内部实现技术,属于内模式的范畴
常见索引类型:
顺序文件上的索引
按指定属性值升序或降序存储的关系(表),在该属性上建立索引文件
索引文件由属性值和相应元组指针组成。
B+树索引
B+树的叶节点为属性值和相应的元组指针
散列(hash)索引
建立若干桶,根据索引属性散列到相应的桶,桶中存放索引属性值和相应元组指针
位图索引
用位向量记录索引属性中可能出现的值,每个位向量对应一个可能值
建立索引
索引可建立在一列或多列上
索引排列顺序可选升序(ASC)和降序(DESC)两种,默认升序
可用UNIQUE指明2此索引的每一个索引值只对应 唯一的数据记录
可用CLUSTER指明建立的索引是否聚簇索引
删除索引
索引能一定程度上提高查询效率,但如果数据的增、删、改较频繁,系统需话费过多时间来维护索引,从而降低查询效率,所以不必要的索引需要及时删掉
3.3.4 数据字典
定义:
数据字典是关系数据库管理系统内部的一组系统表。
作用:
它记录了数据库中所用的定义信息,包括:
- 关系模式定义
- 视图定义
- 索引定义
- 完整性约束定义
- 各类用户对数据库的操作权限
- 统计信息等
执行SQL的数据定义语句时,实际上就是在更新数据字典表中的相应信息。
进行查询优化和查询处理时,数据字典中的信息是其重要依据。比如,索引
3.4 数据查询
谓词顺序:
select——from——where——group by——[ having ]——order by
3.4.1 单表查询
选择表中的若干列
选择表中的全部或部分列即关系代数的投影运算。
select子句的表达式不仅可以是属性列,也可以是表达式
选择表中的若干元组
可用Distinct来消除重复的行,为指定该关键词,则默认ALL,保留重复的行
使用where子句来实现查询满足条件的元组
考虑加索引加快查询速度,同时注意在由索引的情况下,查询优化器不使用索引来查询的情况
确定范围:between…and和not between…and
确定集合:in和not in+集合
字符匹配:谓词like和not like,通配符%和_
%代表任意长度(长度可为0)字符
_代表单个字符
需查询字符串本身含通配符的情况,使用escape + ‘转义字符’来指定转义字符,从而使用转义字符将通配符转义为普通字符
涉及空值: is null或is not null,is不能用等号替代
多重条件查询: 使用and和or连接多个条件,and优先级高于or,但可以用括号该表优先级
order by子句
可使用ASC和DESC指定升序还是降序
聚集函数
常用聚集函数:count、sum、avg、max、min等,用法与以下count第二种类似
count(*) 统计元组个数
count([distinct|all] <列名>)统计一列中值的个数
聚集函数会跳过空值,只处理非空值
聚集函数只能用于select子句和group by中的having子句,不能出现在where子句中
group by子句
group by子句将按其后面的属性列进行分组,该属性类的相等的元组作为一组。通常会在每组中作用具体函数(如统计每组的数量、总和等)
如果group by子句带有having+条件表达式短语,则只有满足条件的短语才能输出
having短语作用的对象为执行group by后的每个组
3.4.2 连接查询
同时涉及两个以上表的查询,称之为连接查询。
连接查询是关系数据库中最主要的查询,主要包括:
- 等值连接查询
- 自然连接查询
- 非等值连接查询
以上三个的区别,第二章有介绍
自身连接查询
自己跟自己连接
外连接查询
太常见,随处可查,这里就不介绍了
复合条件连接查询
where 子句中的条件,包含多个筛选条件(表间的)
注意:
select … from 多个表 where 条件等价与inner join内连接
3.4.3 嵌套查询
一个select-from-where语句称为一个查询块。
将一个查询块嵌套在另一个查询块的where子句或者having短语的条件中称为嵌套查询。
嵌套查询中外层查询块称为外层查询或父查询,内层查询块称为内层查询或子查询。
嵌套查询分类:
根据子查询的查询条件是否依赖父查询可分为:
子查询的查询条件不依赖与父查询,这类子查询称为不相关子查询;
如果子查询的查询条件依赖于父查询,则称为相关子查询;整个查询语句称为相关嵌套查询
根据谓词分类:
带有in谓词的子查询
带比较运算符的子查询
需明确知道内层子查询返回的是单值
带有ANY或者ALL谓词的子查询
子查询返回多值时,使用比较运算符必须要添加ANY或者ALL谓词
