1. 前言
本文搭建了一个由三节点(master、slave1、slave2)构成的Spark完全分布式集群,并通过Spark分布式计算的一个示例测试集群的正确性。本文将搭建一个支持Yarn的完全分布式环境
2. Spark架构
Spark 使用的是主从架构体系
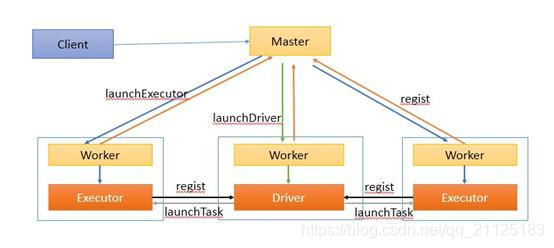
3. Apache Spark环境搭建
需要配置的文件有 slaves spark-env.sh spark-defaults.conf
spark-env.sh
#!/usr/bin/env bash
export JAVA_HOME=/opt/java/jdk1.8.0_151
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.6
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.6/etc/hadoop
export SCALA_HOME=/opt/scala/scala-2.11.12
export SPARK_HOME=/opt/spark/spark-2.3.1-bin-hadoop2.7
export YARN_HOME=/opt/hadoop/hadoop-2.7.6
export YARN_CONF_DIR=//opt/hadoop/hadoop-2.7.6/etc/hadoop
export SPARK_MASTER_IP=node91
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=16
export SPARK_WORKER_MEMORY=16g
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_EXECUTOR_CORES=4
export SPARK_EXECUTOR_MEMORY=4g
#export SPARK_CLASSPATH=/opt/hadoop-lzo/current/hadoop-lzo.jar
#export SPARK_CLASSPATH=$SPARK_CLASSPATH:$CLASSPATH
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node91:9000/user/root/sparkhistory"
# spark standalone模式
# spark_WORKER_CORES spark每个worker进程分配cpu核数
# spark_WORKER_INSTANCES spark每个节点分配多少个worker进程
# spark_WORKER_MEMORY spark每个worker进程占用内存
# spark_EXECUTROR_CORES spark每个executor占用cpu核数
# spark_EXECUTOR_MEMORY spark每个executor占用内存
spark-defaults.conf
# Example:
spark.master spark://node91:7077
spark.eventLog.enabled true
spark.eventLog.compress true
park.eventLog.dir hdfs://node91:9000/user/root/sparkhistory
spark.history.fs.logDirectory hdfs://node91:9000/user/root/sparkhistory
spark.yarn.historyServer.address node91:18080
spark.history.ui.port 18080
spark.ui.port 8099
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
slaves
node23
node24
4. Apache Spark配置高可用性
使用zookeeper配置高可用性 利用StandyBy的Master节点进行备份
1.配置spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=root2:2181,root4:2181,root5:2181"
2.然后再你需要作为备用启动的Master节点上 配置
export SPARK_MASTER_IP=root2 指定Spark Master 的ip地址
3.然后再你需要作为备用启动的Master节点上 启动start-master.sh
5. 启动和关闭 Apache Spark集群
5.1 启动Apache Spark
启动 Spark Master 进程
start-master.sh
启动 Spark Slaves 进程
start-slaves.sh
启动 Spark History Server 进程
start-history-server.sh
5.2 关闭Apache Spark
关闭 Spark Master 进程
stop-master.sh
关闭 Spark Slaves 进程
stop-slaves.sh
关闭 Spark History Server 进程
stop-history-server.sh
6. 测试
PI 案例:
6.1 Standyalone 提交命令
spark-submit \
--master spark://node91:7077 \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.3.1.jar 10000
6.2 YARN提交命令
spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.11-2.3.1.jar 10000
7. Web UI
Spark Master UI:8089
Spark Worker UI: 8081
Spark History Server UI:18080
Spark Master : 提交作业端口 7077