一. 递归的二分法
例如:判断数据是不是在lst中
方法1:
当一次判断不能出结果,需要把所有结果迭代完,需要for和else并列
如果数据特别多,非常浪费时间.
lst=[1,11,21,34,38,59,657,954]#如果十亿级的数不使用二分法数据处理量就非常大 n=int(input("请输入一个n:")) for el in lst: if n==el: print("找到了") break else: print("没有找到")
2.用二分法就简单了
原则:掐头结尾整除找中间,出口左边比右边大.
缺点:前提是个有序序列
执行流程:目标数和中间数对比,大于向右找,小于向左找,这是就删除了一半,然后再运用二分法,对比中间值,就能逐渐找到,效率就大大提高了.
3.具体算法:
非递归算法
lst=[1,11,21,34,38,59,657,954]#如果十亿级的数不使用二分法数据处理量就非常大 n=int(input("请输入一个n:")) left=0 right=len(lst)-1 while left<=right: mid=(right+left)//2 if n>lst[mid]: left=mid+1 elif n<lst[mid]: right=mid-1 else: print("找到了") break else: print("没有找到数据")
二分法:优点快,缺点:有序序列
3.冒泡排序(bubble sort):
前面和后面的比较,如果前面的比后面的大就互换.每次轮换出最大的数
具体编程实现:
Python的互换很简单,
冒泡排序的具体编程如下:
a=10 b=20 a,b=b,a print(a,b)
lst=[32,25,64,95,86,54,7,655,64,94,852]#给定无序列表 for i in range(len(lst)-1): if lst[i]>lst[i+1]: lst[i],lst[i+1]=lst[i+1],lst[i] print(lst)
二.random随机数
1.切记文件名和用的模块最好不要是一样的

2.random封装了一系列的随机算法
import random
3.最核心的逻辑
random.random#默认区间[0,1]随机数的祖宗.
可以帮我获取一个随机数,没有任何规律.
3.随机整数:random.randint(10,20)#包括10和20.
例如:36选7,不能重复(可以用set去重)
import random s=set() while len(s)<7: s.add(random.randint(1,36)) print(s)
4.random.uniform(10,20)#10-20之间的随机小数.
import random print(random.random())#[0,1]的随机数 print(random.uniform(10,20))#10-20之间的随机小数 print(random.randint(10,20))#10到20之间的随机整数
例如:从列表中随机选取一个,
4.random.choice(lst)随机选出1个
5.random.sample(lst,2)随机选取n个
6.随机打乱列表:random.shuffle(lst)
import random lst=[32,25,64,95,86,54,7,655,64,94,852] print(random.choice(lst))#随机选出1个 print(random.sample(lst,2))#随机宣传2个 print(random.shuffle(lst))#随机打乱列表
三.time:关于时间的
import time#引入时间
1.获取当前系统时间戳:time.time#获取的时间戳.从1970-01-01.00:00:00开始计算的秒数.
这个时间不是给人看的,这是给机器看的.
2.格式化时间:
time.strftime(“%Y-%m-%d %H:%M:%S”)f:format格式化,这个时间只是给人看的,是一个字符串.
美国是按照周发放工资的.
%z中国是东8区,中国应该从8点开始.
算时间差,扣除8小时.+8000
3.结构化时间:这才会说Python真正的时间.
time.localtime(),这是非常重要的作用,可以把时间转化.
import time print(time) print(time.strftime("%Y-%m-%d %H:%M:%S")) print(time.localtime())#time.struct_time(tm_year=2019, tm_mon=1, tm_mday=29, tm_hour=13, tm_min=3, tm_sec=53, tm_wday=1, tm_yday=29, tm_isdst=0)
4.把一个数字转成成格式化时间(重点).
时间戳à结构时间à格式化时间
import time n=1800000000 '''第一步:转化成机构化时间''' struct_time=time.localtime(n) print(struct_time) '''第二步结构化时间转化格式化时间''' s=time.strftime("%Y-%m-%d %H:%M:%S",struct_time) print(s)
5.把人能看懂的时间转化成à时间戳(重点)
(1)把格式化时间转化成结构化时间:
#格式化时间à机构化时间à时间戳
import time '''(1)把格式化时间转化成结构化时间:''' n=input("请输入一个时间(yyyy-mm-dd)") struct_time=time.strptime(n,"%Y-%m-%d") print(struct_time) '''(2)把结构化时间转化成时间戳:time.mktime()''' s=time.mktime(struct_time) print(s)
6.时间差的计算à针对小时来计算
比如打台球的小时计费
'''台球计时器''' import time '''输入两个时间''' s1=input("开始时间(yyyy-mm-dd HH:MM:SS)") s2=input("结束时间(yyyy-mm-dd HH:MM:SS)") '''把这两个时间转化成时间戳''' struct_time1=time.strptime(s1,"%Y-%m-%d %H:%M:%S") struct_time2=time.strptime(s2,"%Y-%m-%d %H:%M:%S") t1=time.mktime(struct_time1) t2=time.mktime(struct_time2) '''计算时间差:取绝对值:是秒级别的时间差,需要转化成小时.''' diff_n=abs(t1-t2) '''把秒转化成分钟''' diff_min=diff_n//60 '''把分钟转化成小时''' diff_hour=diff_min//60 diff_fen=diff_min%60 print("使用时间:%s小时,%s分钟" %(diff_hour,diff_fen) )
四.sys:Python的系统àPython的有关路径的内容
sys.argv:在启动Python的时候给Python传递的信息.Python是无法看到结果的.

