这里是首先需要安装好Anaconda
Anaconda的安装参考Python之路-初识python及环境搭建并测试
配置好环境之后开始使用Jupyter Notebook
1.打开cmd,输入 jupyter notebook --generate-config
2.打开这个配置文件,找到“c.NotebookApp.notebook_dir=‘’ ”, 把路径改成自己的工作目录

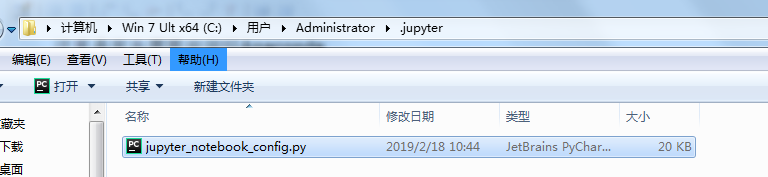
使用notepad++打开这个文件,大概在124行添加自己的工作目录
c.NotebookApp.notebook_dir = 'D:\Python' 注意:去掉注释符合,前面不能有空格
3.配置文件修改完成后, 以后在jupyter notebook中写的代码等都会保存在自己创建的目录中。
Scipy库简介
Scipy库是基于Python生态的一款开源数值计算、科学与工程应用的开源软件,主要包括NumPy、Scipy、pandas、matplotlib等等。
官方文档:https://scipy.org/
numPy、Scipy、pandas、matplotlib简介
numpy——基础,以矩阵为基础的数学计算模块,纯数学存储和处理大型矩阵。 这个是很基础的扩展,其余的扩展都是以此为基础。
scipy——数值计算库,在numPy库的基础上增加了众多的数学、科学以及工程计算中常用的库函数。 方便、易于使用、专为科学和工程设计的Python工具包.它包括统计,优化,整合,线性代数模块,傅里叶变换,信号和图像处理,常微分方程求解器等等。
pandas——数据分析,基于numPy 的一种工具,为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
matplotlib——绘图,对于图像美化方面比较完善,可以自定义线条的颜色和式样,可以在一张绘图纸上绘制多张小图,也可在一张图上绘制多条线,可以很方便的对数据进行可视化分析。
NumPy历史
1995年Jim HugUNin开发了Numeric
随后Numarray包诞生
Travis Oliphants整合Numeric和Numarray,开发NumPy,2006 年第一个版本诞生
使用Anaconda发行版的Python,已经安装好NumPy模块,所以可以不用再安装NumPy模块了。
依照标准的NumPy标准,习惯使用import numpy as np的方式导入该模块。
NumPy模块
numPy:Numerical Python,即数值Python包,是Python进行科学计算的一个基础包,所以是一个掌握其他Scipy库中模块的基础模块,一定需要先掌握该包的主要使用方式。
官方文档:https://docs.scipy.org/doc/numpy/user/index.html
NumPy模块是Python的一种开源的数值计算扩展,是一个用python实现的科学计算包,主要包括:
一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组,称为ndarray(N-dimensional array object)
用于对整组数据进行快速运算的标准数学函数:ufunc(universal function object)
实用的线性代数、傅里叶变换和随机数生成函数。
NumPy和稀疏矩阵的运算包Scipy配合使用更加方便。
NumPy核心数据结构:ndarray
NumPy的数组类被称作ndarray。通常被称作数组。注意numpy.array和标准Python库类array.array并不相同,后者只处理一维数组和提供少量功能。
一种由相同类型的元素组成的多维数组,元素数量是实现给定好的
元素的数据类型由dtype(data-type)对象来指定,每个ndarray只有一种dtype类型
ndarray的大小固定,创建好数组后数组大小是不会再发生改变的
ndarray创建
可以通过numpy模块中的常用的几个函数进行创建ndarray多维数组对象,主要函数如下:
array函数:接收一个普通的python序列,并将其转换为ndarray
zeros函数:创建指定长度或者形状的全零数组。
ones函数:创建指定长度或者形状的全1数组。
empty函数:创建一个没有任何具体值的数组(准备地说是创建一些未初始化的ndarray多维数组)
练习
In [1]:
import numpy as np
创建数组
In [2]:
help(np.array)
Help on built-in function array in module numpy.core.multiarray:
array(...)
array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)
Create an array.
