视频学习网站:Google机器学习教程
这是我自己的随堂笔记。
一 基本术语
样品 数据的特征实例:定义为x
标签 :定义为y
有标签样本 具有{特征,标签}:(x,y)一般作为训练集使用
无标签样本 具有{特征,?}:(x,?)一般作为测试集使用
预测标签 通过训练的模型对无标签样本的预测:定义为y’
模型 模型定义了特征与标签之间的关系,可以将样本映射到预测标签:y’
由模型内部参数定义,参数值可以通过学习得到的;
模型生命周期的两个阶段:训练,推断
训练:包含创建和学习模型,向模型展示有标签样本,让模型逐渐学习特征和标签的关系
推断:将训练完成的模型应用于无标签样本中,用以做出有用的判断(y’)
回归 回归模型可预测连续值(得出具体数值)
例:用户点击此广告的概率是多少?
分类 分类模型可预测分离值(判断属于哪一类)
例:这是一张狗、猫还是仓鼠图片?
二 最简单的机器学习案例
在机器学习中,一般会有多个实用特征(条件),和一个标签(结论);
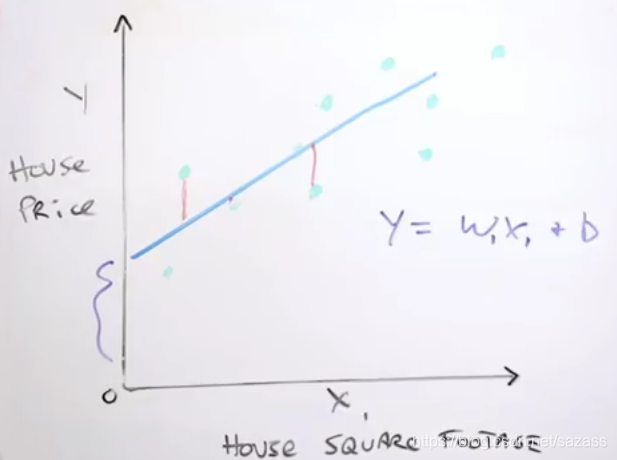
例如:预测一套房的出售价格,标签:出售价格,实用特征:面积,位置,楼层等等;
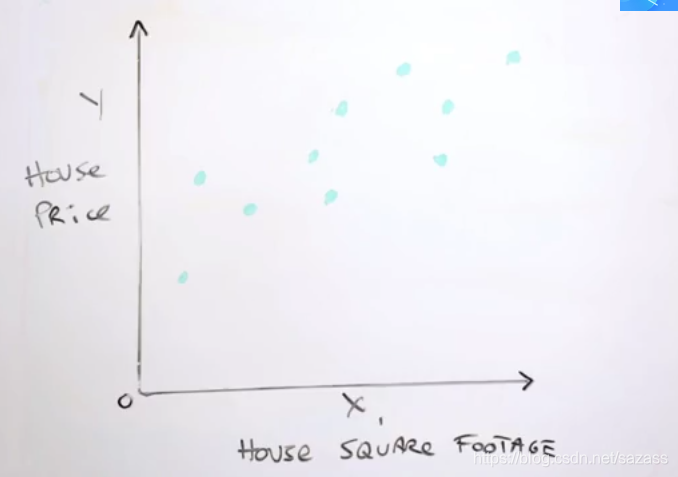
y轴是价格(即标签),x轴为特征;
图可以理解为研究价格与某单一特征的关系,图中每一个蓝色的点代表为一个有标签样本;