sys.exit()#能直观的看到程序是否报错,跟操作系统沟通的
import sys print(1/0) sys.exit()
sys.verson查看Python的
sys.platform#没用
sys.path 模块搜索路径
默认的路径:先找当前路径,然后找Python中找.不会找Python之外的路径.可以利用sys.path来查找sys.path.append或insert
sys.path 模块搜索路径
默认的路径:先找当前路径,然后找Python中找.不会找Python之外的路径.可以利用sys.path来查找sys.path.append或insert
千万不要clear()
练习:文件复制à写函数,给两个参数.两个文件庐江.把文件从a复制到b.
'''文件复制''' '''之前的复制方法''' def copy(a,b): import os f1=open(a,mode="rb") f2=open(b,mode="wb") for line in f1: f2.write(line) f1.close() f2.flush() f2.close() copy("C:/untitled/day05/as.jpeg","C:/untitled/day06/abs.jpeg")#Permission denied: 'c:/untitled/day06' '''这个方法存在问题 这个有bug,如果b的路径不存在报错.需要对b 进行判断.''' def copy(a,b): import os p_name=os.path.dirname(b) if not os.path.exists(p_name): os.makedirs(p_name) f1 = open(a, mode="rb") f2 = open(b, mode="wb") for line in f1: f2.write(line) f1.close() f2.flush() f2.close() copy("c:/untitled/day05/as.jpeg","c:/untitled/day06/abs.jpeg")
五.os 操作系统à
1.os.makedirs创建文件夹,用”/”可以创建多层目录.
os.mkdir(“张小斐/贾玲/666”):也能创建文件夹,但上级文件必须存在.
2.os.removedirs()#从内向外删除,删了一层后,判断上级是否空,如果为空也删除.
os.rmdir()#只有最后的一层路径被删除了.
import os os.makedirs("胡一菲/张一山/杨紫") os.mkdir("胡一菲/666") os.removedirs("胡一菲/张一山/杨紫") os.rmdir("胡一菲/张一山/杨紫")
一般应用这个.
3.os.listdir(“胡一菲”)#可以获取某个文件夹内的文件夹名字.
4.os.stat(“”)#可以看到文件的目录信息,比如创建时间\文件大小等.
5.os.system(“”)#运行shell命令,直接显示.
6.os.popen(“dir”).read#运行shell命令,并获取结果.
7.os.getcwd()#获得当前工作目录,即当前Python脚本的工作目录.
8.os.chdir#更换程序工作目录,后面的文件就从这个文件开始查找

9.os.abspath()#返回一个相对路径的绝对路径.
os.path.split()#把最后一个文件(“文件夹”,文件)
os.path.dirname#拿到文件上层目录
os.path.basename#拿到的是当前文件名字
10.os.path.exists()#判断是否存在
os.path.isfile()#判断是否是文件
os.path.isdir()#判断是不是文件夹
os.path.isabs()#是不是绝对路径
11.文件路径的拼接
os.path.join(s,el)拼接文件夹名称.

