Python爬虫01-基本原理
文章目录
1.基本原理
爬虫:请求网站并提取数据的自动化程序
1.1 爬虫的基本流程
- 发起请求
- 通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器相应
- 获取相应内容
- 如果服务器正常相应,会得到一个Response,Response的内容便是所要获得的页面内容,类型可能有HTML、Json字符串、二进制数据(如图片、视频)等类型
- 解析内容
- 得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以直接转为Json对象解析。可能是二进制数据,可以做保存或进一步的处理
- 保存数据
- 保存形式多样,可以存为文本,也可以保存至数据库,或者保存位特定格式的文件
1.2 Request与Response
- 浏览器发送消息给该网址所在的服务器,这个过程叫HTTP Request
- 服务器收到浏览器发送的消息后,能够根据浏览器发送的消息的内容做出相应的处理,然后把消息回传给浏览器,这个过程叫HTTP Response
- 浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示
1.2.1 Request中包含的内容
Request中包含 请求方式 、请求URL、请求头、请求体
1. 请求方式
- GET
- 要请求的数据都包含在网址中
- 向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据
- POST
- 请求的数据存放在头部
- 向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有
- HEAD
- 与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)
- PUT
- 向指定资源位置上传其最新内容
- DELETE
- 请求服务器删除Request-URI所标识的资源
- OPTIONS
- 这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用’*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