Parameters
----------
object : array_like
An array, any object exposing the array interface, an
object whose __array__ method returns an array, or any
(nested) sequence.
dtype : data-type, optional
The desired data-type for the array. If not given, then
the type will be determined as the minimum type required
to hold the objects in the sequence. This argument can only
be used to 'upcast' the array. For downcasting, use the
.astype(t) method.
copy : bool, optional
If true (default), then the object is copied. Otherwise, a copy
will only be made if __array__ returns a copy, if obj is a
nested sequence, or if a copy is needed to satisfy any of the other
requirements (`dtype`, `order`, etc.).
order : {'C', 'F', 'A'}, optional
Specify the order of the array. If order is 'C', then the array
will be in C-contiguous order (last-index varies the fastest).
If order is 'F', then the returned array will be in
Fortran-contiguous order (first-index varies the fastest).
If order is 'A' (default), then the returned array may be
in any order (either C-, Fortran-contiguous, or even discontiguous),
unless a copy is required, in which case it will be C-contiguous.
subok : bool, optional
If True, then sub-classes will be passed-through, otherwise
the returned array will be forced to be a base-class array (default).
ndmin : int, optional
Specifies the minimum number of dimensions that the resulting
array should have. Ones will be pre-pended to the shape as
needed to meet this requirement.
Returns
-------
out : ndarray
An array object satisfying the specified requirements.
See Also
--------
empty, empty_like, zeros, zeros_like, ones, ones_like, fill
Examples
--------
>>> np.array([1, 2, 3])
array([1, 2, 3])
Upcasting:
>>> np.array([1, 2, 3.0])
array([ 1., 2., 3.])
More than one dimension:
>>> np.array([[1, 2], [3, 4]])
array([[1, 2],
[3, 4]])
Minimum dimensions 2:
>>> np.array([1, 2, 3], ndmin=2)
array([[1, 2, 3]])
Type provided:
>>> np.array([1, 2, 3], dtype=complex)
array([ 1.+0.j, 2.+0.j, 3.+0.j])
Data-type consisting of more than one element:
>>> x = np.array([(1,2),(3,4)],dtype=[('a','<i4'),('b','<i4')])
>>> x['a']
array([1, 3])
Creating an array from sub-classes:
>>> np.array(np.mat('1 2; 3 4'))
array([[1, 2],
[3, 4]])
>>> np.array(np.mat('1 2; 3 4'), subok=True)
matrix([[1, 2],
[3, 4]])
In [3]:
#用一维列表创建
np.array([1,2,3])
Out[3]:
array([1, 2, 3])
In [4]:
#用元祖创建
np.array((1,2,3))
Out[4]:
array([1, 2, 3])
In [6]:
#duo维数组
np.array([[1,2,3,4],[5,6,7,8]])
Out[6]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
In [8]:
#三维数组
np.array([[1,2,3],[2,3,4],
[[4,5,6],[6,7,8]]])
Out[8]:
array([[1, 2, 3], [2, 3, 4], [[4, 5, 6], [6, 7, 8]]], dtype=object)
In [15]:
#通过zeros创建数组,创建一个元素为0d的数组
# np.zeros((3,3))
np.zeros((2,3,4))
Out[15]:
array([[[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]],
[[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]]])
In [16]:
#ones生成元素为1的数组
np.ones((2,3))
Out[16]:
array([[ 1., 1., 1.],
[ 1., 1., 1.]])
