原文下载:https://download.csdn.net/download/qq_29675093/10950893
虽然是2012年的论文,但是无论从理论深度还是实用价值都不足。动作限定很死,左右离散二值。从论文内容上看,也要怀疑作者是否真的实现了仿真学习过程。因为10e8的状态空间如何处理文中并没有提到,式(13)的奖励设计也很可笑,速度小于零的要求毫无必要。我是从孙景亮等: 《基于自适应动态规划的导弹制导律研究综述》综述文章中看到这篇文章的,该综述也是唯一一篇引用此文的。国内研究者写综述只求全不求精的现象可见一斑。
Dongjin Lee and Hyochoong Bang
摘要。 本文提出了强化学习技术,以实现飞机在参与过程中的规避策略。 简化的点质量模型用于描述飞机和导弹的运动方程。 导弹遵循纯比例导引制导法(PPNG)来攻击飞机。 提出了一种强化学习形式的Q学习算法来学习规避动作。 通过数值模拟分析了所提出方法的性能。 结果表明,该飞机通过强化学习与bang-bang型动作剖面正确地避开了导弹。
1 引言
许多研究人员使用差分博弈分析或最优控制技术研究了导弹逃逸问题。通过固定导弹制导律可以实现单侧最优控制问题的制定。 Ben-Asher和Cliff通过假设线性化运动学以恒定速度研究了规避策略[1]。 Imado和Miwa在[2]中研究了更完整的导弹逃逸问题模型。 Ong和Pierson将逃逸问题视为近似参数优化问题[3]。从以前的工作来看,为了解决最优控制问题,我们需要设置一个性能指标,例如最接近时的相对距离并将其最大化[3]。然而,准确的规避策略是避免相互冲突的策略。换句话说,没有必要最大化最终的未命中距离以实现导弹逃避。此外,优化方法需要大量的计算时间才能找到最佳解,因此,最优解难以实现为实时制导律[10]。为了克服这些问题,我们建议采用强化学习技术来推导智能回避动作。在学习融合之后,飞机可以根据学习的策略轻松利用规避策略。
在这项研究中,我们采用一种简化的点质量模型,以恒定速度描述飞机和导弹动力学。我们考虑平面接合并假设导弹遵循纯比例导航制导法来捕获具有恒定导航增益的飞机。引入Q-learning [4]作为强化学习算法,以获得最大化奖励期望的最优策略。最后,构建数值模拟以使用各种拦截场景来评估所提出的方法。
2 问题制定
2.1 Evader运动方程
逃避的飞机运动方程可以用简化的四阶点质量模型来表示。 平面上的控制方程是
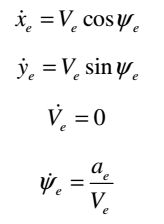 (1)
(1)
其中是飞机的状态,分别是水平坐标,航向角,速度,横向加速度指令。 在这项研究中,我们假设
是恒定的,并且飞机横向加速度指令受到限制
![]() (2)
(2)
其中是重力加速度,
是最大重力载荷。 下标m和e分别代表导弹和逃避的飞机。

2.2导弹运动方程
本研究中使用的导弹动力学模型是简化的四阶点质量模型。运动方程是
 (3)
(3)
其中是导弹的状态,分别是水平坐标,航向角,速度,横向加速度指令。我们还假设
是恒定的,导弹横向加速度指令受到限制
![]() (4)
(4)
其中 是最大重力负荷。导弹横向加速度指令由纯比例导航制导律产生。在许多目前可操作的战术制导导弹中,已经实施了纯比例导引(PPN)用于末制导。由于PPN制导律不需要前向速度变化,因此对于空气动力学控制的追踪者而言比真正的比例导航(TPN)制导法更为合适[6]。
![]() (5)
(5)
其中N = 3是导航常数,是由(6)给出的视线(LOS)旋转速率。
2.3拦截运动方程
我们可以考虑截取运动方程如下
 (6)
(6)
其中 分别是相对距离,闭合速度,LOS角度,LOS转速。 我们可以使用相对于飞机的LOS角来引入拦截状态向量
。
![]() (7)
(7)
3强化学习
3.1 Q学习
Q-learning是一种强化学习算法的最新形式,它不需要其环境模型,可以在线使用[5]。 其最简单的形式,一步式Q学习,定义为
![]() (8)
(8)
其中r,α,γ分别是奖励信号,学习率,折扣率。 在本研究中,我们设定学习率α= 0.5,折扣率γ= 0.99。 动作值函数Q(s,a)表示在策略τ下的状态s下采取动作a时的预期返回,如下所述
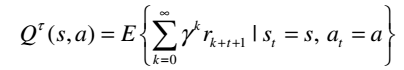 (9)
(9)
并且可以通过导出最优策略τ*
 (10)
(10)
 (11)
(11)
3.2 状态和动作空间
在将Q学习应用于连续逃避导弹问题之前,有必要定义要学习的状态和动作,并将状态和动作空间划分为有限数量的空间。 拦截状态和飞机横向加速度分别分配给状态和动作
。 动作空间分为两段A = { - 6g,6g},代表最大的左右转弯。 状态空间中有
个状态,每个拦截变量分为100个状态。 状态空间受到限制
 (12)
(12)
3.3 奖励函数
为了完成导弹捕获的逃脱,我们需要正确定义奖励函数。 我们设计最简单的奖励函数如下
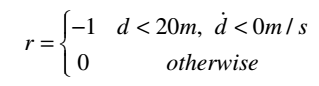 (13)
(13)
其中被认为是逃避失败的条件。 基于该奖励函数,训练动作值函数并且动作值收敛于失败的期望。
4仿真
4.1学习阶段
飞机基于当前动作值函数采取动作,并在整个学习阶段同时更新功能。注意,奖励信号在终端状态下给出并在初始状态传播到动作值函数。如果在所有状态满足(14)的标准,则学习结束。
![]() (14)
(14)

其中是小的正值。在学习阶段和模拟过程中,系统动力学使用欧拉积分进行积分。此后,模拟三种情景来评估学习策略。表1列出了所有情景的初始条件。
4.2场景#1
在场景#1中,导弹的初始航向角与LOS一致。仿真结果如图2和图3所示。从结果中我们可以看出飞机实现了逃避。最后时间的未命中距离是。


我们还可以发现,规避演习是在最后时间进行的。
4.3场景#2
在场景#2中,导弹的初始航向角偏离LOS线+ 10度。结果如图4和图5所示。完成了对导弹的逃避,最终时的未命中距离为r(t f)= 373.161m。


拦截状态的历史明显不同于以前的情景。飞机的轨迹与情景#1中的轨迹类似,导弹横向加速度达到极限。
4.4场景#3
在场景#3中,导弹的初始航向角偏离LOS线-10deg。结果如图6和图7所示。在这种情况下,飞机无法找到任何规避策略。这意味着条件是导弹捕获集的子部分。


5结论
在本文中,我们考虑了躲避导弹问题,并建议将Q学习作为强化学习算法,以便找到智能规避机动。在学习融合后,我们构建了数值模拟来评估所提出的方法。仿真结果表明,实现了规避策略,无需优化计算即可应用于所有学习案例。