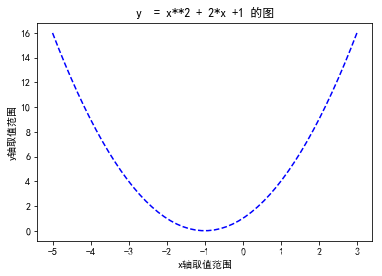
曲线图— 画出 y=x2+2x+1y=x2+2x+1 在区间[-5,3]的函数图像。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
x = np.linspace(-5,3)
y = x**2 +2*x +1
plt.plot(x,y,'b--')
plt.xlabel('x轴取值范围')
plt.ylabel('y轴取值范围')
plt.title('y = x**2 + 2*x +1 的图')
plt.show()
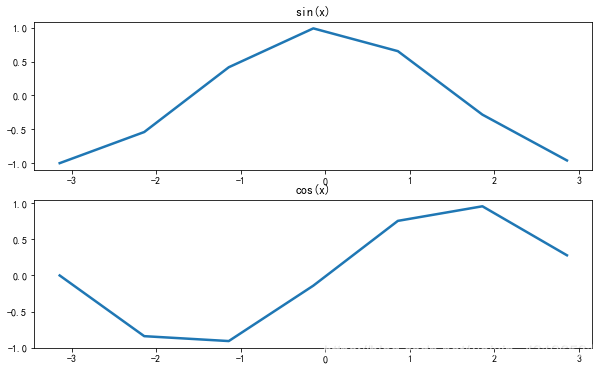
折线图—在同一张图中创建两个子图,分别画出sinx和cosx在[-3.14,3.14]上的函数图像。设置线条宽度为2.5.
plt.figure(figsize = (10,6))
plt.subplot(211)
x = np.arange(-np.pi,np.pi)
y1 = np.cos(x)
y2 = np.sin(x)
plt.plot(x,y1,linewidth = 2.5)
plt.title('sin(x)')
plt.subplot(212)
plt.plot(x,y2,linewidth = 2.5)
plt.title('cos(x)')
plt.show()
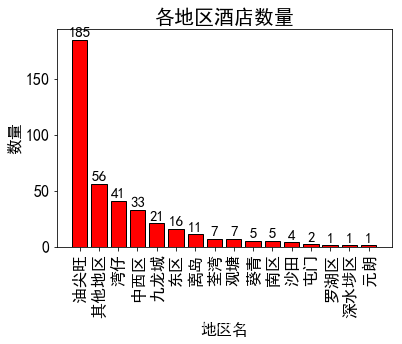
柱形图—每个地区酒店数量
data = pd.read_excel('酒店数据2.xlsx')
df = data['地区'].value_counts()
df.values+10
plt.bar(df.index,df.values,color = 'r',edgecolor = 'k')
plt.title('各地区酒店数量',fontsize = 20)
plt.xlabel('地区名',fontsize = 16)
plt.ylabel('数量',fontsize = 16)
plt.tick_params(labelsize = 16)
plt.xticks(rotation = 90)
for x,y in zip(df.index,df.values):
plt.text(x,y+1,y,ha = 'center',va = 'bottom',fontsize = 15)
plt.show()
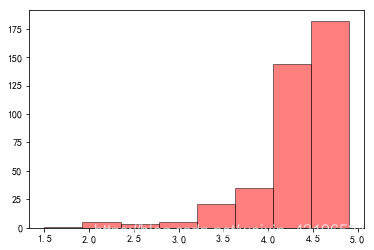
直方图—酒店评分
df2 = data['评分']
plt.hist(df2,bins = 8,facecolor = 'r',edgecolor = 'k',alpha = 0.5)
plt.show()
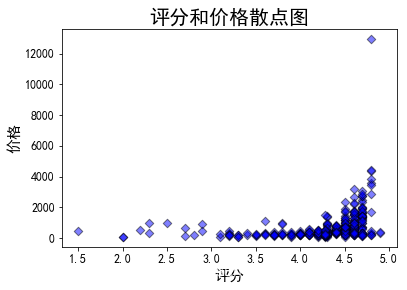
散点图—评分和价格
d1 = data['评分']
d2 = data['价格']
plt.scatter(d1,d2,marker = 'D',color = 'b', edgecolor = 'k', alpha = 0.5)
plt.title('评分和价格散点图', fontsize = 20)
plt.xlabel('评分', fontsize = 15)
plt.ylabel('价格', fontsize = 15)
plt.tick_params(labelsize = 12)
plt.show()
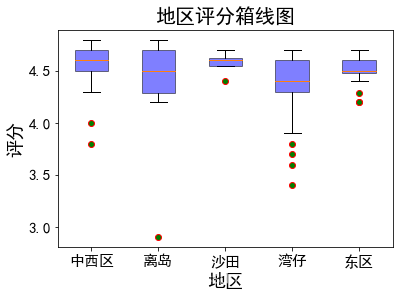
箱线图—平均价格前5的地区评分
d4 = data['价格'].groupby(data['地区']).mean()
d4 = d4.sort_values(ascending= False)
d4 = d4[:5]
v1 = data[data.地区 == '中西区']['评分']
v2 = data[data.地区 == '离岛']['评分']
v3 = data[data.地区 == '沙田']['评分']
v4 = data[data.地区 == '湾仔']['评分']