In [17]:
np.empty((3,3))
Out[17]:
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
ndarray其它创建方式
arange函数: 类似python的range函数,通过指定开始值、终值和步长来创建一个一维数组,注意:最终创建的数组不包含终值
linspace函数:通过指定开始值、终值和元素个数来创建一个一维数组,数组的数据元素符合等差数列,可以通过endpoint关键字指定是否包含终值,默认包含终值
logspace函数:和linspace函数类似,不过创建的是等比数列数组
使用随机数填充数组,即使用numpy.random中的random()函数来创建0-1之间的随机元素,数组包含的元素数量由参数决定
练习
其他创建方式
In [22]:
#arange
# np.arange(9)
# np.arange(1,9,2)
np.arange(9,0,-2)
Out[22]:
array([9, 7, 5, 3, 1])
In [23]:
#linspace生成等差shulie
np.linspace(1,10,5)
Out[23]:
array([ 1. , 3.25, 5.5 , 7.75, 10. ])
In [25]:
#logspace等比数列
# np.logspace(0,2,5)#默认
np.logspace(0,2,5,base = 2)
Out[25]:
array([ 1. , 1.41421356, 2. , 2.82842712, 4. ])
In [27]:
#使用random创建随机数
np.random.random((3,3))
Out[27]:
array([[ 0.78764356, 0.39990922, 0.65267886],
[ 0.85181922, 0.47399746, 0.3324923 ],
[ 0.90719725, 0.16047382, 0.25940587]])
In [30]:
np.random.randint(10,30,size = (3,3))
Out[30]:
array([[13, 12, 11],
[22, 18, 19],
[26, 10, 25]])
In [31]:
np.random.randn(3,3)#标准正态分布
Out[31]:
array([[ 0.89698445, 0.76038415, 0.96602525],
[ 1.03257187, -2.18487826, 0.30305221],
[ 0.33735975, 0.25791743, -0.23504451]])
In [32]:
np.random.rand(9)#(0,1)之间的随机数
Out[32]:
array([ 0.81492509, 0.16966199, 0.38262906, 0.08861263, 0.75228657,
0.9020329 , 0.91608186, 0.16995603, 0.95110964])
ndarray对象属性
ndim 数组轴(维度)的个数,轴的个数被称作秩
shape 数组的维度, 例如一个2排3列的矩阵,它的shape属性将是(2,3),这个元组的长度显然是秩,即维度或者ndim属性
size 数组元素的总个数,等于shape属性中元组元素的乘积。
dtype 一个用来描述数组中元素类型的对象,可以通过创造或指定dtype使用标准Python类型。不过NumPy提供它自己的数据类型。
itemsize 数组中每个元素的字节大小。例如,一个元素类型为float64的数组itemsiz属性值为8(=64/8),又如,一个元素类型为complex32的数组item属性为4(=32/8).
NumPy基本数据类型
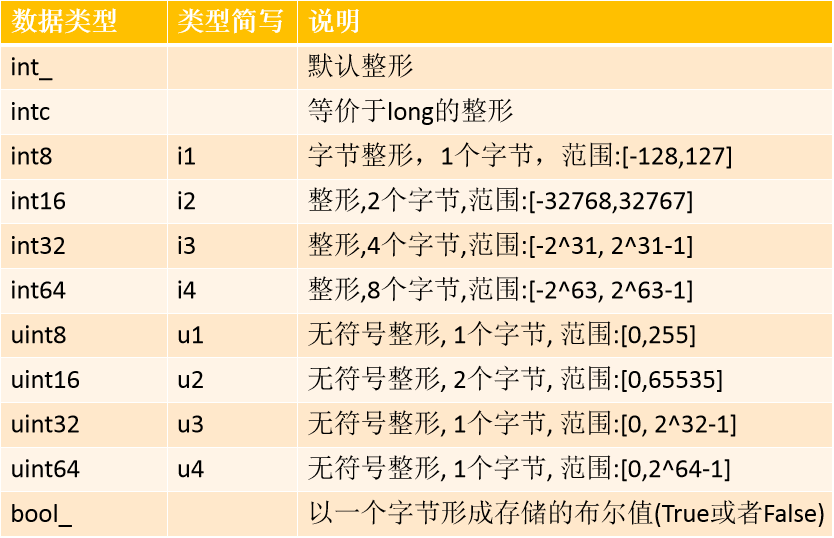
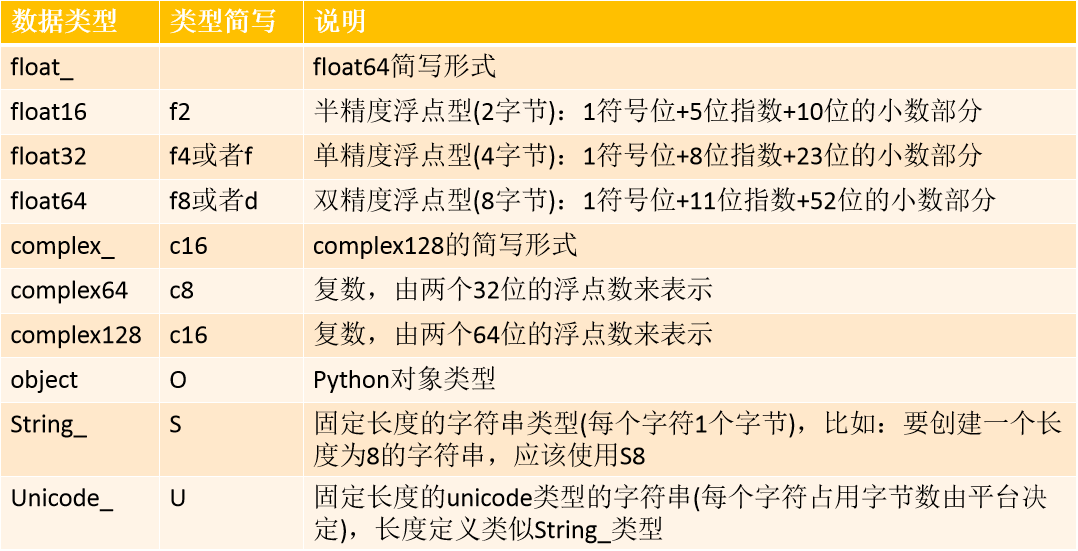
ndarray中元素数据类型
创建numpy数组的时候可以通过属性dtype显示指定数据类型,如果不指定的情况下,numpy会自动推断出适合的数据类型,所以一般不需要显示给定数据类型。
如果需要更改一个已经存在的数组的数据类型,可以通过astype方法进行修改从而得到一个新数组。
NumPy基本数据类型
数值型dtype的命名方式为:一个类型名称(eg:int、float等),后接一个表示各个元素位长的数字
比如Python的float数据类型(双精度浮点值),需要占用8个字节(64位),因此在NumPy中记为float64
