这篇博客主要介绍C++字节对齐的方式
什么是字节对齐
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
为什么要字节对齐
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问 一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐.其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对 数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。
字节对齐的准则
字节对齐的概念与规则
四个基本概念
对于char型数据,其自身对齐值为1,对于short型为2,对于int,float类型,其自身对齐值为4,对于double型,其自身对齐值为8,单位字节。
2.结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
3.指定对齐值:#pragma pack (value)时的指定对齐值value。
4.数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
对齐规则
上面说的这些,百度百科上都有,而我要写的是,怎么理解上面这些东西
栗子1、结构体变量的首地址能够被其最宽基本类型成员的大小所整除
struct A
{
double a;
};
A* a=new A();
在我的机器上,a的地址上0x26e1200,可以整除double的大小8,符合准则1、结构体变量的首地址能够被其最宽基本类型成员的大小所整除
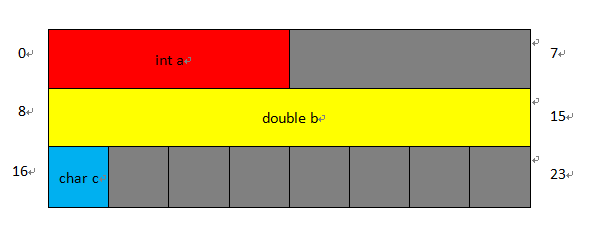
栗子2、怎么计算只含基本类型成员的结构体的大小
struct A
{
int a;
double b;
char c;
};
如果不考虑字节对齐,那么显然结构体A的大小为4+8+1=13。如果考虑字节对齐,我们只需要记住两点,第一、每个成员在结构体里的偏移都是其自身大小的整数倍,第二、结构体的总大小为最宽基本类型成员大小的整数倍
对于a,其大小为4,那么可以放在偏移为0的地方,0是4的0倍,对于b,其大小为8,可以放在偏移为8的地方,8是8的1倍,对于c可以放在偏移为16的地方,9是1的9倍,现在,结构体的大小为17,然而最宽基本类型成员是b,其大小是8,比17大的8的倍数的数字是24,所以整个结构体的大小为24
上面的栗子的布局情况像这样,灰色代表编译器为了字节对齐而填充的字节
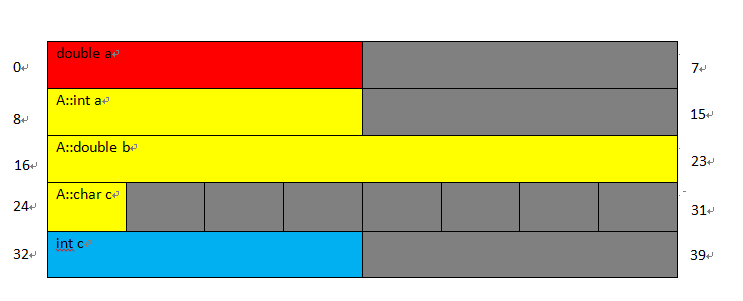
栗子3、怎么计算含结构体的结构体的大小
struct A
{
int a;
double b;
char c;
};
struct B
{
double a;
A b;
int c;
};
对于含有结构体的结构体,麻烦在于我们不知道结构体怎么算对齐值,因为偏移是根据大小来确定的,结构体的大小是根据其自己最大基本类型成员的大小来决定的。当然,我说的不是结构体真正的大小,而是结构体计算大小,也就是上面说的对齐值。基本类型成员的对齐值就是自身大小,结构体的对齐值是自己最大基本类型成员的大小。所以在这里,a的对齐值是8,所以它应该放在偏移为0的地方,0是8的0倍,结构体b应该放在偏移为8的地方,8是8的1倍,c应该放在32的地方,32是1的32倍,现在,结构体的大小为33,然而最宽的成员大小既是a,也是结构体b,大小都是8,所以比33大的8的倍数的数字是40,整个结构体的大小为40
上面的栗子的布局情况像这样,灰色代表编译器为了字节对齐而填充的字节
栗子4、怎么计算含有指定对齐值的结构体的大小
我们可以通过#pragma pack (value)来指定我们想要的对齐值,结构体真正的对齐值是我们指定对齐值和结构体本身对齐值较小的一个
#pragma pack(4)
struct A
{
int a;
double b;
char c;
};
我们已经在栗子1中见过这个结构体,这个结构体的对齐值是其自身最大的基本类型成员,也就是b,大小为8,可我们指定的对齐的大小为4,所以这个结构的有效对齐值为4
a应该放在偏移为0的地方,0是4的0倍,b应该放在偏移为4的地方,8是4的2倍,c应该放在偏移为12的地方,12是1的12倍,现在,结构体的大小为13,比13大的4的倍数为16,所以整个结构体的大小为16
上面的栗子的布局情况像这样,灰色代表编译器为了字节对齐而填充的字节