v5 = data[data.地区 == '东区']['评分']
plt.boxplot((v1, v2, v3, v4, v5),labels = ['中西区' ,'离岛', '沙田', '湾仔', '东区'], patch_artist = True,
boxprops = {'facecolor':'b','edgecolor':'k','alpha': 0.5},
flierprops = {'markerfacecolor':'g','markeredgecolor':'r', 'marker': 'o'})
plt.tick_params(labelsize = 15)
plt.xlabel('地区',fontsize = 18)
plt.ylabel('评分', fontsize = 18)
plt.title('地区评分箱线图',fontsize = 20)
plt.show()
饼图—各个价格等级占比
df1 = data['等级'].value_counts()
df1 = df1.sort_index()
m = df1.values
plt.figure(figsize = (5,5))
patches,l_text,p_text = plt.pie(m, labels = ['A','B','C'],autopct = '%.2f %%')
for i in p_text:
i.set_size(14)
i.set_color('w')
for i in l_text:
i.set_size(14)
i.set_color('r')
plt.legend()
plt.show()

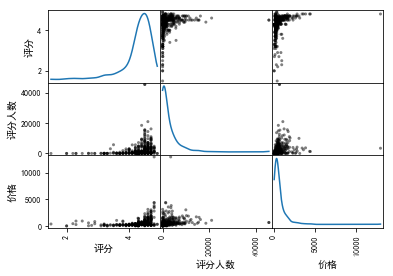
相关系数图—评分,评分人数和价格
df = data[['评分', '评分人数', '价格']]
result = pd.scatter_matrix(df,diagonal = 'kde', color = 'k')
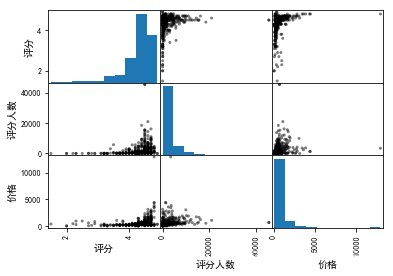
result1 = pd.scatter_matrix(df,diagonal = 'hist', color = 'k')
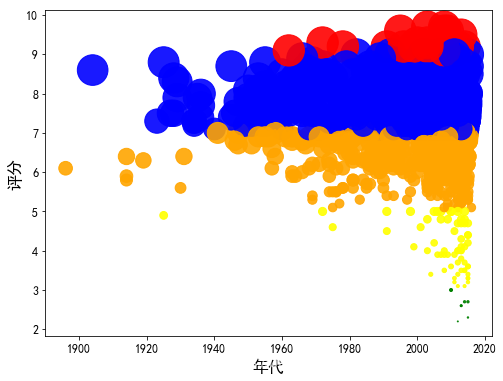
气泡图—年代,评分和评分等级
data = pd.read_excel('movie_data3.xlsx')
data[data.年代 == '2008\u200e']
data.drop(15203, inplace = True)
size = dat0['评分'].rank()
n = 1
plt.figure(figsize = (8, 6))
color = {'A':'red', 'B':'blue','C':'orange', 'D':'yellow', 'E':'green'}
plt.scatter(dat0['年代'], dat0['评分'], color = [color[i] for i in dat0['评分等级']], s = size * n, alpha = 0.9)
plt.xlabel('年代', fontsize = 16)
plt.ylabel('评分', fontsize = 16)
plt.tick_params(labelsize = 12)
plt.show()
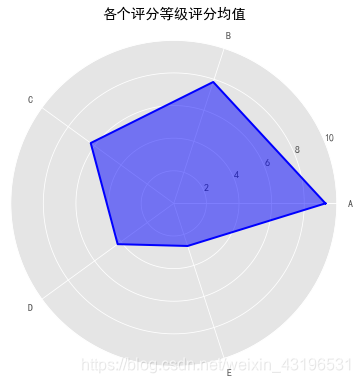
雷达图—各个评分等级评分均值
plt.style.use('ggplot')
mean = pd.pivot_table(data, values = '评分', index = '评分等级')
rate = mean['评分']
values = rate.values
feature = rate.index
N = len(values)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
values = np.concatenate((values,[values[0]]))