每个数据类型都有一个类型代码,即简写方式
练习
In [1]:
import numpy as np
基本属性
In [12]:
#ndimdim数组轴(维度)的个数,轴的个数称为秩
arr = np.random.randint(1,9,size = (3,3))
# arr
arr.ndim
Out[12]:
array([[2, 4, 4],
[7, 1, 8],
[7, 7, 5]])
In [14]:
#shape数组的维度 形状
arr = np.random.randint(1,9,size = (3,3))
arr.shape
Out[14]:
(3, 3)
In [18]:
#dtype 描述元祖中元素类型
arr = np.random.randint(1,9,size = (2,3))
arr.dtype
arr.itemsize#元素字节大小
arr.size#元素个数
Out[18]:
6
In [24]:
# arr2 = np.array([1,2,3,4])
# arr2.dtype
# arr3 = arr2.astype('f4')
# arr3.dtype
arr2 = np.array([1,2,3,4],dtype = float)
arr2.dtype
Out[24]:
dtype('float64')
In [27]:
np.array(['Python','java','C'],dtype = 'S9')
Out[27]:
array([b'Python', b'java', b'C'],
dtype='|S9')
ndarray修改形状
对于一个已经存在的ndarray数组对象而言,可以通过修改形状相关的参数/方法从而改变数组的形状。
直接修改数组ndarray的shape值, 要求修改后乘积不变。
直接使用reshape函数创建一个改变尺寸的新数组,原数组的shape保持不变,但是新数组和原数组共享一个内存空间,也就是修改任何一个数组中的值都会对另外一个产生影响,另外要求新数组的元素个数和原数组一致。
当指定某一个轴为-1的时候,表示将根据数组元素的数量自动计算该轴的长度值。
练习
修改数组形状
In [37]:
#shape修改
arr = np.random.randint(1,9,size = (2,5))
arr.shape
# arr.shape = (5,2)
# arr
arr.shape = (-1,5)
arr
Out[37]:
array([[6, 6, 4, 6, 6],
[3, 1, 1, 8, 7]])
In [45]:
#reshape修改
arr = np.arange(9)
arr
Out[45]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8])
In [47]:
arr2 = arr.reshape(3,3)
arr2
arr2[0][1] = 100
arr2
Out[47]:
array([[ 0, 100, 2],
[ 3, 4, 5],
[ 6, 7, 8]])
In [48]:
arr
Out[48]:
array([ 0, 100, 2, 3, 4, 5, 6, 7, 8])
In [49]:
arr = np.arange(9).reshape(3,3)
arr
Out[49]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [51]:
arr = np.arange(12).reshape(-1,3)
arr
Out[51]:
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
NumPy基本操作
数组与标量、数组之间的运算
数组的矩阵积(matrix product)
数组的索引与切片
数组的转置与轴对换
通用函数:快速的元素级数组成函数
聚合函数
np.where函数
np.unique函数
ndarray-数组与标量、数组之间的运算
数组不用循环即可对每个元素执行批量的算术运算操作,这个过程叫做矢量化,即用数组表达式代替循环的做法。
矢量化数组运算性能比纯Python方式快上一两个数据级。
大小相等的两个数组之间的任何算术运算都会将其运算应用到元素级上的操作。
元素级操作:在NumPy中,大小相等的数组之间的运算,为元素级运算,即只用于位置相同的元素之间,所得的运算结果组成一个新的数组,运算结果的位置跟操作数位置相同。
ndarray-数组的矩阵积
矩阵:多维数组即矩阵
