混淆矩阵
从混淆矩阵出发,再看各项性能评价指标就一目了然了。
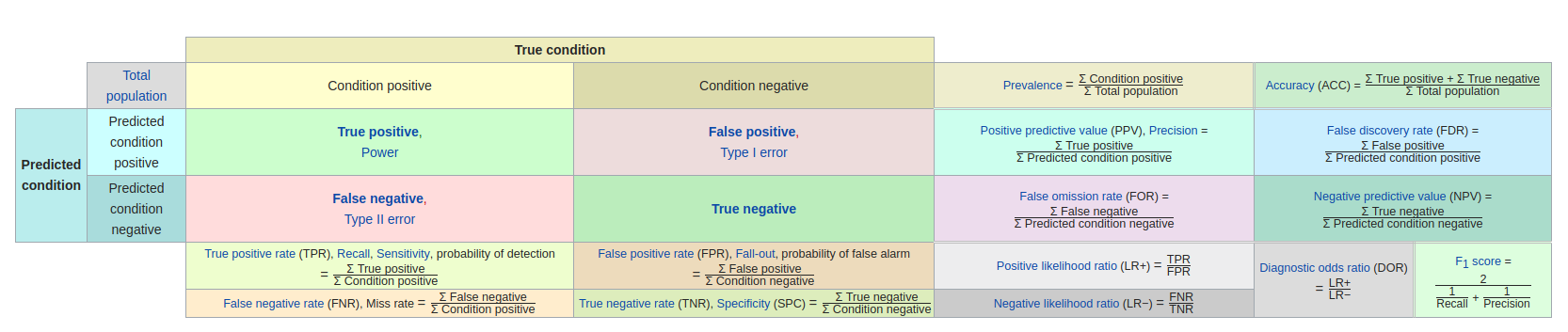
1)True positives(TP): 被正确分类到正样本的样本数量,即所预测的正样本中,真实的正样本的数量;
2)False positives(FP): 被错误分类到正样本的样本数量,即所预测的正样本中,实际上是负样本的样本数量;
3)False negatives(FN): 被错误分类到负样本的样本数量,即所预测的负样本中,实际上是正样本的样本数量;
4)True negatives(TN): 被正确分类到负样本的样本数量,即所预测的负样本中,真实的负样本的样本数量。
5)Condition positive(CP): True positive+False negative,实际上的正样本数量(数据集中真实的正样本数量)。
6)Condition negative(CN): False positive+True negative,实际上的负样本数量(数据集中真实的负样本数量)。
7)Predicted condition positive(PCP): True positive+False positive,所预测的负样本数量。
8)Predicted condition negative(PCN): False negative+True negative,所预测的负样本数量。
1. Recall、True positive rate (TPR)、Sensitivity
首先看公式,Recall就是所有被正确预测为正样本的样本数量与真实的正样本的总数量的比值。Recall又叫做召回率,意思就是说在所有的正样本中,被正确找出来的样本的比例。
2. Precision、Positive predictive value (PPV)
Precision叫做精确度或者精度,表示在所有预测为正样本的数据中,有多少是真正的正样本。
3. Accuracy (ACC)
Accuracy叫做准确度,表示在所有的样本数据中,有多少是被正确预测的(包括正样本和负样本)。
4. F-measure、F-score
F-measure又叫F值,是对Precision和Recall的加权调和平均。
5. F1-score
F1-score 叫做F1值或者F1得分,是当
=1的时候的F值。F1值综合了P和R的结果,当F1较高时能说明实验方法比较有效。
6. Average Precision (AP)
顾名思义,就是Precision的平均值。由于Precision是相对于每一类样本个体去单独计算的,那么Average Precision就是对多个个体计算出的这些Precison进行加权平均(对应的Recall值作为权重)。
7. Mean Average Presicion (mAP)
Mean Average Presicion就是将不同类别所计算出的AP值取平均。
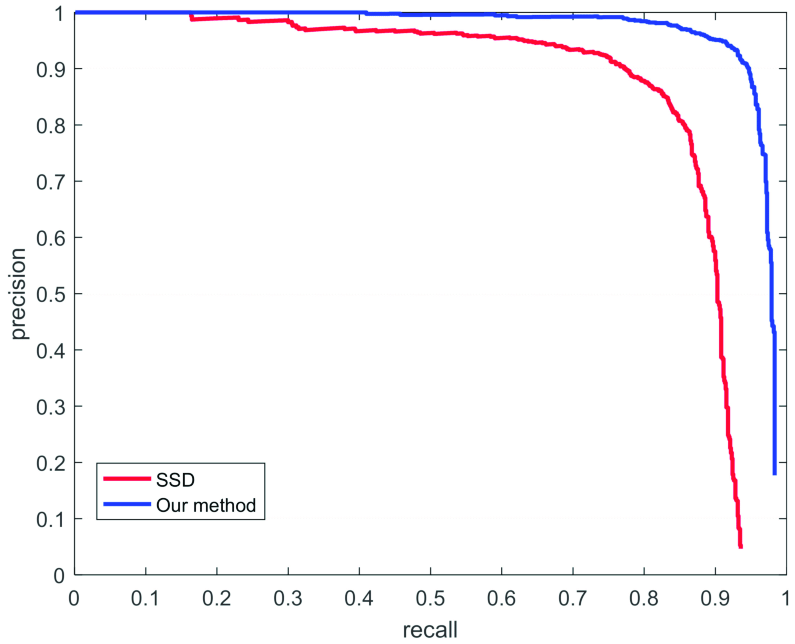
8. Precision-Recall curve