Linux中”/”和window中”/”不一定相同.
python中os.path.sep和os.sep都等同于/
六.pickle
1.主要作用是序列化:比如一个实体无法通过网线传播,需要拍散了,这个就是序列化,而接受方又组合成实体,这就是反序列化.
序列化:把一个对象拍散成二进制字节的形式,进行数据传输和存储.
反序列化:把二进制字节转化回我们的对象.
2.pickle.dumps()#把数据拍散,成二进制.
反序列化:把字节转化回我们的对象
pickle.loads(bs)
序列化出来的结果à不是给人看的,是给机器看的.
import pickle lst=["大象","猴子","老鼠","大白"] ds=pickle.dumps(lst) print(ds)#b'\x80\x03]q\x00(X\x06\x00\x00\x00\xe5\xa4\xa7\xe8\xb1\xa1q\x01X\x06\x00\x00\x00\xe7\x8c\xb4\xe5\xad\x90q\x02X\x06\x00\x00\x00\xe8\x80\x81\xe9\xbc\xa0q\x03X\x06\x00\x00\x00\xe5\xa4\xa7\xe7\x99\xbdq\x04e.' ls=pickle.loads(ds) print(ls)#['大象', '猴子', '老鼠', '大白']
3.主要操作:把序列化的对象写入到文件中(1)pickle.dump(lst,open())#dump和dumps的区别就是不能写入文件.
把一个数据直接写入到文件中.
(2)读取文件pickle.load(open)
同next
用while循环读取所有的数据,该方式一般.
import pickle lst=["大象","猴子","老鼠","大白"] pickle.dump(lst,open("动物.txt",mode="wb")) # l=pickle.load(open("动物.txt",mode="rb")) # print(l)#['大象', '猴子', '老鼠', '大白'] f=open("动物.txt",mode="rb") while True: try: obj1=pickle.load(f) print(obj1) except EOFError: print("没有数据了") break

把这些数据写入到列表中,统一把列表写文件中.读的时候,主要读取一个就行.

读取该文件

七.json模块是把Python的数据转化成前段使用的json对象.
json:是JavaScript的对象.
就是前端和后端交互的方式.
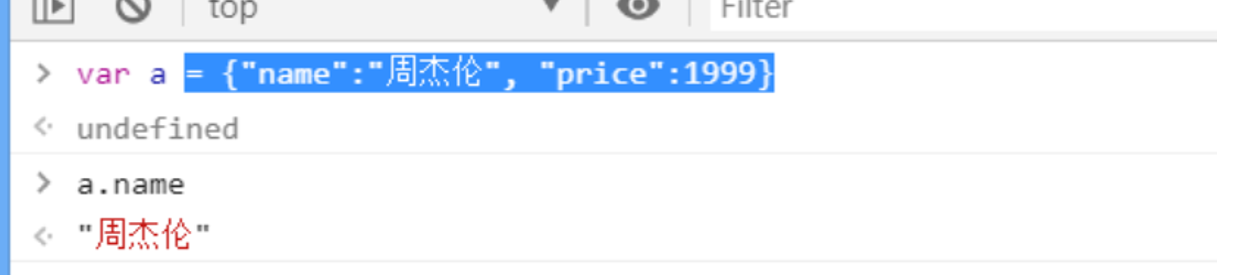
前端就是json
只有一些细微的语法差别.
True和False和None中json中是true\false和null
1.把字典转化成json