矩阵积(matrix product):两个二维矩阵(行和列的矩阵)满足第一个矩阵的列数与第二个矩阵的行数相同,那么可以进行矩阵的乘法,即矩阵积,矩阵积不是元素级的运算。也称为点积、数量积。
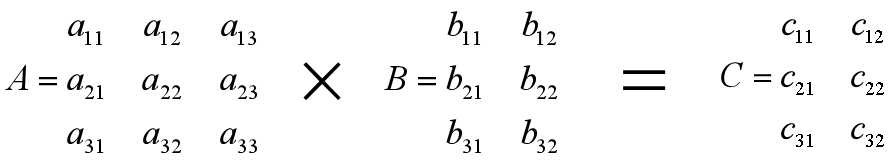
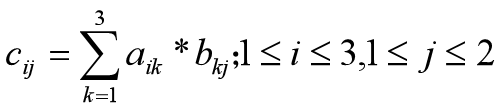
ndarray-多维数组的索引
In [1]:
import numpy as np
数组与标量的运算
In [7]:
arr = np.arange(0,9).reshape(3,3)
arr
arr+2
arr*3
arr/2
arr-3
Out[7]:
array([[-3, -2, -1],
[ 0, 1, 2],
[ 3, 4, 5]])
In [19]:
arr1 = np.array([[10,20,30],
[40,50,60]])
arr2 = np.array([[1,2,3],
[4,5,6]])
print(arr1)
print(arr2)
[[10 20 30]
[40 50 60]]
[[1 2 3]
[4 5 6]]
In [10]:
arr1+arr2
Out[10]:
array([[11, 22, 33],
[44, 55, 66]])
In [11]:
arr1*arr2
Out[11]:
array([[ 10, 40, 90],
[160, 250, 360]])
In [12]:
print(arr2-arr1)
[[ -9 -18 -27]
[-36 -45 -54]]
In [20]:
print(arr2 / arr1)
[[ 0.1 0.1 0.1]
[ 0.1 0.1 0.1]]
In [24]:
arr1 = np.array([[100,101,102],
[50,60,70],
[10,20,30]])
arr2 = np.array([[2,3],
[3,4],
[5,6]])
print(arr1)
print(arr2)
[[100 101 102]
[ 50 60 70]
[ 10 20 30]]
[[2 3]
[3 4]
[5 6]]
In [26]:
np.dot(arr1,arr2)#矩阵相乘(点积)
Out[26]:
array([[1013, 1316],
[ 630, 810],
[ 230, 290]])
ndarray-数组的切片
ndarray-布尔类型索引
利用布尔类型的数组进行数据索引,最终返回的结果是对应索引数组中数据为True位置的值。
练习
索引和切片
In [27]:
arr = np.random.randint(1,9,size = (2,3,3))
arr
Out[27]:
array([[[4, 3, 8],
[4, 3, 6],
[1, 8, 4]],
[[4, 3, 2],
[4, 5, 2],
[5, 2, 8]]])
In [28]:
print(arr[0,0,1])
3
In [29]:
print(arr[0,0,1])
3
In [30]:
print(arr[1,0,1])
3
In [31]:
print(arr[:,:,1])#切片
[[3 3 8]
[3 5 2]]
In [32]:
arr = np.random.randint(1,9,size = (2,3,4))
arr
Out[32]:
array([[[3, 5, 8, 7],
[5, 8, 6, 1],
[6, 8, 5, 2]],
[[3, 2, 3, 6],
[5, 4, 8, 6],
[8, 2, 4, 5]]])
In [33]:
print(arr[:,:,1:3])
[[[5 8]
[8 6]
[8 5]]
[[2 3]
[4 8]
[2 4]]]
In [34]:
print(arr[0,:,1:3])
[[5 8]
[8 6]
[8 5]]
In [35]:
print(arr[0,1:3,1:3])
[[8 6]
[8 5]]
In [37]:
print(arr[0,0:3:2,1:3])
[[5 8]
[8 5]]
ndarray-花式索引
花式索引(Fancy indexing)指的是利用整数数组进行索引的方式。
练习
花式索引
In [39]:
arr = np.random.randint(1,9,size = (8,4))
arr
Out[39]:
array([[1, 3, 7, 3],
[5, 5, 6, 3],
[3, 7, 2, 7],
[1, 8, 4, 2],
[2, 7, 6, 2],
[4, 7, 8, 5],
