今天讲抓包工具的charles的使用;一个示例:斗鱼图片的直播间图片的抓取并且存放在MongoDB中;爬虫项目的远程部署及使用scrapy-redis模块进行分布式爬虫。
Charles
- Charles是一个Mac端用来抓取手机端数据包的工具,相当于在windows中的fidder.
使用步骤为:
1. 下载安装软件
2. 绑定软件端的端口号,默认为8888
3. 设置mac为热点,手机连接到热点上,手动保定ip和端口
4. 手机端下载证书,安装
5. 开始使用
示例:爬取手机端斗鱼直播图片信息
- 爬取基本流程跟之前一样,不一样的地方有:
- 存储图片使用ImagesPipeLine类
- get_media_requests(self, item, info) 方法,用来获取请求中的图片等信息
- 设置图片存储位置:在settings中设置,可以使相对路径,也可以是绝对路径
- 如:相对路径:IMAGES_STORE = ‘images/’
- 修改文件图片的文件名:os.rename(),注意没有设置图片使用默认填充图片的情况,可以使用try预处理一下
- 将图片存储到mongoDB中,使用pymongo模块,步骤如下:
- 链接mongoDB:self.client=pymongo.MongoClient(‘127.0.0.1’, 27017)
- 创建数据库:self.db = self.client[‘Douyu’]
- 创建集合: self.collection = self.db[‘room’]
- 插入数据:self.collection.insert(dict(item))
douyu.py:
# -*- coding: utf-8 -*-
import scrapy
import json
from DouYu.items import DouyuItem
class DouyuSpider(scrapy.Spider):
name = 'douyu'
allowed_domains = ['douyu.com']
base_urls = 'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&'
offset = 0
url = base_urls + str(offset)
start_urls = [url]
def parse(self, response):
# 解析数据
data_list = json.loads(response.body)['data']
# 如果没有数据,停止循环 递归
if not data_list:
return
# 循环遍历每一个字典
for data_dict in data_list:
item = DouyuItem()
# 房间ID
item['room_id'] = data_dict['room_id']
# 头像的大图
item['vertical_src'] = data_dict['vertical_src']
# 房间的名字
item['room_nam e'] = data_dict['room_name']
# 昵称
item['nick_name'] = data_dict['nick_name']
# 坐标城市
item['auchor_city'] = data_dict['auchor_city']
# 解析完毕数据 --》引擎 ---》管道
yield item
# self.offset += 20
# url = self.base_urls + str(self.offset)
# yield scrapy.Request(url=url, callback=self.parse)
items.py
import scrapy