ensure_ascii=False#可以会用中文

这段代码就是处理完的json.
2.把json转换成字典

这个模块使用频率非常高.
3.json.dump是可以在文件中写入内容的.需加入.json,json中放入必须是文字的东西,用

json.load读取文件.
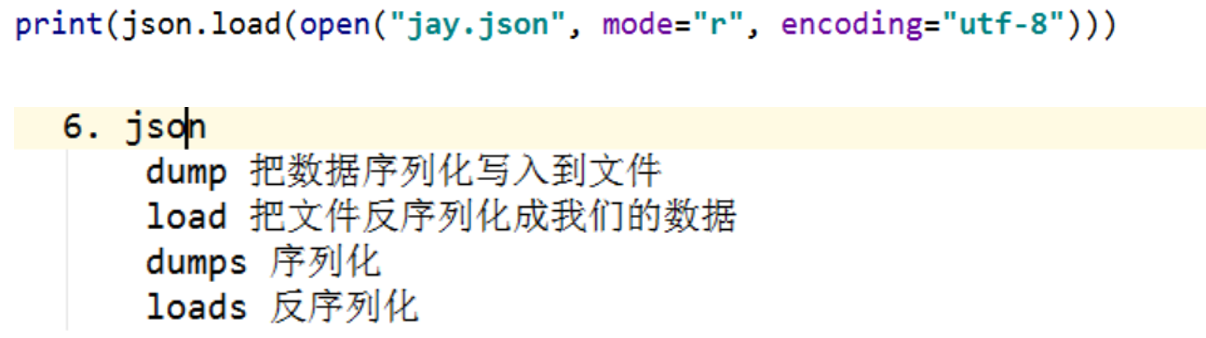
json使用频率最高
pickle的功能比json要强大
json无办法把我们自己创建的对象序列化.
八.shelve提供持久化:数据的形态有种持久态.
内存是瞬态,就是断电就没有了,
硬盘:shelve是对硬盘的持久态.
shelve模式相当于小型数据库,àkey:value 字典.
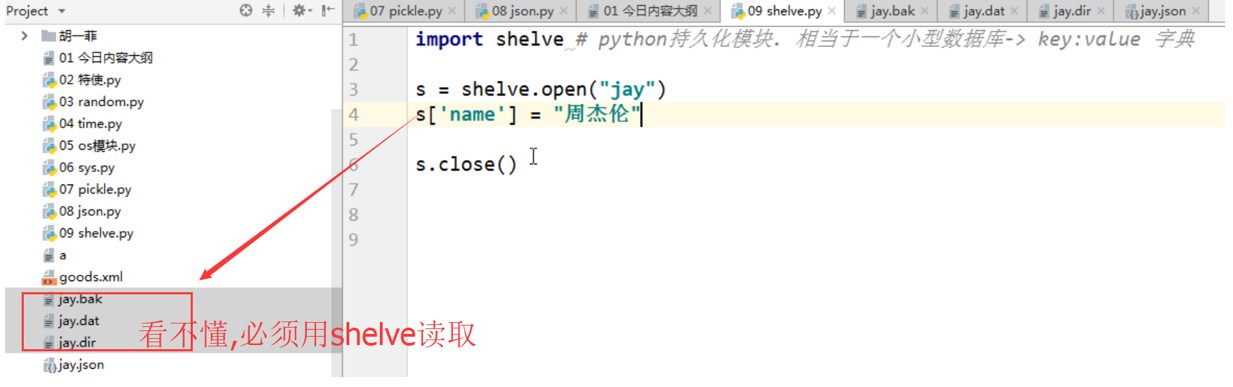
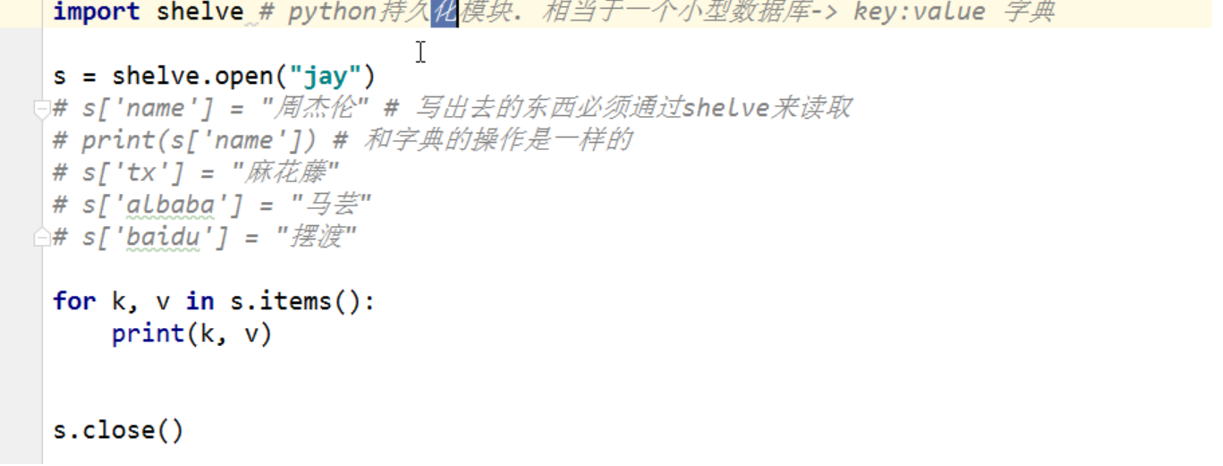
这个操作和字典的操作是一样,完全可以当做字典来用.
九:爬取的作用
后期有关于爬虫的课,还不能爬取百度图片.
后期有浏览器支撑就可以爬取.
