内容供自己学习使用,如有错误之处,请大佬们指正,谢谢!
作者:rookiequ
python爬虫基础01
我们可以通过爬虫来从网站上爬取到自己想要的数据。我使用的爬虫是Pycharm+anaconda。想要爬取数据,首先你得python环境和相关的IDE,这里不多赘述。
python爬虫的原理知识
python爬虫的工作原理:

爬虫的四个步骤:
- 获取数据。爬虫会拿到我们要它去爬的网址,像服务器发出请求,获得服务器返回的数据。
- 解析数据。爬虫会将服务器返回的数据转换成人能看懂的样式。
- 筛选数据。爬虫会从返回的数据中筛选出我们需要的特定数据。
- 存储数据。爬虫会根据我们设定的存储方式,将数据保存下来,方便我们进行后一步的操作。

Requests库的使用
Requests库的安装,以管理员的身份使用cmd命令,然后进行安装
pip install requests
初识爬虫,看一个小案例
import requests #引入requests模块
r = requests.get('http://www.baidu.com')
print(r.status_code) #状态码
r.encoding = 'utf-8' #设置编码
print(r.text) #读取的网页信息
HTTP协议:是一种基于“请求和响应”模式的,无状态的应用层协议
url格式:http://host[:port][path],例如http://www.rookiequ.top/admin, url是对应http协议存取资源的Internet路径,一个url对应一个数据资源
- host:合法的主机域名或IP地址
- port:端口号,缺省端口为80
- path:请求资源的路径
Requests提供点的7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础 |
| requests.get() | 获取HTML网页的主要方法,对应于http的get |
| requests.head() | 获取HTML头信息的主要方法,对应于http的head |
| requests.post() | 向HTML网页提交post请求的方法,对应于http的post |
| requests.put() | 向HTML网页提交put请求的方法,对应于http的put |
| requests.patch() | 向HTML网页提交局部修改的请求,对应于http的patch |
| requests.delete() | 向HTML网页提交删除请求,对应于http的delete |
requests.request(method, url, **kwargs)
**kwargs:控制访问的参数,均为可选项
params,data, json, header, cookies, auth, files, timeout , proxies, allow_redirects, stream, verify, cert,
右侧是构成一个向服务器请求的Request对象,左侧返回一个包含服务器资源的Response对象
#调用request方法
r = requests.get(url,params=None,**kwargs)
#url:获取页面的url链接
#params:url中的额外的参数,字典或者字节流格式,可选
#**kwargs:12个控制访问的参数
response的一下属性如下:
| 属性 | 知识点 |
|---|---|
| response.status_code | 检查请求是否成功 |
| response.content | response对象的二进制数据 |
| response.text | response对象的字符串数据 |
| response.encoding | response对象的编码 |
import requests #引入requests模块
r = requests.get('http://www.baidu.com')
print(r.status_code) #http请求的返回状态,200成功,404失败
r.encoding = 'utf-8' #从header中猜测的,响应内容的编码方式
type(r) #查看返回的数据类型 Response对象
print(r.text) #读取的网页信息,响应内容的字符串形式
print(r.content) #响应内容的二进制格式,一般图片音频用二进制
print(r.apparent_encoding) #从内容中分析出来的响应内容编码方式(备选编码方式)
print(r.header) #头信息
注意:r.encoding中,如果header中不存在charset,则认为编码为ISO-8859-1(不能解析中文)
Requests库的异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败,拒接连接等 |
| requests.HttpError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
| response.raise_for_status() | 如果不是200,产生异常requests.HttpError |
爬取网页的通用的代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() #如果状态不是200,引发异常
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常'
if __name__ == '__main__':
url = 'http://www.baidu.com'
print(getHTMLText(url))
robots协议:网站告知网络爬虫哪些内容可以爬取,哪些不能爬取。协议里有很多英文,Allow和Disallow,Allow代表可以被访问,Disallow代表禁止被访问。
实例
import requests
# r = requests.get('http://www.baidu.com')
# print(r.status_code)
# r.encoding = 'utf-8'
# print(r.text)
keyword = 'python'
try:
kv = {
'wd':keyword}
r = requests.get('http://www.baidu.com/s',params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print('爬取失败')
import requests
url = 'https://item.jd.com/2967929.html'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
import requests
url = 'https://www.amazon.cn/gp/product/B01M8L5Z3Y'
try:
kv = {
'user-agent':'Mozilla/5.0'}
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
BeautifulSoup的使用
BeautifulSoup用来解析和提取网页中的数据。
- 解释数据:将服务器返回的HTML源码翻译为我们能看懂的样子
- 提取数据:是指把我们需要的数据从源数据中有针对性地挑选出来
首先进行学习环境准备:
pip install bs4
bs对象 = BeautifulSoup(要解析的文本, 解释器),括号里包含两个参数,第一个必须是字符串类型或者变量,第二个参数是解析器,我们可以用html.parser(这是python的一个内置库,他不是唯一的解析器,可以使用其他的)
举个简单的栗子:
import requests
from bs4 import BeautifulSoup
res = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
soup = BeautifulSoup(res.text,'html.parser')
#把网页解析为BeautifulSoup对象
print(type(soup)) #查看soup的类型
print(soup) # 打印soup
soup的数据类型是<class 'bs4.BeautifulSoup'>,说明soup是一个BeautifulSoup对象。response.text数据类型是<class 'str'>,他们类型不同,打印的内容是一样的。
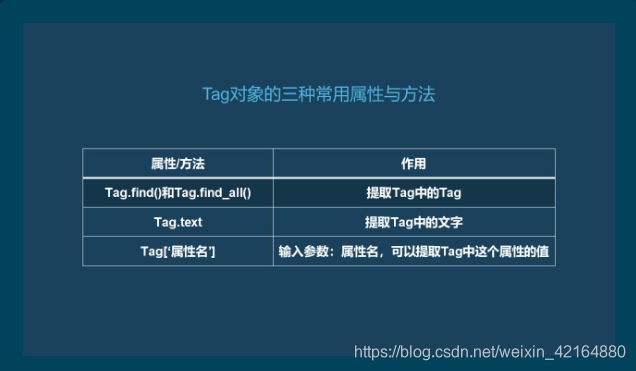
使用BeautifulSoup提取数据,这里就要提到他的两个方法:find()和find_all(),它们可以匹配HTML的标签和属性,把BeautifulSoup对象里符合要求的数据都提取出来。它俩的用法基本是一样的,区别在于,find()只提取首个满足要求的数据,然后返回的是<class 'bs4.element.Tag'>类型,而find_all()提取出的是所有满足要求的数据,然后返回的类型是<class 'bs4.element.ResultSet'>类型,他就是将Tag对象一列表的结构存储在一起了,我们可以把它看为是列表。还有select()方法,后面可以自己了解一下。

