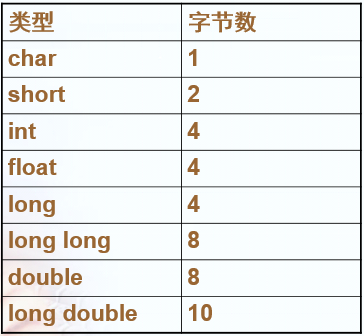
在x86/Linux工作站上,以下两个结构的size分别是20和16,为什么不一样?
typedef struct _a{ typedef struct _b{
char c1; char c1;
long i; char c2;
char c2; longi;
double f; double f;
}a; }b;
前者按照8字节对齐,后者按照4字节对齐


struct s1{
short a;
long b;
};
struct s2{
char c;
s1 d;
long long e;
};
#pragma pack() /*取消指定对齐,恢复缺省对齐*/
问题:
2.s2的c后面空了几个字节接着是d?
分析:
S1中,成员a是2字节默认按2字节对齐,指定对齐参数为8,这两个值中取2,a按2字节对齐;同理,成员b是4个字节,按4字节对齐,所以sizeof(S1)应该为8;
a b
S1的内存布局:11**,1111
S2 中,c按1字节对齐,而d 是个结构,它是8个字节,它按什么对齐呢?
对于结构来说,它的默认对齐方式就是它的所有成员使用的有效对齐值中最大的一个,S1的就是4.所以,成员d就是按4字节对齐.成员e是8个字节,它是默认按8字节对齐,和指定的一样,所以它对到8字节的边界上,这时,已经使用了12个字节了,所以添加了4个字节的空,从第16个字节开始放置成员e。这样一共使用了24个字节。
c S1.a S1.b d
S2的内存布局:1***,11**,1111,****11111111