dytt,盗版天堂,电影天堂
右键看源代码:比如百度的网站是不好爬取的
如果地址栏经常变更目前也不能直接爬取.新浪网是可以的
没有登录权限的就可以下载.
十.正则表达式:存在的意义就是匹配字符串用的.
比如注册账号,判断其格式
比如控制手机号的首位是1
比如邮箱也是严格限制的
上述案例,都是正则表达式来写的.
是一位一位匹配的
在这个网站可以写正泽
http://tool.chinaz.com/regex/
用这个网站学正泽
比如正泽是abc 匹配结果就是abc
普通字符
在Python匹配字符串
正泽一般是元字符,是正泽表达式的灵魂.
1.字符组
[]用中号表示字符组中的一位一位去匹配,
还能匹配中文.
[a-zA-Z0-9]表示所有的大写字母和数字都能匹配.
. 除换行之外所有东西,基本是无敌的
\w 匹配字母\数字\_ 三个,等同[a-zA-Z0-9_]
\s 匹配任意的空白符 strip()是去空白\t \n 空格
\d 匹配数字[0-9]
\b 作为某个单词的结尾匹配,比如x\b所有以x结尾的单词.
^ 表示整句话的开头,^alex开头必须以alex开头
$ 表示结尾必须alex$,必须以此结尾.
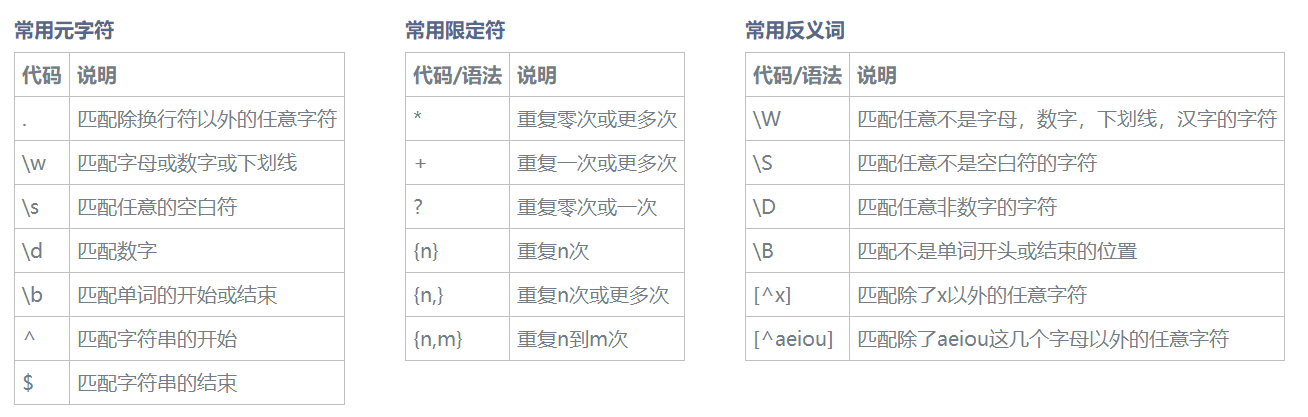
例如:手机号的匹配
少一位多一位都不行.
\W 取\w的相反的文件,即除去
[^a-zA-Z0-9_]
\D 匹配非字符
a|b 匹配a或b
[^]非字符组
() 分组没有讲
3.量词
比如\d+ a+ b+
量词只管最近的元字符出现的次数.
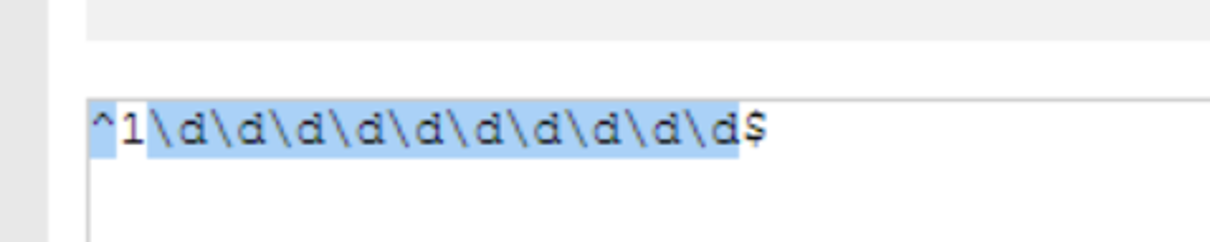
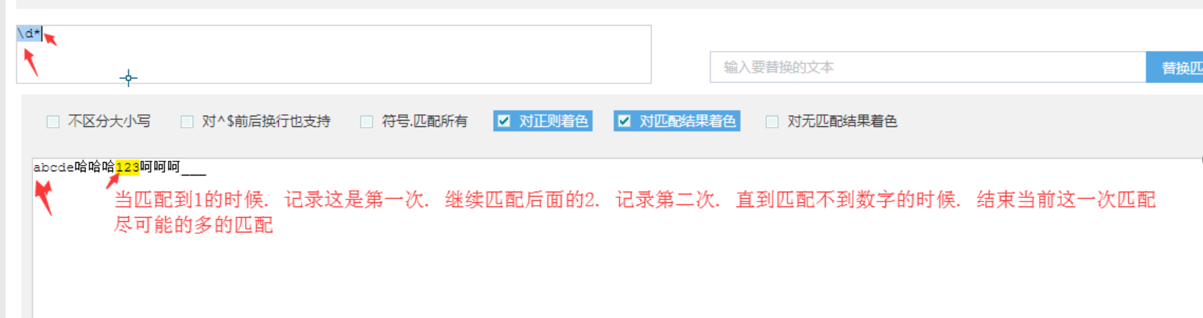
(1) * 表示出现0次或者更多次
有也匹配,没有也匹配,所以出现了18次.
其中很重要的作用:贪婪匹配.尽可能多的匹配.
(1) + 表示重复一次或多次.用的比较多.
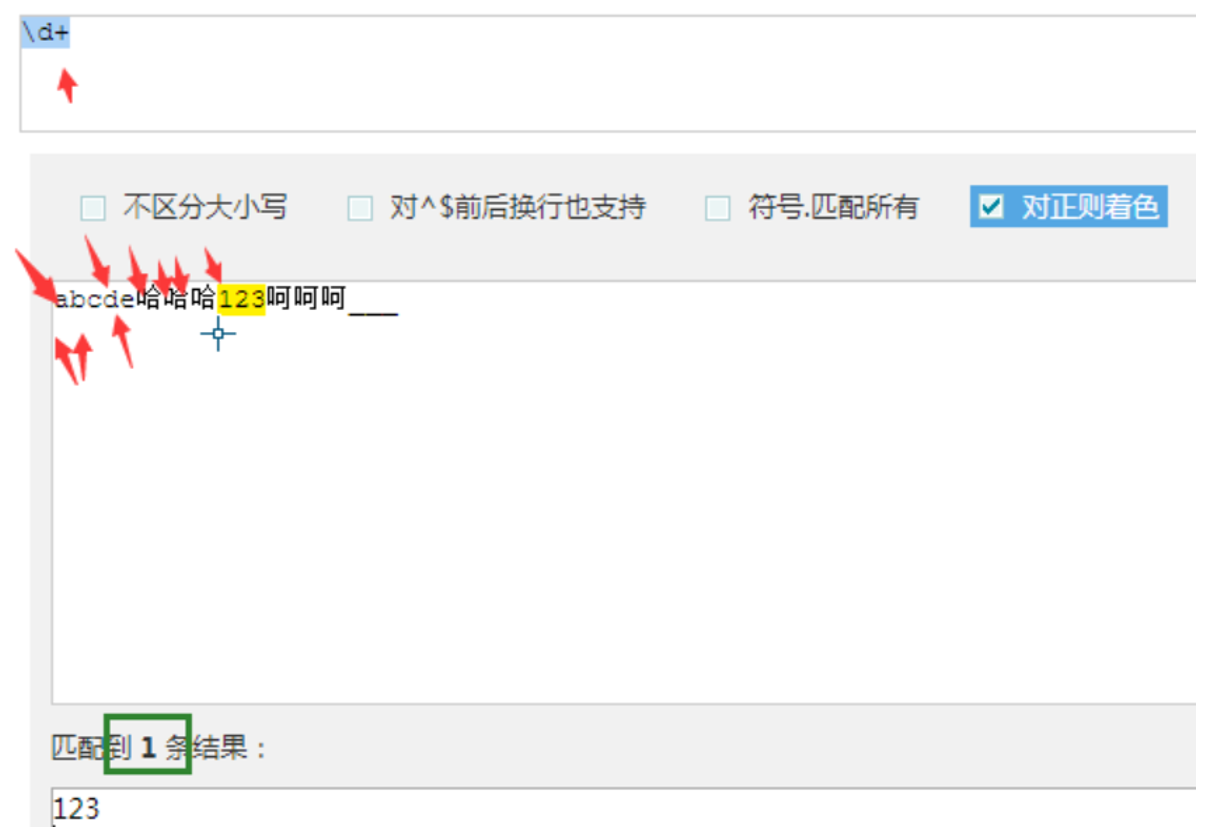
(2) ? 表示重复0次或者1次,偏向的是0次,惰性匹配
(3) {n} {n,}{n,m}重复n次

