版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/rosefun96/article/details/85724079
背景
这是Google17年的论文,提出了nlp领域的无监督模型。
之前针对图像识别、语音识别、翻译等不同的工作,需要不同的模型,谷歌提出这个模型来,一口气搞定了图像识别、图像分类和多语言翻译。

1 模型
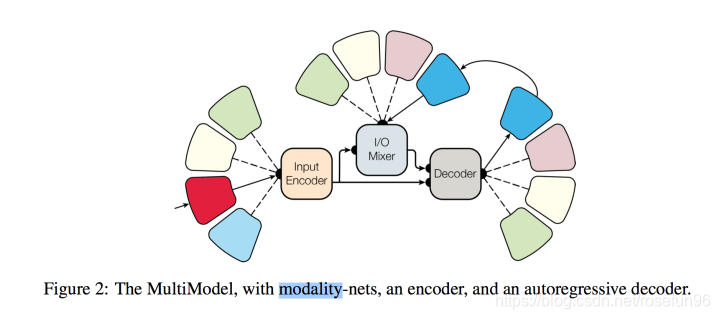
MultiModel由三部分组成:模式网络,编码器,自回归编码器。
编码和解码使用了卷积、注意层、稀疏门控层等计算模块。
(1)卷积层可以检测局部模式特征;
(2)注意力机制层可以关注特定元素;
(3)稀疏门控混合专家提供计算容量并不增加过多计算成本。
1.1 卷积层
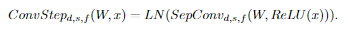

就普通卷积层,没看出什么特别
1.2 Attention层
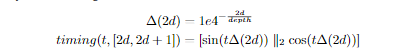
Google之前提出的一个网络结构,这篇论文也没有过多描述。
1.3 混合专家层
稀疏门控混合专家层有许多简单的门控神经网络(专家)和可训练的门控网络组成。
1.4 编码解码层
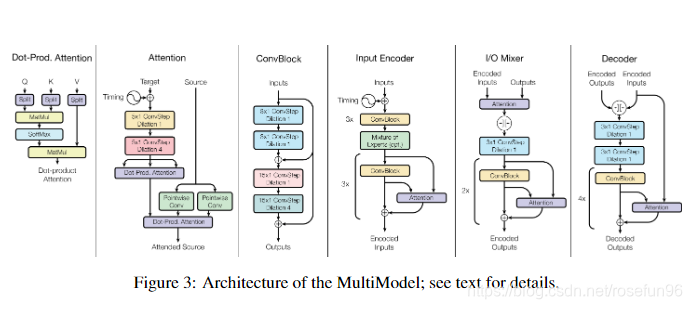
2 总结
看了这篇论文,出发点真的太棒了,解决多模态问题,Google nlp的BERT模型思想也和这个类似,就让模型自动学习,不管语料是哪方面的。但这篇文章真的很难读懂。最近看了一些论文,缺乏实践,理解不够,可能以后读一篇论文还是尽量实践一下。