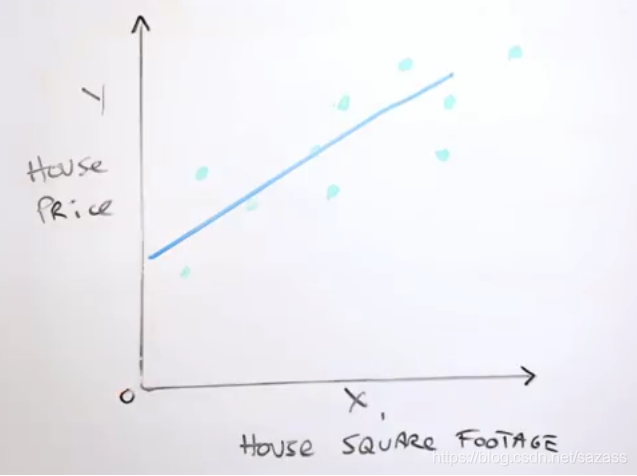
在图中画一条线,这条线可以理解为机器学习中的模型,表示这标签与单一特征的关系(为简单化这里以线性关系举例);
我们可以用:y=wx+b来表示这条直线(w称为权值,b称为偏差);
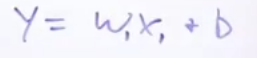
一般会出现小下标,因为往往不止一个特征,一个特征代表一个维度;
例如具有三个特征的模型可以采用以下方程式:
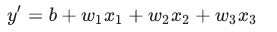
模型都往往存在误差,我们需要定义一个误差函数;
评估模型性能的要素:损失
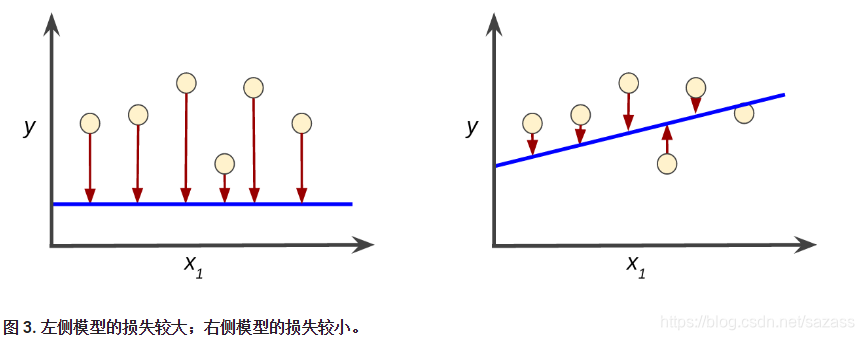
损失是一个数值,表示对于单个样本而言模型预测的准确程度。如果模型的预测完全准确,则损失为零,否则损失会较大。训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差。例如,图 3 左侧显示的是损失较大的模型,右侧显示的是损失较小的模型。
好用的回归损失函数:
平方误差=预测值与标签值之差的平方=(观察值 - 预测值)²=(y-y’)²
我们在训练样本时并不是侧重于降低某一样本的误差,而是着眼于降低全局的误差。
三 降低损失
一种方法是梯度下降法,针对于方差等简单的误差函数,可以简单的计算出导数,这样可以及时更新计算参数;