[3, 6, 4, 2],
[5, 3, 2, 1]])
In [40]:
#获取0,3,5 行
print(arr[[0,3,5]])
[[1 3 7 3]
[1 8 4 2]
[4 7 8 5]]
In [42]:
#获取0,0 3,3 5,2数据
print(arr[[0,3,5],[0,3,2]])
[1 2 8]
In [43]:
#索引器
print(arr[np.ix_([0,3,5],[0,3,2])])
[[1 3 7]
[1 2 4]
[4 5 8]]
ndarray-数组转置与轴对换
数组转置是指将shape进行重置操作,并将其值重置为原始shape元组的倒置,比如原始的shape值为:(2,3,4),那么转置后的新元组的shape的值为: (4,3,2)f
对于二维数组而言(矩阵)数组的转置其实就是矩阵的转置
可以通过调用数组的transpose函数或者T属性进行数组转置操作
练习
布尔索引
In [46]:
A = np.random.random((4,4))
print(A.shape)
A
(4, 4)
Out[46]:
array([[ 0.10672869, 0.852003 , 0.53935853, 0.07336634],
[ 0.38104429, 0.13577986, 0.41589372, 0.39334269],
[ 0.38895639, 0.41326197, 0.05121095, 0.76327218],
[ 0.5542428 , 0.62085344, 0.06846954, 0.13081136]])
In [47]:
arr2 = A < 0.5
arr2
Out[47]:
array([[ True, False, False, True],
[ True, True, True, True],
[ True, True, True, False],
[False, False, True, True]], dtype=bool)
In [80]:
name = np.array(['joe','susan','Tom'])
score = np.array([
[70,80,90],
[77,88,99],
[66,78,89],
])
classes = np.array(['语文','数学','英语'])
print(score)
[[70 80 90]
[77 88 99]
[66 78 89]]
In [82]:
name2 = name == 'joe'
name2
Out[82]:
array([ True, False, False], dtype=bool)
In [86]:
score[name == 'joe'].reshape(-1)
Out[86]:
array([70, 80, 90])
In [88]:
score[name == 'joe',classes == '数学']
Out[88]:
array([80])
In [89]:
score[name == 'Tom',classes == '语文']
Out[89]:
array([66])
In [90]:
score[(name == 'joe')|(name == 'susan')]
Out[90]:
array([[70, 80, 90],
[77, 88, 99]])
In [91]:
score[(name != 'joe')&(name != 'susan')]
Out[91]:
array([[66, 78, 89]])
In [92]:
score[(name != 'joe')&(name != 'susan'),classes == '数学']
Out[92]:
array([78])
ndarray-通用函数/常用函数
ufunc:numpy模块中对ndarray中数据进行快速元素级运算的函数,也可以看做是简单的函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
主要包括一元函数和二元函数
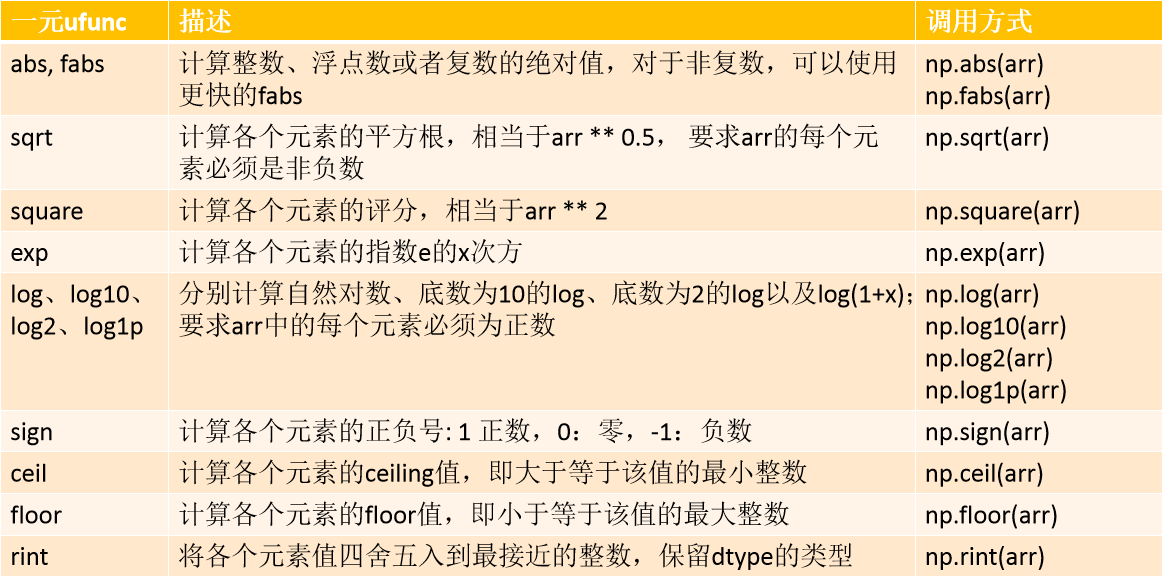
ndarray-通用函数/常用函数(一元函数)

练习
In [1]:
import numpy as np
常用一元函数
In [2]:
arr = np.array([-1,-2,-4])
np.abs(arr)
Out[2]:
array([1, 2, 4])
In [6]:
#平方根
arr = np.random.randint(1,9,size = (3,3))