class DouyuItem(scrapy.Item):
# 房间ID
room_id = scrapy.Field
# 头像的大图
vertical_src = scrapy.Field
# 房间的名字
room_name = scrapy.Field
# 昵称
nickname = scrapy.Field
# 坐标城市
auchor_city = scrapy.Field
pipelines.py
import json
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from settings import IMAGES_STORE
import os
import pymongo
# 下载 头像的图片
class DouyuImagePipeline(ImagesPipeline):
# 下载图片的方法
def get_media_requests(self, item, info):
# 1.图片的的url
image_url = item['vertical_src']
# 2.发送图片的请求
yield scrapy.Request(url=image_url)
# 3.图片存储路径 --设置文件 settings.py
# 修改图片的名字 --》昵称
def item_completed(self, results, item, info):
# 有可能列表为空,所以判断一下
path = [x['path'] for ok, x in results if ok]
if path:
# 1.获取老的图片的路径
old_path = IMAGES_STORE + path[0]
# 2.拼接 昵称的 新的路径
new_path = IMAGES_STORE + item['nickname'] + '.jpg'
# 3.将路径替换 os.rename
# 预处理原因:有主播的头像是空的, 斗鱼给的是一样的占位图
try:
os.rename(old_path, new_path)
except Exception, err:
print '图片已经修改成功'
return item
class DouyuPipeline(object):
def open_spider(self, spider):
self.file = open('douyu,json', 'w')
def process_item(self, item, spider):
str_item = json.dumps(dict(item)) + '\n'
self.file.write(str_item)
return item
def close_spider(self, spider):
self.file.close()
class DouyuMongoDBPipeline(object):
def open_spider(self, spider):
# 连接数据库
self.client = pymongo.MongoClient('127.0.0.1', 27017)
self.db = self.client['Douyu']
self.collection = self.db['room']
# 将数据写入数据库
def process_item(self, item, soider):
self.collection.insert(dict(item))
return item
# 关闭客户端
def close_spider(self, spider):
self.client.close()
setting.py
BOT_NAME = 'DouYu'
SPIDER_MODULES = ['DouYu.spiders']
NEWSPIDER_MODULE = 'DouYu.spiders'