angles = np.concatenate((angles,[angles[0]]))
plt.figure(figsize = (8,6))
plt.subplot(111, polar=True)
plt.plot(angles, values, 'b-', linewidth = 2)
plt.fill(angles, values,'b', alpha = 0.5)
plt.thetagrids(angles * 180/np.pi, feature)
plt.ylim(0,10)
plt.title('各个评分等级评分均值')
plt.grid(True)
plt.show()
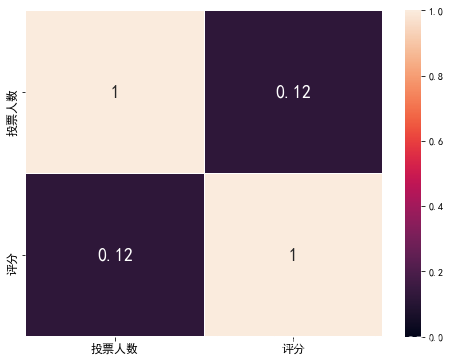
热力图—评分和投票人数
data[data.时长 == '8U']
data[data.时长 == '12J']
data.drop([31636, 32941], inplace = True)
import seaborn as sns
data1 = data[['年代', '产地', '名字', '投票人数', '类型', '上映时间', '时长', '评分', '首映地点', '评分等级',
'热门程度']]
correction = data1.corr()
correction = abs(correction)
fig = plt.figure(figsize = (8,6))
ax = fig.add_subplot(figsize = (20,20))
ax = sns.heatmap(correction, linewidth = 0.05, vmax = 1, vmin = 0, annot = True, annot_kws = {'size': 18, 'weight': 'bold'})
plt.xticks(fontsize = 12)
plt.yticks(fontsize = 12)
plt.show()
词云图—红楼梦
import jieba
from wordcloud import WordCloud
f = open('F:\\二级python\\行文代码\\第10章\\红楼梦1.txt', encoding='gb18030', errors = 'ignore')
txt = f.read()
f.close()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word)== 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key = lambda x :x[1], reverse = True)
for i in range(15):
word, count = items[i]
print('{0:<10}{1:>5}'.format(word, count))
excludes = {'什么', '一个', '我们', '那里', '你们', '如今', '说道', '知道',
'老太太', '起来', '姑娘', '这里', '出来', '他们', '众人','自己',
'一面', '太太', '只见', '怎么', '奶奶', '两个', '没有', '不是',
'不知', '这个', '听见'}
for word in excludes:
del(counts[word])
from scipy.misc import imread
mask = imread('爱丽丝.png')
newtxt = ''.join(words)
wordcloud = WordCloud(background_color = 'white', width = 800, height = 600,font_path = 'msyh.ttc',max_words = 200, max_font_size = 80,stopwords = excludes, mask = mask).generate(newtxt)
wordcloud.to_file('红楼梦基本词云.png')
