前言
1月时,利用周末的闲暇时间,看了一个b站一位讲师讲解的基础爬虫案例,记载一下。
因种种问题,直到今天才基本完成这个小案例的学习,并且在后续实际操作时,发现与视频内容有一些偏差了,估计是网站做了一些反爬虫设定,但是整体的文本爬虫流程是这样的。
目标是下载 http://www.jingcaiyuedu.com/book/15205.html 网站的小说,名称为 《无上真仙》 。 (os:名字中二hhh
正题
我们使用浏览器看小说的时候,流程基本如下:
浏览器输入网址 → 浏览器向服务器发送 http 请求 → 服务器收到请求后返回 http 响应 → 浏览器解析渲染后展示出来
python 3 中,向服务器发起请求需要使用到第三方的库 requests ,没有安装的话需要安装,在 cmd 中执行以下命令。
pip install requests
安装完后可以导入并开始写代码了。
第一步,先发送请求,获取 http 相应
# 爬虫基础练习01 -- from 讲师 --- 心蓝 # --------------下载一部全免费的小说------------------ import requests # 第一,指定 url,小说《无上真仙》 url = 'http://www.jingcaiyuedu.com/book/15205.html' response = requests.get(url) # 返回 http response类型 # 设置编码,UTF-8 response.encoding = 'utf-8' # 输出为 text 文本 print(response.text)
这个时候,看看打印出来的结果
<html> <head><title>403 Forbidden</title></head> <body bgcolor="white"> <center><h1>403 Forbidden</h1></center> <hr><center>nginx/1.10.2</center> </body> </html>
返回的是一个 html 格式的文本,但是其中内容被屏蔽了 ,返回的是 403 Forbidden, 我上网查资料,发现可以通过添加 headers 来解决这个问题。
通过 chrome 可以获得我的 headers ,点开页面后, F12 进入开发者模式,在 Network 中,主 html 中,有一行信息为 User-Agent ,其中的信息就是我们需要的。
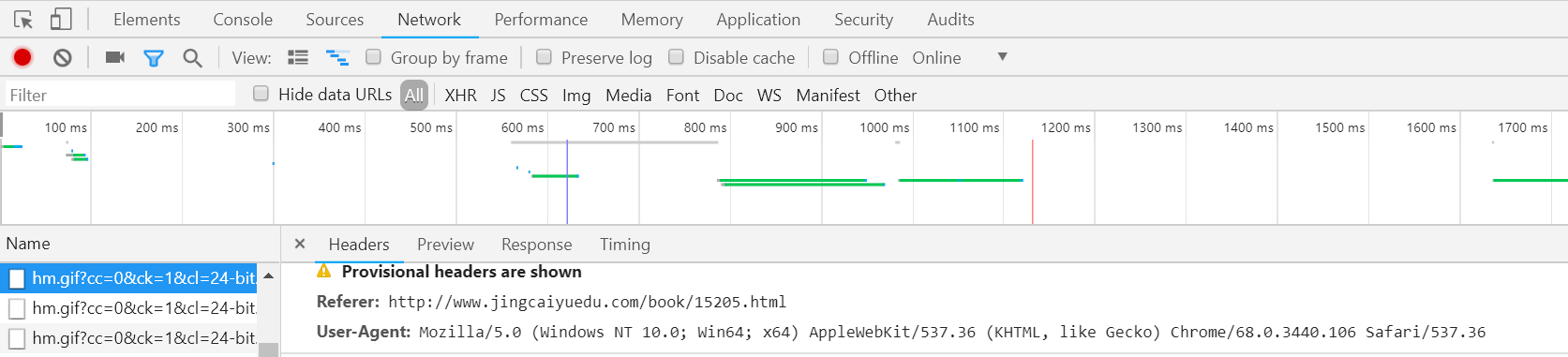
修改后的代码
# 爬虫基础练习01 -- from 讲师 --- 心蓝 # --------------下载一部全免费的小说------------------ import requests # 第一,指定 url,小说《无上真仙》 url = 'http://www.jingcaiyuedu.com/book/15205.html' # 添加 headers,模拟本机电脑来访问。 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} # 返回 http response类型 response = requests.get(url,headers = headers) # 设置编码,UTF-8 response.encoding = 'utf-8' # 输出为 text 文本 print(response.text)
修改后,获取的 html 中就包含了章节等有效信息,如
<dd class="col-md-3"> <a href="/book/15205/255.html">第255章 纷纷突破</a> </dd> <dd class="col-md-3"> <a href="/book/15205/256.html">第256章 神秘店小二</a> </dd>
剩下的,我们需要做的,就是获取每一掌的 url 链接与 章节名称,循环发出请求,获取 html 消息,并将每一章节的信息进行清洗,然后持久化到文本中,剩下的代码如下。
# 爬虫基础练习01 -- from 讲师 --- 心蓝 # --------------下载一部全免费的小说------------------ import requests import re # 第一,指定 url,小说《无上真仙》 url = 'http://www.jingcaiyuedu.com/book/15205.html' # 添加 headers,模拟本机电脑来访问。 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} # 返回 http response类型 response = requests.get(url,headers = headers) # 设置编码,UTF-8 response.encoding = 'utf-8' # 目标小说主页源码 ,输出为 text 文本 html = response.text # 获取小说的名称 title = re.findall(r'<meta property="og:title" content="(.*?)"/>', html)[0] # print(title) # 新建文本,保存小说 f = open('%s.txt' %title,'w',encoding='utf-8') # 获取每一章节信息,需要章节与url # 使用正则表达式来匹配,选取第一章前的唯一标志,如 <div class="panel-heading"> ,中间 .*? 匹配所有对象,最后以 </dl> 结尾,选区中间的匹配部分,再转成列表的形式赋予dl # 在视频学习中,如果 html 返回的结果已经有格式化了,包含了空格或者回车类似的特殊符号无法匹配,需要在findall中加入第三个参数,re.S 来进行匹配 dl = re.findall(r'<div class="panel-heading">.*?</dl>', html)[0] # 从 dl 中,再次利用正则表达式,获取每一章的 url 与 标题 chapter_info_list = re.findall(r'href="(.*?)">(.*?)</a> </dd>', dl) # 循环每一个章节,分别下载内容 for chapter_info in chapter_info_list: chapter_url,chapter_title = chapter_info chapter_url = "http://www.jingcaiyuedu.com%s" % chapter_url # 下载内容 chapter_response = requests.get(chapter_url,headers = headers) chapter_response.encoding = 'utf-8' chapter_html = chapter_response.text # 提取章节内容 chapter_content = re.findall(r'<div class="panel-body" id="htmlContent">(.*?)</div>',chapter_html) # 很尴尬,获取不到小说内容,爬到的 html 显示正文正在转码中。 # print(chapter_html) # exit() # 继续写完剩下的代码,没有实践了 chapter_content = chapter_content.replace(' ','') chapter_content = chapter_content.replace(' p;','') chapter_content = chapter_content.replace('<br/>','') # 持久化 f.write(chapter_title) f.write(chapter_content) # 每一章换一行 f.write('\n') print(chapter_url)
之所以,结束的有点匆忙,是因为自己实操的时候,发现获取不到小说内容,但是整个爬小说的流程、逻辑是对的,具体转码中这个问题需要进一步处理,暂时还没找到解决办法,如果找到办法后,再更新这个博文~~。