比如:匹配一个邮箱
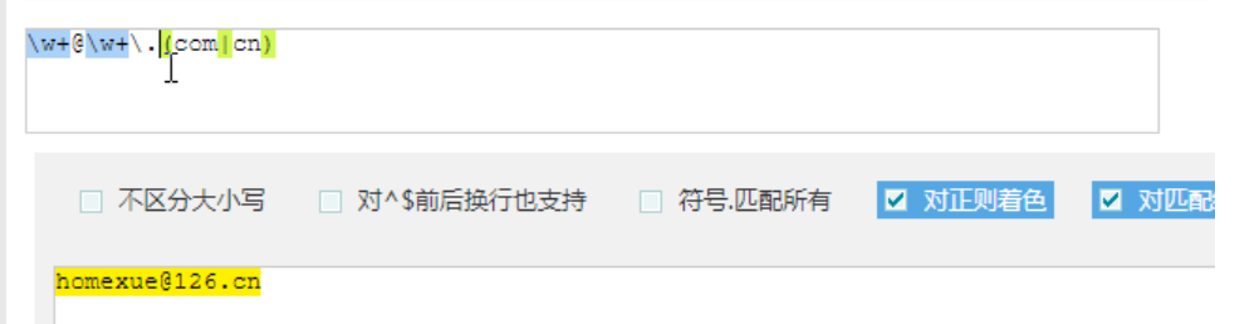
先写一个正确的,然后开始写
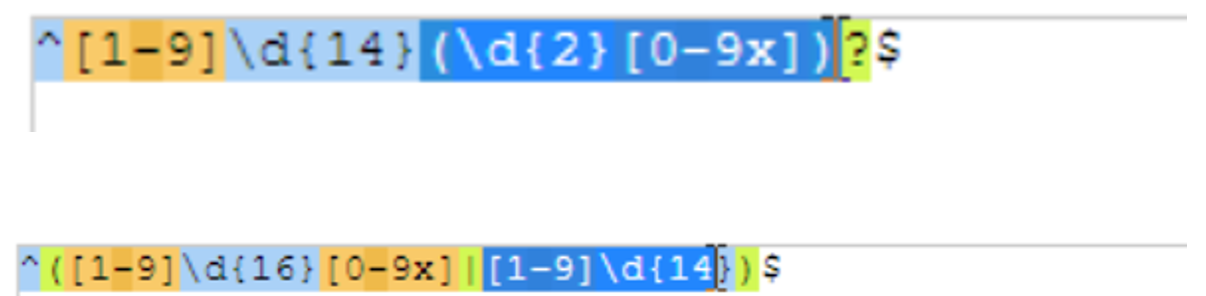
身份证的读取:
![]()
存在问题:
修改方式,如下:
缺点就是上手难
4.惰性匹配和贪婪匹配
*和+ 都是贪婪匹配
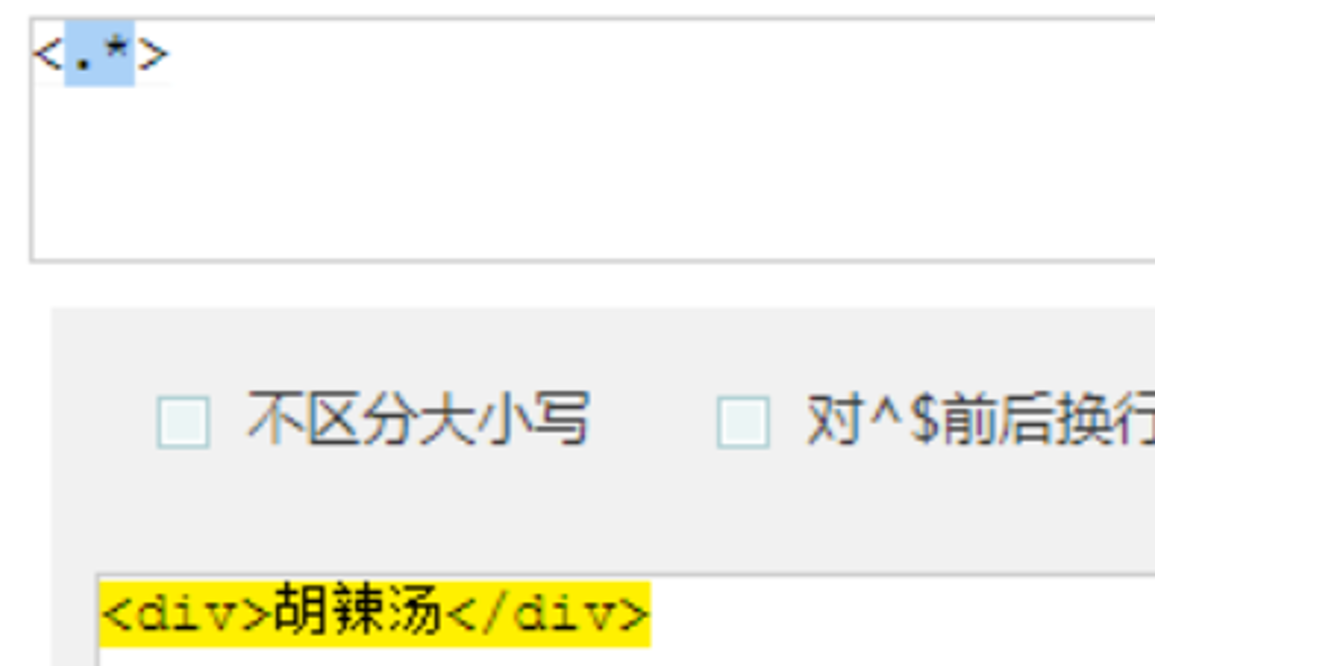
匹配最后一个>
<.*>尽可能多的匹配.结果全部
<.*?>尽可能少的匹配.结果就是<div> </div>
.*?汤 表示以汤为结尾