整个过程可以理解为训练模型的迭代试错过程: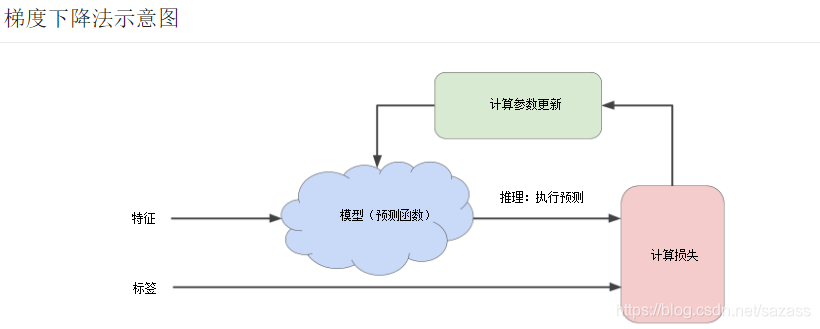
“模型”部分将一个或多个特征作为输入,然后返回一个预测 (y’) 作为输出。为了进行简化,不妨考虑一种采用一个特征并返回一个预测的模型:
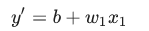
我们应该为 b 和 w1 设置哪些初始值?对于线性回归问题,事实证明初始值并不重要。我们可以随机选择值,不过我们还是选择采用以下这些无关紧要的值: b=0,w1=0
假设第一个特征值是 10。将该特征值代入预测函数会得到以下结果:
y' = 0 + 0(10)
y' = 0
图中的“计算损失”部分是模型将要使用的损失函数。假设我们使用平方损失函数。损失函数将采用两个输入值:
y:特征x对应的正确标签
y’:模型对特征x的特征预测

计算参数更新:
机器学习系统就是在此部分检查损失函数的值,并为 b 和 w1 生成新值。现在,假设这个神秘的绿色框会产生新值,然后机器学习系统将根据所有标签重新评估所有特征,为损失函数生成一个新值,而该值又产生新的参数值。这种学习过程会持续迭代,直到该算法发现损失可能最低的模型参数。通常,您可以不断迭代,直到总体损失不再变化或至少变化极其缓慢为止。这时候,我们可以说该模型已收敛。
梯度下降法:
假设我们有时间和计算资源来计算 w1的所有可能值的损失。对于我们一直在研究的回归问题,所产生的损失与 w1 的图形始终是凸形。换言之,图形始终是碗状图,如下所示:
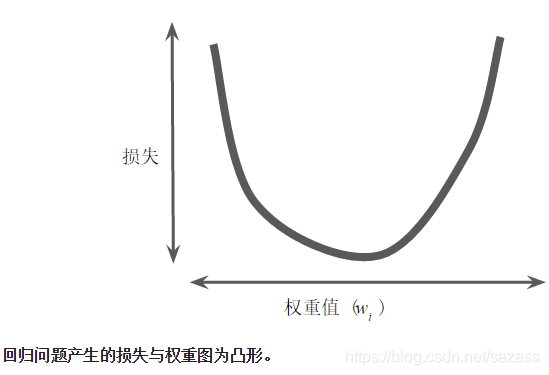
凸形问题只有一个最低点;即只存在一个斜率正好为 0 的位置。这个最小值就是损失函数收敛之处。
通过计算整个数据集中 w1 每个可能值的损失函数来找到收敛点这种方法效率太低。我们来研究一种更好的机制,这种机制在机器学习领域非常热门,称为梯度下降法。
(注:梯度下降法只适用于凸形,只有一个最低点;但有许多网络,例如神经网络就不是凸型,会有多个极小值,不可使用梯度下降法来解决)
梯度下降法的第一个阶段是为 w1 选择一个起始值(起点)。起点并不重要;因此很多算法就直接将 w1 设为 0 或随机选择一个值。下图显示的是我们选择了一个稍大于 0 的起点:
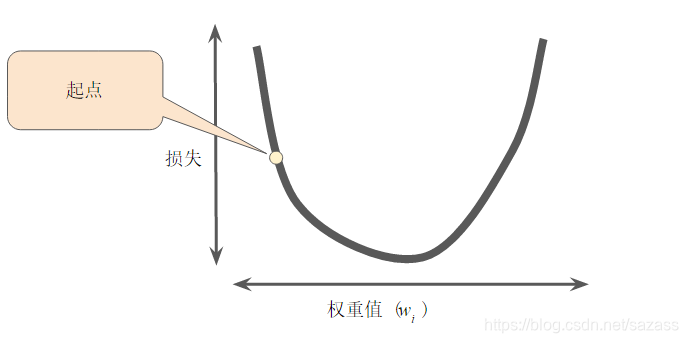
然后,梯度下降法算法会计算损失曲线在起点处的梯度。简而言之,梯度是偏导数的矢量;它可以让您了解哪个方向距离目标“更近”或“更远”。请注意,损失相对于单个权重的梯度(如图 3 所示)就等于导数。
梯度作为一个矢量,具有两点特征:大小,方向
梯度始终指向损失函数中增长最为迅猛的方向。梯度下降法算法会沿着负梯度的方向走一步,以便尽快降低损失。
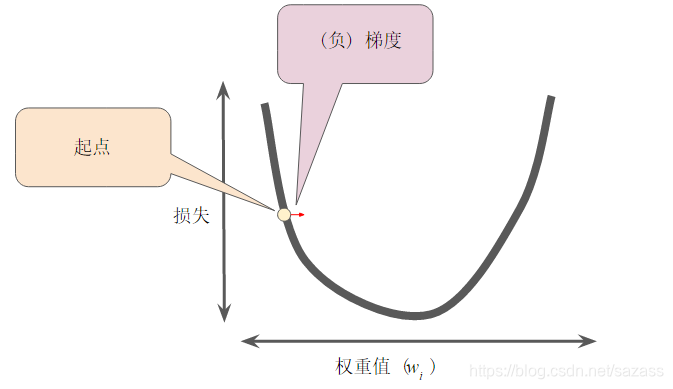