print(arr)
print(np.sqrt(arr))
[[5 2 2]
[1 7 3]
[1 4 1]]
[[ 2.23606798 1.41421356 1.41421356]
[ 1. 2.64575131 1.73205081]
[ 1. 2. 1. ]]
In [8]:
arr = np.random.randint(1,9,size = (3,3))
print(arr)
print(np.exp(arr))
print(np.sign(arr))
[[6 4 1]
[1 4 8]
[2 3 3]]
[[ 4.03428793e+02 5.45981500e+01 2.71828183e+00]
[ 2.71828183e+00 5.45981500e+01 2.98095799e+03]
[ 7.38905610e+00 2.00855369e+01 2.00855369e+01]]
[[1 1 1]
[1 1 1]
[1 1 1]]
In [11]:
arr = np.random.randint(1,9,size = (3,3))
print(arr)
print(np.isnan(arr))
print(np.isfinite(arr))#有穷
print(np.isinf(arr))#无穷
[[1 2 5]
[1 8 7]
[3 6 7]]
[[False False False]
[False False False]
[False False False]]
[[ True True True]
[ True True True]
[ True True True]]
[[False False False]
[False False False]
[False False False]]
ndarray-通用函数/常用函数(二元函数)

练习
二元函数
In [12]:
arr = np.random.randint(1,9,size = (3,3))
arr2 = np.random.randint(1,9,size = (3,3))
print(arr)
print(arr2)
[[2 7 2]
[1 5 7]
[8 6 2]]
[[2 8 1]
[4 2 5]
[5 5 4]]
In [13]:
np.greater(arr,arr2)#比大小
Out[13]:
array([[False, False, True],
[False, True, True],
[ True, True, False]], dtype=bool)
In [14]:
np.power(arr,2)#次方
Out[14]:
array([[ 4, 49, 4],
[ 1, 25, 49],
[64, 36, 4]], dtype=int32)
ndarray-聚合函数
聚合函数是对一组值(eg一个数组)进行操作,返回一个单一值作为结果的函数。当然聚合函数也可以指定对某个具体的轴进行数据聚合操作;
常将的聚合操作有:平均值、最大值、最小值、方差等等
练习
聚合函数
In [15]:
arr = np.random.randint(1,9,size = (3,3))
arr
Out[15]:
array([[6, 3, 5],
[4, 5, 8],
[3, 3, 6]])
In [22]:
# print(arr.min(axis = 0))#列
# print(arr.max(axis = 0))
# print(arr.mean(axis = 0))
# print(arr.min(axis = 1))#行
# print(arr.max(axis = 1))
# print(arr.mean(axis = 1))
print(arr.std())
print(arr.std(axis = 1))
1.61780219762
[ 1.24721913 1.69967317 1.41421356]
np.where函数
np.where函数是三元表达式x if condition else y的矢量化版本
练习
案例:将数组中的所有异常数字替换为0,比如将NaN替换为0
where函数
In [23]:
help(np.where)
Help on built-in function where in module numpy.core.multiarray:
where(...)
where(condition, [x, y])
Return elements, either from `x` or `y`, depending on `condition`.