等

2. 请求URL
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的基本格式 = 协议://主机地址/路径 http://202.108.22.5/img/bdlogo.gif
{kind=link}
URL的格式由三个部分组成:
- 第一部分:协议。不同的协议,代表着不同的资源查找方式、资源传输方式。如:HTTP:// 表示采用HTTP协议,
- 第二部分:存有该资源的主机IP地址(有时也包括端口号)。
- 第三部分:主机资源的具体地址。如目录和文件名等。
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据。
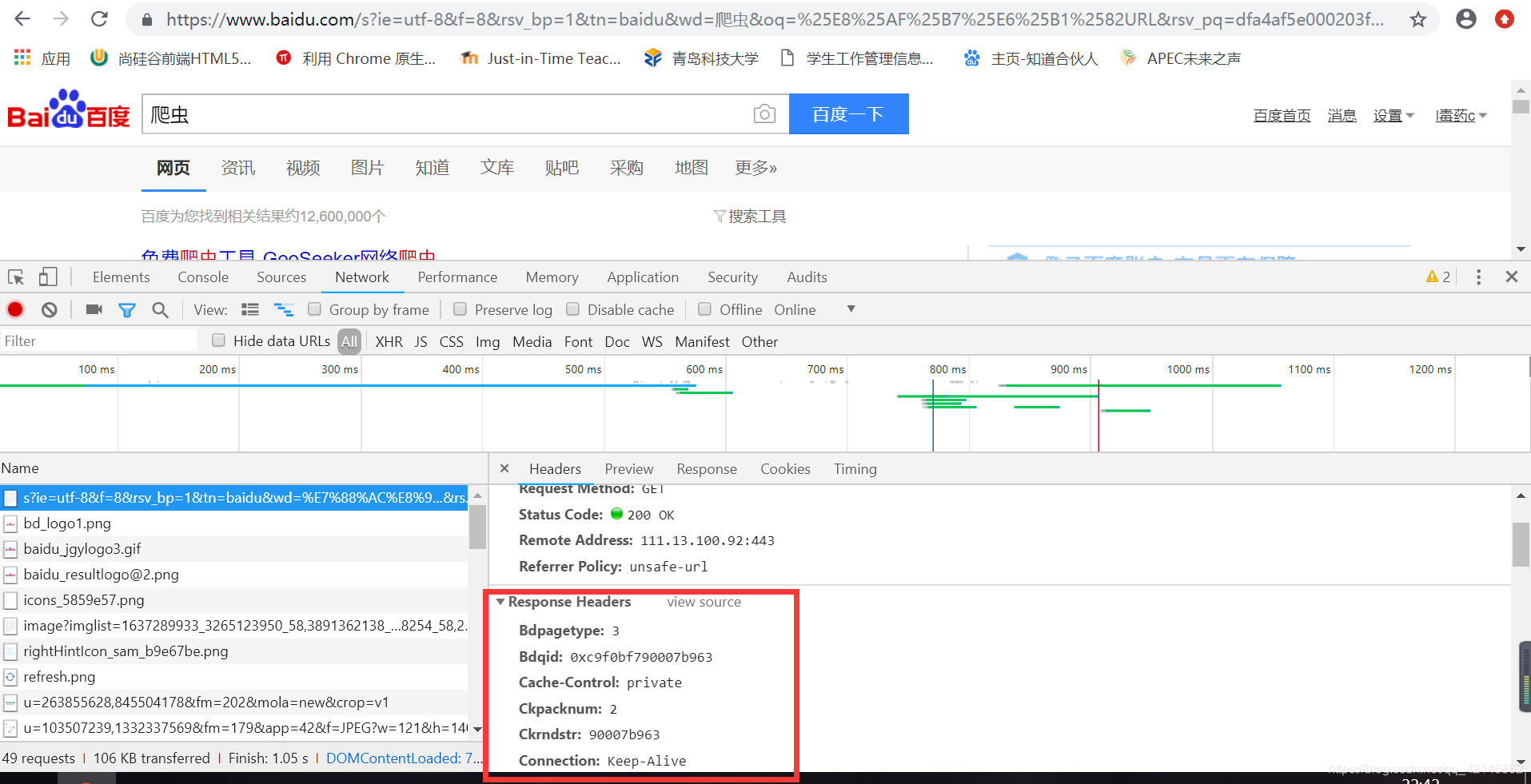
3. 请求头
包含请求时的头部信息,如User-Agent,Host,Cookies等信息。
相当于请求的一些配置信息,通过这些信息来告诉服务器我们要请求的文档类型、要携带的Cookie、浏览器类型等,然后服务器来判断这些是什么配置信息,并判断这些请求是否是合法的,然后根据解析结果返回相应的网页内容