如果后期想拿到中间的内容.加()
5分组:
在Python中,单独拿出来,想用哪些数据,就拿出来就行.
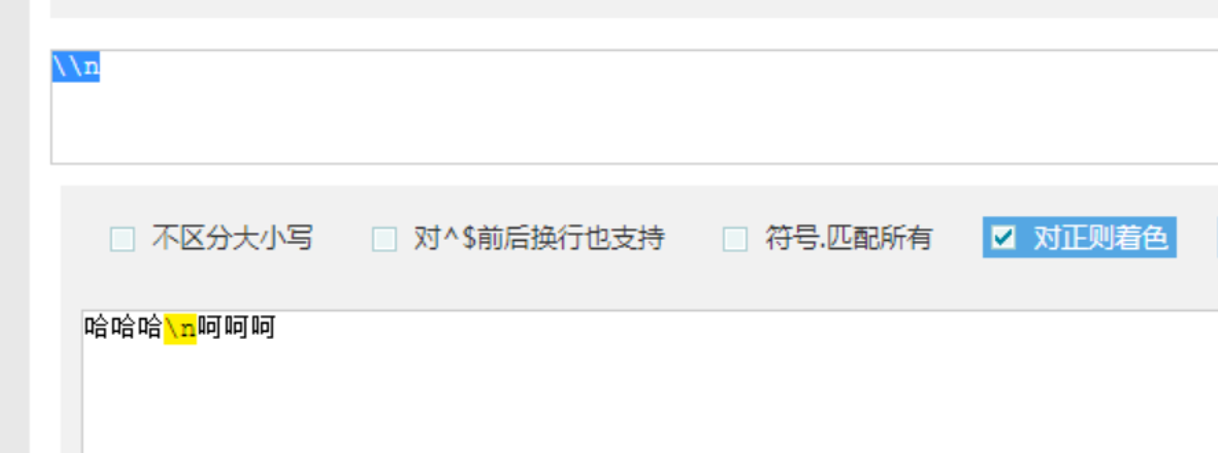
在Python中需要\\\\n,才能查找\\n 才能在正泽中的\n 后者直接r”\n”
十一.re模块
re是python操作正则表达式的手段
未来的核心内容是爬虫的根
1.re.findall(r”\d+”,”今年我都30岁了,还没有赚够100万”)
findall可以匹配到正则表达式中的内容,返回列表,如果没有返回空列表[]
import re obj=re.findall(r"\d+","我今年刚都30岁了,还没有转到第一个100万") print(obj)#['30', '100']
2.re.search(r”\d+”,”今年我都30岁了,还没有赚够100万”)
缺点:得到第一个就返回.
不匹配是None,
obj.group()#必须分组拿数据.
import re
obj1=re.search(r"\d+","我今年刚都30岁了,还没有转到第一个100万") print(obj1)#<re.Match object; span=(5, 7), match='30'>
3.re.match:会从字符串的开始匹配,自带^,匹配到结果就返回.也拿不到多个返回.
import re obj2=re.match(r"\d+","我今年刚都30岁了,还没有转到第一个100万") print(obj2)#None
4.re.finditer()#可以匹配数据,把匹配的内容放到迭代器中.
import re obj3=re.finditer(r"\d+","我今年刚都30岁了,还没有转到第一个100万") for el in obj3: print(el.group()) #30 #100
5.re.compile(+正则表达式):

可以预加载正则,然后让所有的其他的东西去匹配.如果正则很复杂建议用compile

6.re中的分组=>表示取值的优先级,被()起来的东西才是想要的.
re.findall()

元组返回.
需要给电影名起名字?P<name> ?P<url>
再修改成finditer

可以通过组的名字获得数据.
re中的分组和正则的分组很不一样.
十二.爬取电影天堂dytt
1.想办法获取网页的内容
打开网页获取了网页的内容.
查看met标签:gb2312就是gbk
拿到的数据很乱,需要在浏览器F12 查看
在上面找id的词,前段工程师表示整个网页的唯一表示,从id开始匹配.
2.写正则(re.s可以匹配换行了,就变成无敌了.)

3.匹配网页内容

获取数据在迅雷中就可以了
本周爬取电影天堂,所有数据:电影名和下载链接 打包写到json文件中.
这就是盗版网站
展示的是豆瓣网
这个好好学习
re.sub替换 re.subn()最后多一个次数