P-R曲线是以Precision为纵坐标、Recall为横坐标的二维曲线。当类间非常不平衡的时候,P-R曲线是判断模型是否有效的一个非常有用的标准。P-R曲线的面积即为AP值。
其中,曲线上对应的Recall值即为权重Pn 。
9. Intersection-over-Union (IoU)
Intersection-over-Union又叫做交并比,常用作目标检测领域的度量标准(也可用于图像的语义分割)。废话不多说,直接上图:
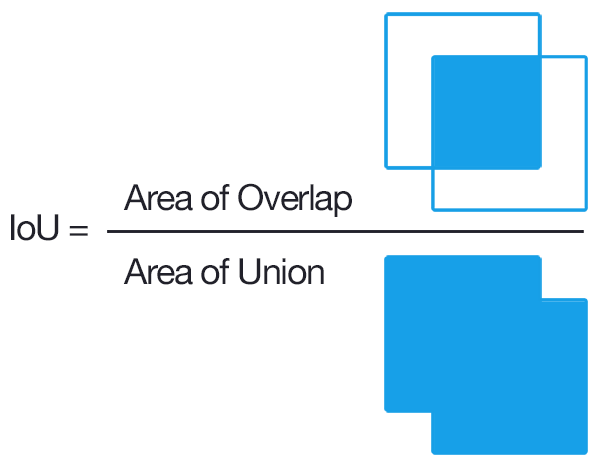
直观来说,就是模型所预测的目标区域与Ground Truth中所标注的真实区域的交并比。
10. Mean Intersection-over-Union (mIoU)
很好理解,就是计算不同类别的IoU的(可加权)平均值。
11. Macro Average vs Micro Average
宏观度量指标(Accuracy、Precision、Recall)为每个类独立计算度量,然后再取平均值(因此平均处理所有类),而微观平均值将聚合所有类的贡献以计算平均度量。在多分类问题中,如果存在类不平衡问题(如某个类的样本数量远多于其他类的样本数量),可以采用微观平均度量。
举个例子,假设有A、B、C、D四个类存在,每个类别的测试结果如下:
1)Class A: 1 TP and 1 FP
2)Class B: 10 TP and 90 FP
3)Class C: 1 TP and 1 FP
4)Class D: 1 TP and 1 FP
根据Precision的计算公式:
,很容易计算出
.
根据宏观平均值的计算方法可以得到
根据微观平均值的计算方法可以得到
两种计算方式算得的结果相差较大。在宏观平均中,A、C、D类具有良好的精度(0.5),使得整体的精度看上去还行(0.4)。但是还有大量的样本没有被正确的分类。这些样本主要来源于B类,B类样本构成了94.3%的测试数据,但它们对整个平均值的贡献只有1/4,这是不合理的。而微观平均值能充分的捕捉到这种类间不平衡的存在,并使整体的精度平均值下降到0.123,这个数据与测试的主体数据B的精度等级(0.1)更接近,也更加合理。
出于计算的原因,有时候先计算类平均值,然后再进行宏观平均更加方便。如果已知类间不平衡问题的存在,有几种方法可以解决这个问题。一种是不仅计算宏观平均值,还计算其标准偏差(对于多分类问题)。另一种方法是对宏观平均的每一项进行加权,每一类对平均值的贡献和其样本所占的比例有关。具体如下:
从较大的标准偏差(0.173)可知,所计算的平均值0.4不是来源于类之间的统一精度,但是相对来说,会比计算加权的宏观平均值要容易一些,加权的宏观平均值本质上是微观平均值的另一种计算方法。
如有错误,欢迎指正!!!
参考资料:
f-measure
Precision-Recall
Intersection over Union (IoU) for object detection
Micro Average vs Macro average Performance in a Multiclass classification setting
深度学习笔记(八):目标检测性能评价指标(mAP、IOU…)