4. 请求体
请求时额外携带的数据。如:表单提交时的表单数据
1.2.2 Response中包含的内容
Response中包含 响应状态、响应头、响应体
1. 响应状态
有多种响应状态。
- 200代表成功
- 301跳转
- 404找不到页面
- 502服务器错误
等
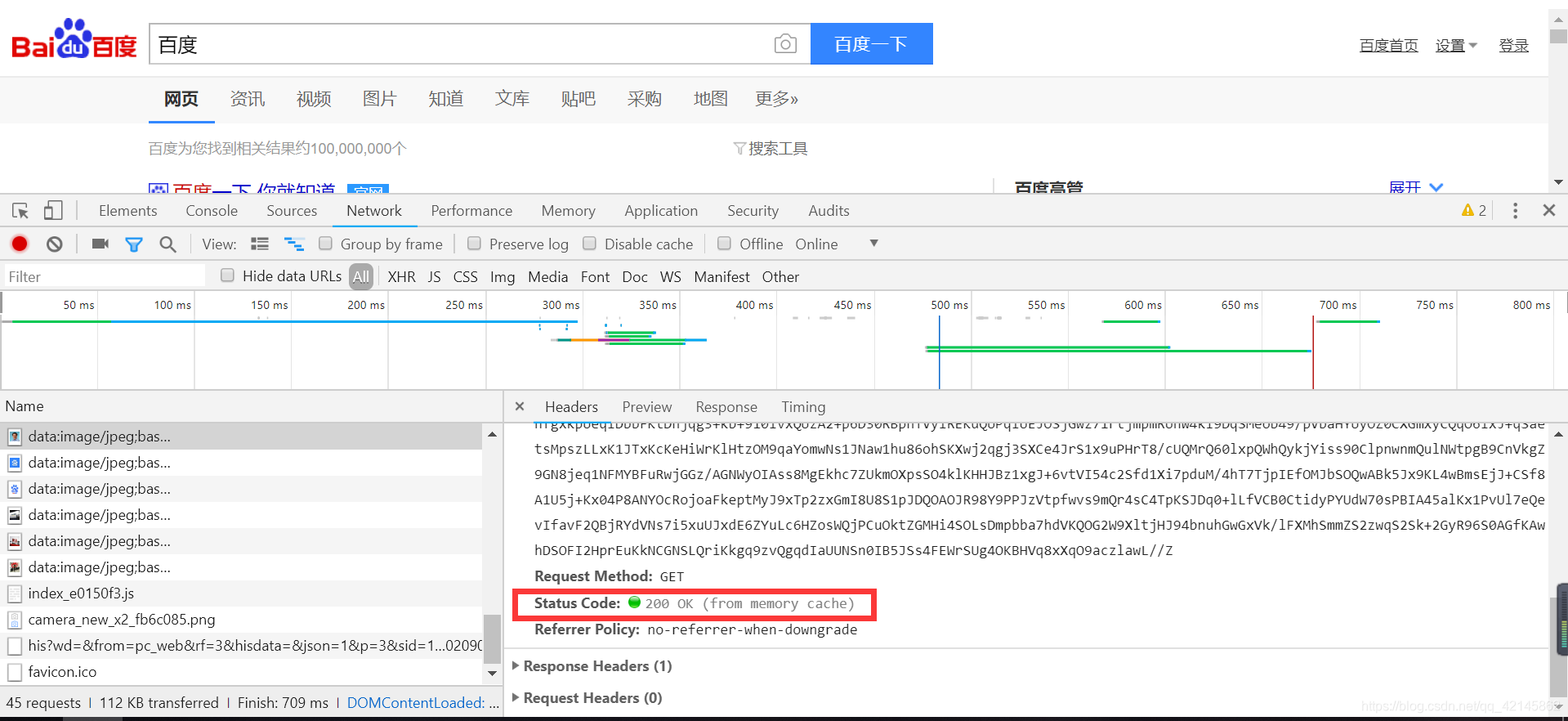
2. 响应头
如内容类型、内容长度、服务器信息、设置Cookie等等
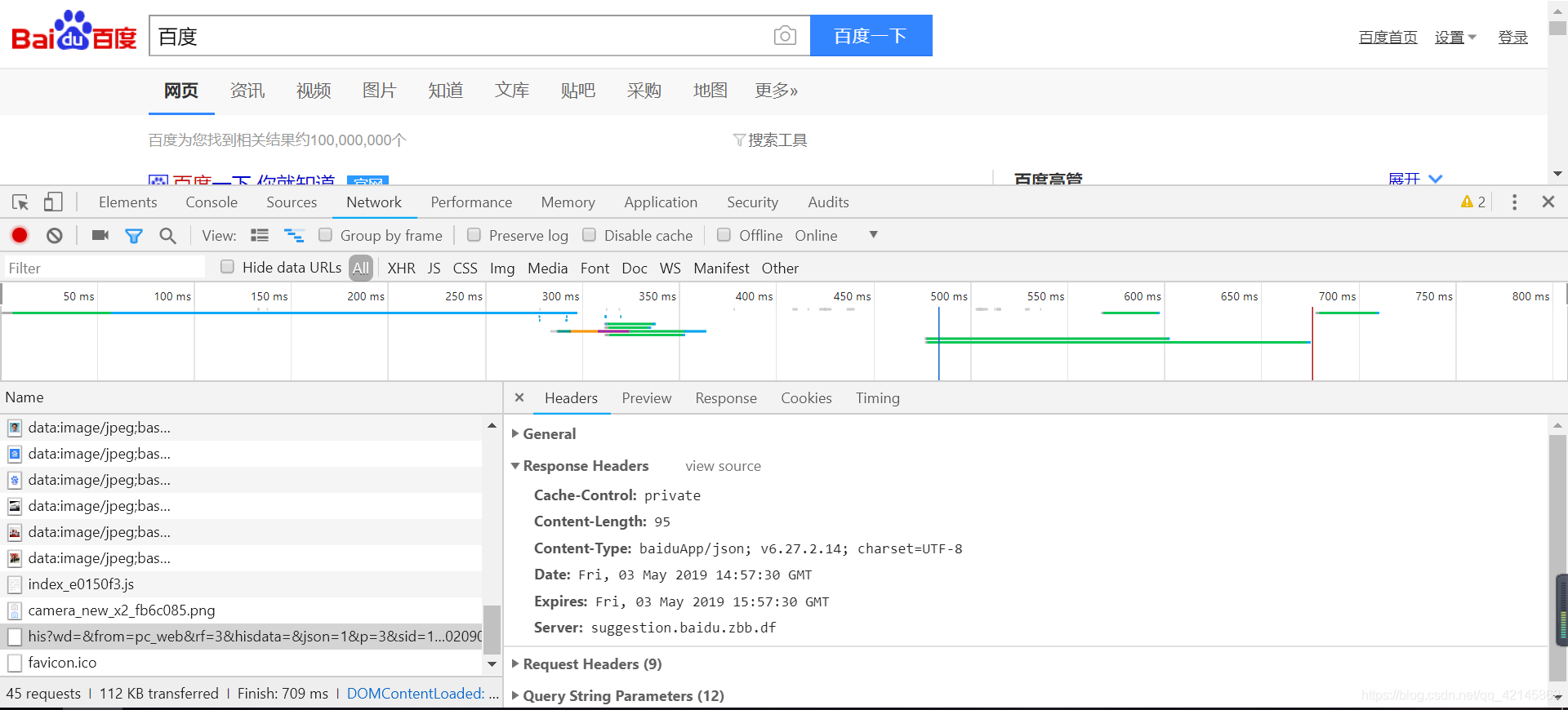
3. 响应体
最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等
1.3 能抓怎样的数据
- 网页文本:如HTML文档,Json格式文本等
- 图片:获取到的是二进制文件,保存为图片格式
- 视频:获取到的是二进制文件,保存为视频格式
- 其它:只要是能请求到的,都能获取
1.4 解析方式
- 直接处理:适用于网页本身比较简单时的情况
- Json解析:有些网页的数据是通过Ajax来加载的,这种通常返回的格式是Json字符串,在这里就需要进行Json解析转换为Json对象