If only `condition` is given, return ``condition.nonzero()``.
Parameters
----------
condition : array_like, bool
When True, yield `x`, otherwise yield `y`.
x, y : array_like, optional
Values from which to choose. `x` and `y` need to have the same
shape as `condition`.
Returns
-------
out : ndarray or tuple of ndarrays
If both `x` and `y` are specified, the output array contains
elements of `x` where `condition` is True, and elements from
`y` elsewhere.
If only `condition` is given, return the tuple
``condition.nonzero()``, the indices where `condition` is True.
See Also
--------
nonzero, choose
Notes
-----
If `x` and `y` are given and input arrays are 1-D, `where` is
equivalent to::
[xv if c else yv for (c,xv,yv) in zip(condition,x,y)]
Examples
--------
>>> np.where([[True, False], [True, True]],
... [[1, 2], [3, 4]],
... [[9, 8], [7, 6]])
array([[1, 8],
[3, 4]])
>>> np.where([[0, 1], [1, 0]])
(array([0, 1]), array([1, 0]))
>>> x = np.arange(9.).reshape(3, 3)
>>> np.where( x > 5 )
(array([2, 2, 2]), array([0, 1, 2]))
>>> x[np.where( x > 3.0 )] # Note: result is 1D.
array([ 4., 5., 6., 7., 8.])
>>> np.where(x < 5, x, -1) # Note: broadcasting.
array([[ 0., 1., 2.],
[ 3., 4., -1.],
[-1., -1., -1.]])
Find the indices of elements of `x` that are in `goodvalues`.
>>> goodvalues = [3, 4, 7]
>>> ix = np.in1d(x.ravel(), goodvalues).reshape(x.shape)
>>> ix
array([[False, False, False],
[ True, True, False],
[False, True, False]], dtype=bool)
>>> np.where(ix)
(array([1, 1, 2]), array([0, 1, 1]))
In [24]:
np.where([[True, False], [True, True]],[[1, 2], [3, 4]],[[9, 8], [7, 6]])
Out[24]:
array([[1, 8],
[3, 4]])
In [25]:
np.where([[0, 1], [1, 0]])
Out[25]:
(array([0, 1], dtype=int64), array([1, 0], dtype=int64))
In [27]:
x = np.arange(9.).reshape(3, 3)
print(x)
np.where( x > 5 )
[[ 0. 1. 2.]
[ 3. 4. 5.]
[ 6. 7. 8.]]
Out[27]:
(array([2, 2, 2], dtype=int64), array([0, 1, 2], dtype=int64))
In [28]:
arr1 = np.random.randint(1,9,size = (1,5)).reshape(-1)
arr2 = np.random.randint(1,9,size = (1,5)).reshape(-1)
print(arr1)
print(arr2)
[5 7 7 8 2]
[6 4 8 5 4]
In [29]:
condition = arr1 < arr2
print(condition)
[ True False True False True]
In [30]:
arr4 = np.where(condition,arr1,arr2)
arr4
Out[30]:
array([5, 4, 7, 5, 2])
In [34]:
arr = np.array([
[1,2,3,np.NaN],
[1,2,3,np.pi],
[1,2,3,np.e]
])
arr
condition = np.isnan(arr)|np.isinf(arr)
arr2 = np.where(condition,0,arr)
arr2
Out[34]:
array([[ 1. , 2. , 3. , 0. ],
[ 1. , 2. , 3. , 3.14159265],
[ 1. , 2. , 3. , 2.71828183]])
np.unique函数
np.unique函数的主要作用是将数组中的元素进行去重操作(也就是只保存不重复的数据)
练习
unique去重操作
In [37]:
arr = np.array(['a','b','c','d','a','b','c','d'])
arr
print(np.unique(arr))
['a' 'b' 'c' 'd']