ANY表示大于子查询中的某个值
ALL表示大于子查询中的所有值
带有EXISTS谓词的子查询
带有EXISTS谓词的子查询不返回任何数据,只返回true或者false
内层查询结果非空,返回true;反之,返回false
3.4.4 集合查询
select语句的查询结果是元组的集合,所以多个select语句的结果可进行集合操作。
集合操作主要包括:
- 并操作union
- 系统自动去掉重复的元组
- 保留重复元组,使用union all 交操作intersect
- 差操作except
参加集合操作的各查询结果的列数必须相同;对应项的数据类型也必须相同。
3.4.5 基于派生表的查询
当子查询出现在FROM子句中,这时子查询生成的临时派生表成为主查询的查询对象。
必须为派生表指定一个别名。对于基本表,别名时可选择项。
3.5 数据更新
分类:
插入数据insert
into子句没有指明任何属性列名时,values新插入的元组必须在每个属性列均有值
可以插入子查询结果,从而插入批量数据,此时省略values谓词
修改数据update
删除数据delete
3.6 空值的处理
空值出现的几种情况:
- 该属性应该有一个值,但是目前不知道它的具体值;如年龄,空值表示不知道
- 该属性不应该有值;如,缺考学生的成绩为空
- 由于某种原因不便于填写;如,电话号码
空值的的产生:
insert语句没有赋值的属性为null
update语句可以将某属性set为null
空值的判断:
is null 和is not null
空值的约束条件:
属性定义中的not null约束条件
unique限制的属性和码属性(主键、外键)不能为空值
空值的运算
空值与另一个值的算术运算的结果为空值
比较运算的结果为UNKONWN;
有了UNKONWN之后,传统的二值逻辑,扩展为三值逻辑;
UNKONWN在与true的逻辑运算中,作用相当于false
UNKONWN在与ffalse的逻辑运算中,作用相当于true
UNKONWN的非逻辑运算,仍然是UNKONWN
含UNKONWN的条件出现在where和having中时,仍然只有true的元组能选出来
3.7 视图
3.7.1 定义视图
视图是一个虚表,由基本表导出。数据库只存放视图定义,而视图对应的数据仍存放在基本表中。
视图定义挺少见的,稍微看一下语法吧;
语法:
create view <视图名> [(<列名>,。。。)]
as <子查询>
[with check option]
其实从语法也能看出来,就是将子查询贴上视图名作为一个虚表保存起来。(创建过程并不执行子查询,只是将定义保存进数据字典)
with check option 表示对视图的增、改、删操作时,要保证修改的行满足视图的定义中的谓词条件。
组成视图的属性列名,要么全部忽略,要么全部指定。
如果忽略,则隐含为子查询中的个字段。
但以下三种情况必须明确指定组成视图的所有列名:
某个目标列不是单纯的属性名,而是聚集函数或列表达式
多表连接时选出的几个同名列作为视图的字段(需重命名区分)
需要在视图中为某个列启用新的更合适的名字
视图分类:
行列子集视图
由单个基本表导出,并去掉基本掉的某些行和某些列,但保留了主码
带虚拟列的视图(带表达式的视图)
子查询select子句中,带有表达式
分组视图
子查询中带有聚集函数和group by子句
3.7.2 视图的查询、更新
视图消解:
从数据字典取出视图定义,把定义中的子查询和用户的查询结合起来,转换为等价的对基本表的查询,然后执行。这一过程称为视图消解
对视图的查询、更新(增、改、删)都是通过视图消解,转化为对基本表的操作的。
需要注意有些视图是不允许更新的(DB2规定):
两个以上基本表导出,不允许更新
若是图的字段来自表达式或常数,不允许insert和update,允许delete
视图定义含group by子句,不允许更新
视图定义含distinct短语,不允许更新
视图定义含嵌套查询,且内存查询的from子句中的表也是导出该视图的基本表,则该视图不允许更新
3.7.3 视图的作用
作用:
- 视图能够简化用户的操作
- 视图定义可能很复杂,但是用户不需要管虚表数据怎么来的,只需对虚表作简单查询
- 视图使用户能以多种角度看待同一数据
- 视图对重构数据库提供了一定程度的逻辑独立性 基本表添加了新的关系,对定义在视图上的程序没有影响
- 视图能够对机密数据提供安全保护
- 对不同用户定义不同地视图,其实就是对基本表针对不同用户添加了不同的查询条件
- 适当利用视图可以更清晰地表达查询