上面提到了Tag类型的对象,那么他有哪些属性和方法呢?
import requests
from bs4 import BeautifulSoup
res = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
html = res.text
soup = BeautifulSoup(html,'html.parser')
items = soup.find_all(class_='show-list-item')
for item in items:
title = item.find(class_='desc-title') # 在列表中的每个元素里,匹配属性class_='title'提取出数据
material = item.find(class_='desc-material') #在列表中的每个元素里,匹配属性class_='desc-material'提取出数据
step = item.find(class_='desc-step') #在列表中的每个元素里,匹配属性class_='desc-step'提取出数据
print(title.text,material.text,step.text)
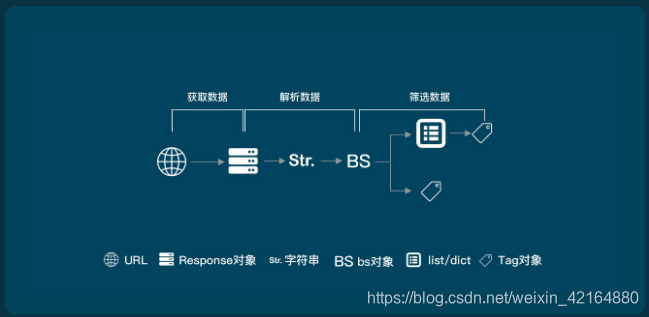
通过一个图形来看一下爬虫的过程:
看一个爬取图片的案例:
import requests
from kkb_tools import open_file
res = requests.get('https://xiaoke.kaikeba.com/example/canteen/images/banner.png')
pic=res.content #二进制
photo = open('banner.jpg','wb')
photo.write(pic)
photo.close()
open_file('banner.jpg')