# 设置图片保存的路径 最后的 斜杠要加
# 相对路径
IMAGES_STORE = 'images/'
USER_AGENT = "Mozilla/5.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12A365 Safari/600.1.4"
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
ITEM_PIPELINES ={
'Douyu.pipelines.DouyuPipeline':300,
'Douyu.pipelines.DouyuImagePipeline':400,
'Douyu.pipelines.DouyuMongoDBPipeline':500,
}
scrapyd远程部署爬虫项目
- scrapyd是一个python的功能模块,需要安装服务器端和客户端
- 完成的功能就是,只需要一个url就可以远程管理(开启,关闭,查看日志)部署到远程服务器上的爬虫项目,比如下班回家使用手机也可以查看公司服务器爬虫项目的运行情况
浏览器输入url后,显示效果如下:
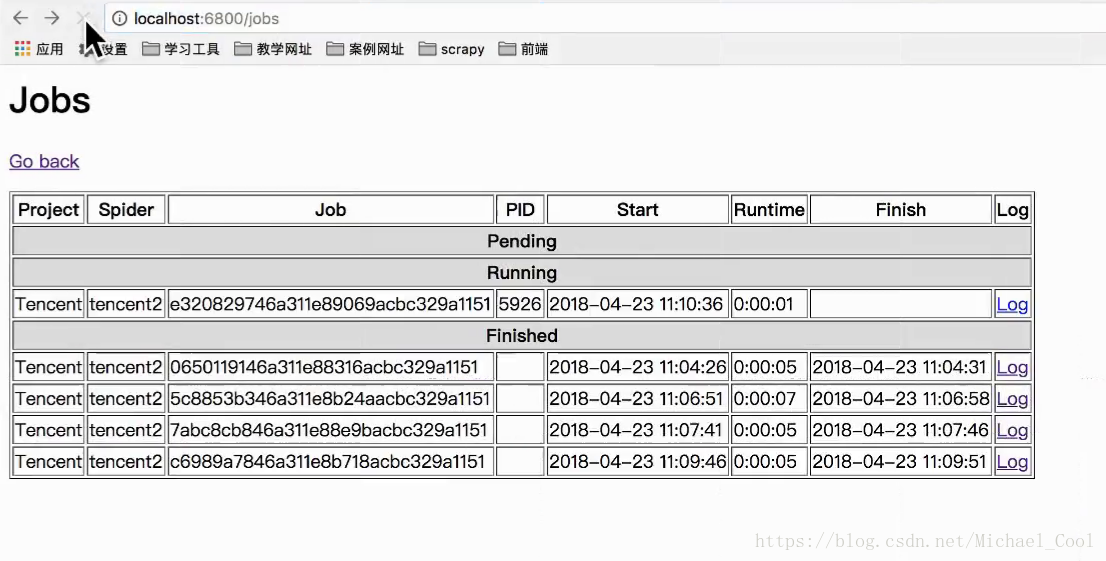
使用步骤如下:
1.安装
1.服务端
pip install scrapyd
2.客户端
pip install scrapyd-client
3.配置 服务端conf, bind:0.0.0.0(任意访问)
4.开启服务 scrapyd
5.配置项目中的部署文件:(以下步骤默认为Tencent项目的tencent2爬虫)
修改以前:
[deploy]
#url = http://localhost:6800/
project = Tencent
修改之后:
[deploy:scrapyd_Tencent]
url = http://localhost:6800/
project = Tencent
6. 将 爬虫的项目 部署到 服务器
6.1千万注意 cd 项目路径下
6.2 scrapyd-deploy scrapyd_Tencent -p Tencent
7. 开启爬虫
curl http://localhost:6800/schedule.json -d project=Tencent -d spider=tencent2
8. 终止爬虫
curl http://localhost:6800/cancel.json -d project=Tencent -d job=a6fc833a25a111e89a80acbc329a1151
scrapy-redis分布式爬虫
- 所谓分布式,就是同一个资源库调用若干台机器各爬取部分数据,如100万的数据分给5台机器,每台机器20万数据,假设机器性能相同,没有反爬情况,那么,原来一台机器需要5个小时的工作量,分布式5台机器,只需要1个小时就完成任务了。
- scrapy本身是不能分布式的,因为每一个项目的调度器都是独立的。
- 使用scrapy-redis组件,就可以完成分布式的功能,它是在scrapy架构的基础上拓展了集中处理请求的功能。
scrapy-redis框架
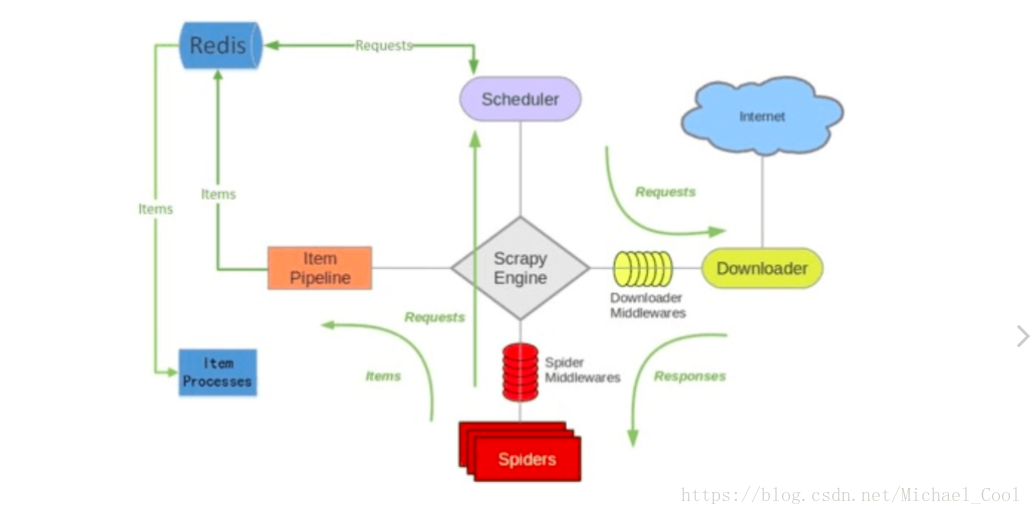
scrapy-redis原理
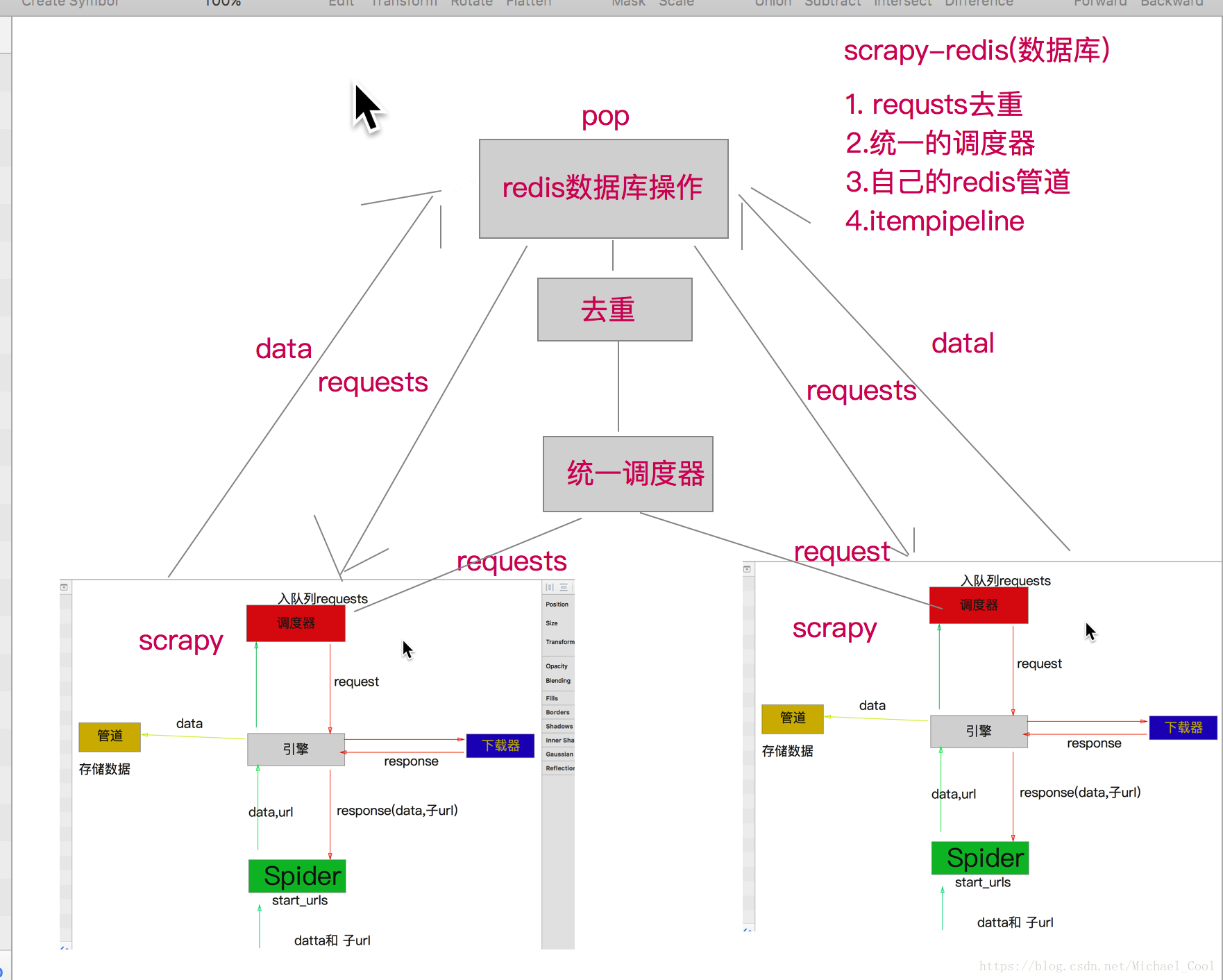
四大组件:
- Scheduler
- Duplication Filter
- Item Pipeline
Base Spider
通过重写scheduler和spider类,实现了调度、spider启动和redis的交互
实现步骤:
可参考官方案例:
https://github.com/rolando/scrapy-redis