为了确定损失函数曲线上的下一个点,梯度下降法算法会将梯度大小的一部分与起点相加,如下图所示:
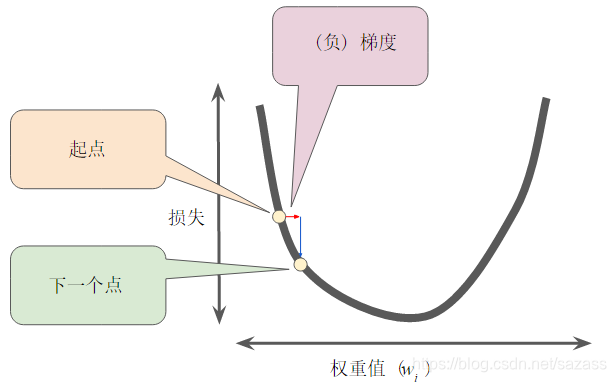
然后,梯度下降法会重复此过程,逐渐接近最低点。
学习速率:
梯度矢量具有方向和大小,梯度下降法算法用梯度乘以一个称为学习速率(有时也称为步长)的标量,以确定下一个点的位置。例如,如果梯度大小为 2.5,学习速率为 0.01,则梯度下降法算法会选择距离前一个点 0.025 的位置作为下一个点。
如果您选择的学习速率过小,就会花费太长的学习时间:
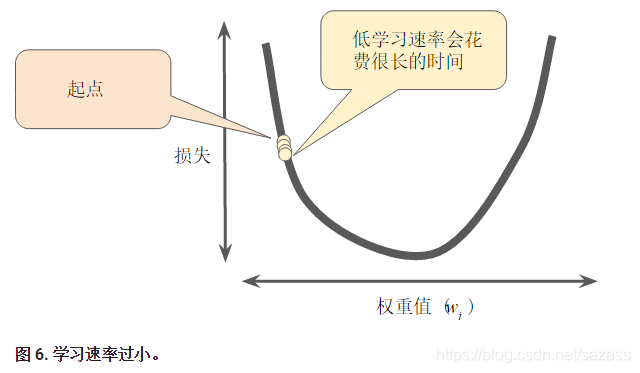
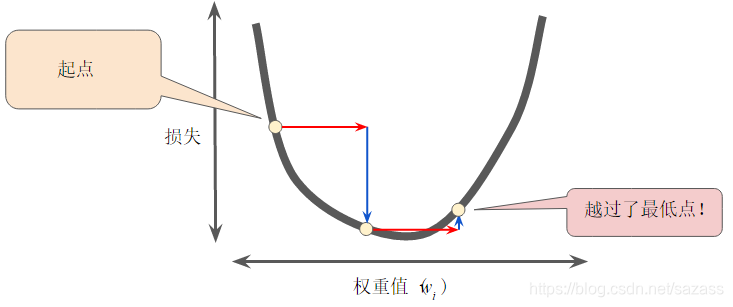
相反,如果您指定的学习速率过大,下一个点将永远在 U 形曲线的底部随意弹跳,就好像量子力学实验出现了严重错误一样:
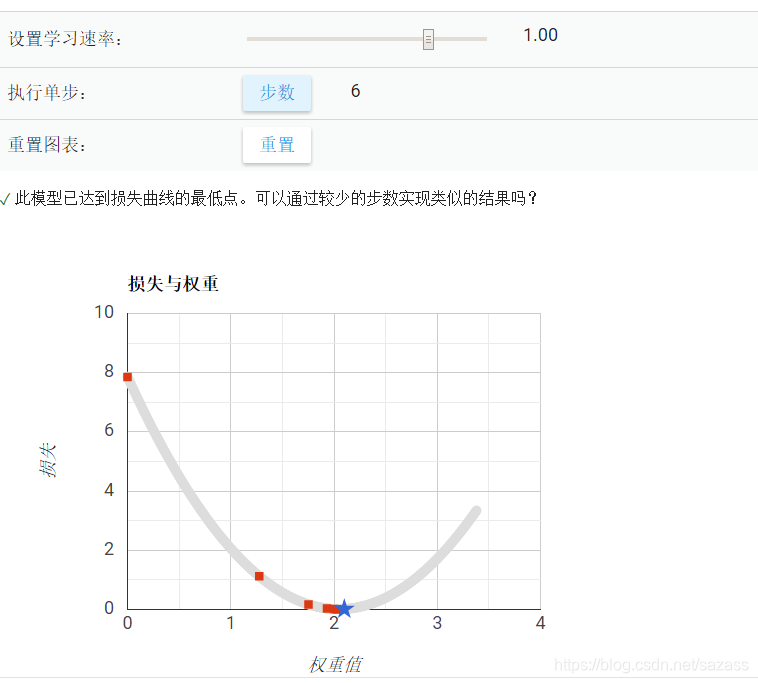
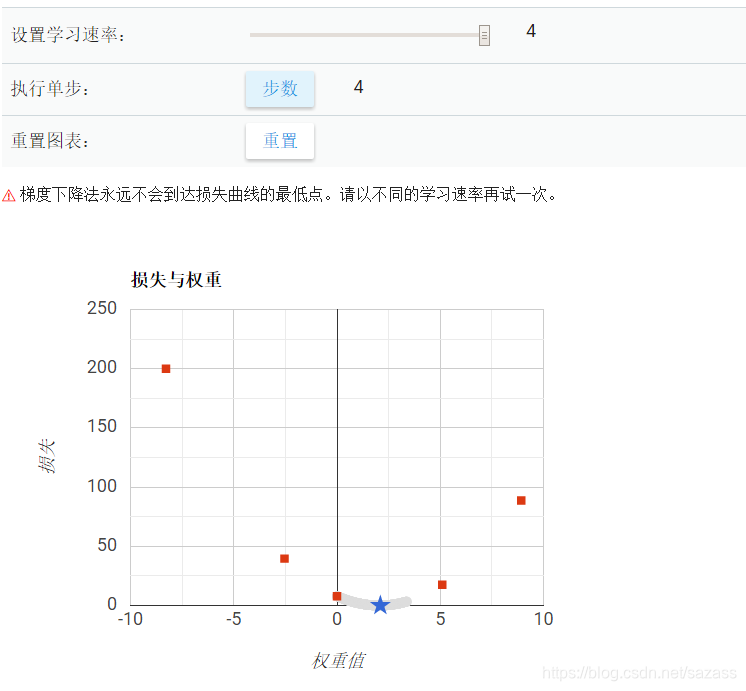
以下是教程自带的梯度下降法的模拟
学习速率0.1:

学习速率1.0
学习速率4.0
效率优化:
面对大量的样本,在每步上计算整个数据集的梯度,可能会造成大量计算,因此可以:
随机梯度下降法(SGD): 每次迭代只使用一个随机样本;
小批量随机梯度下降法: 介于全批量迭代与SGD的折中,通常每次迭代为10~1000个随机样本;