- 正则表达式:就是一个规则字符串,把HTML中相应的文本提取出来
- BeautifulSoup解析库:相对于正则表达式来说提取更加容易一些
- PyQuery解析库
- XPath解析库
1.5 为何抓到的数据与再浏览器中看到的数据不同
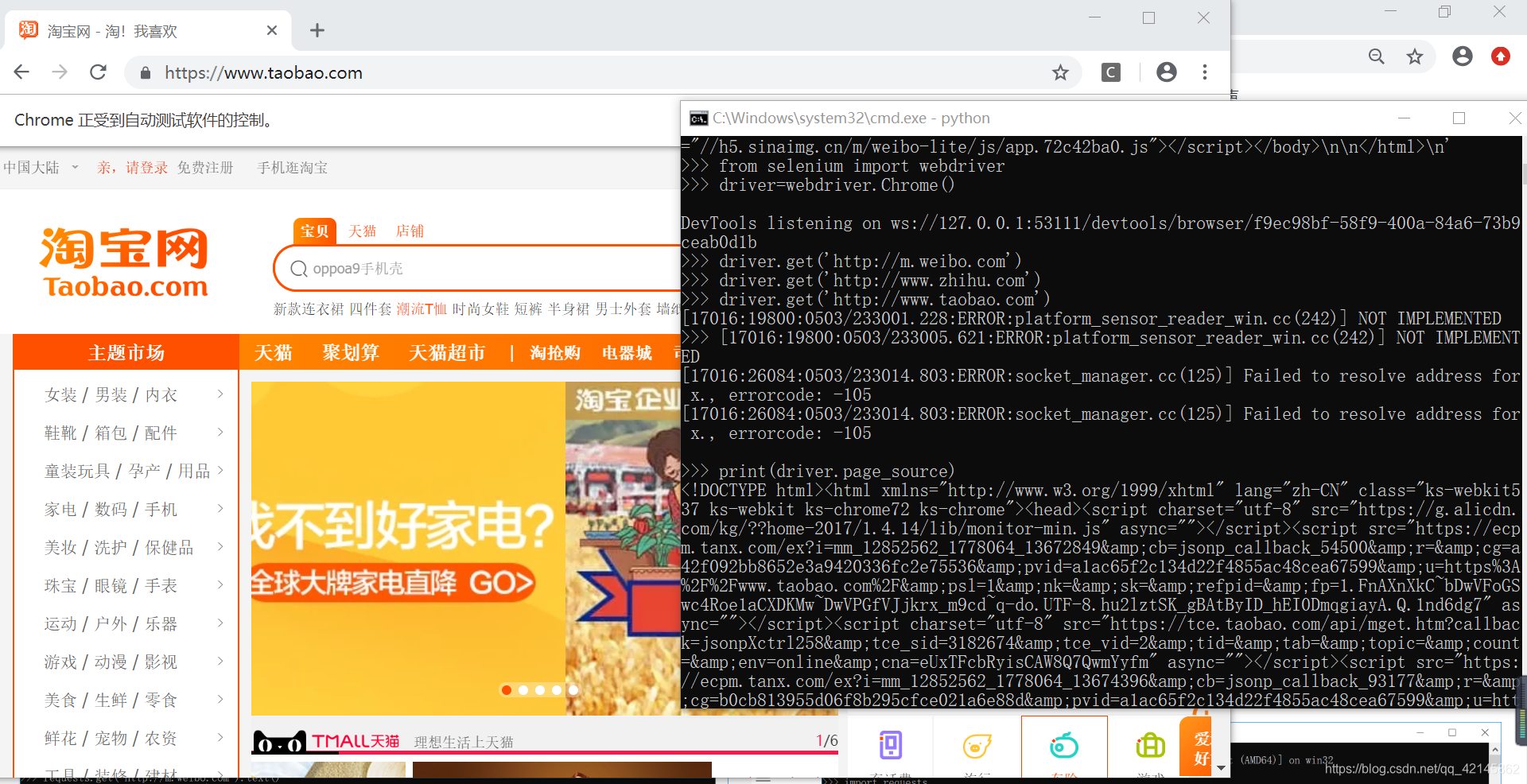
例如:新浪微博查看源代码,其中并没有网页上那么多的文字信息
原因:出现这种情况是因为,很多网站中的数据都是通过js,ajax动态加载的,所以直接通过get请求获取的页面和浏览器显示的不同。
例:用该方法得到的并不是完整的源代码
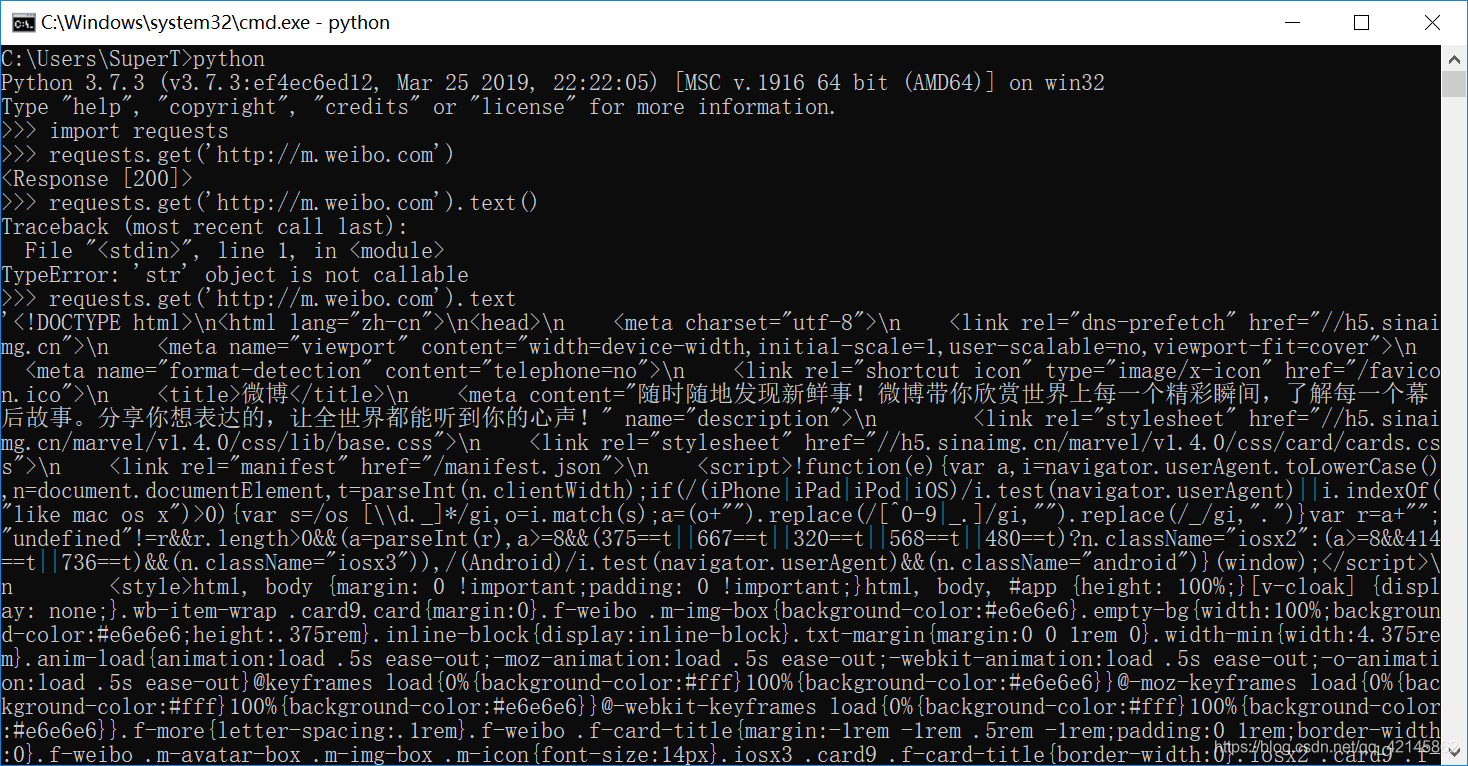
怎样解决JavaScript渲染的问题:
- 分析Ajax请求:其返回结果是Json字符串
- 用Selenium/ WebDriver驱动浏览器来模拟加载一个网页,这实际上是一个用来做自动化测试的工具,它就像一个浏览器一样来加载网页
- Splash库:与Selenium类似,也是模拟JavaScript渲染
用该方法得到的是完整的源代码