TextRank是一种文本排序算法,是基于著名的网页排序算法PageRank改动而来。在介绍TextRank前,我们先简单介绍下什么是PageRank,再介绍如何利用TextRank进行文本关键词提取。
目录
1.PageRank算法
PageRank算法是根据互联网中的超链接关系来确定一个网页的排名,公式通过有向图和投票的思想来设计:
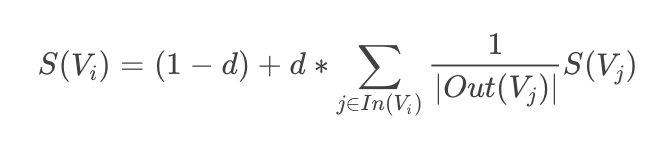
表示网页
的Rank值
- d是阻尼系数,一般取0.85,他的设置是防止
表示指向网页
表示网页
所指向的所有网页的集合(即
表示集合中元素数量,即
- 可以把互联网简单看作一个有向图,网页代表图中的节点,网页间的链入链出关系代表图中的边。
- 上述公式的直观理解就是网页
除以其指向网页的数量(节点出度)
- 初始化每个网页/节点的Rank值为1/N,N为网页/节点数量,然后通过上述公式进行迭代,更新每个网页的Rank值,直到收敛(某次更新前后Rank值几乎不再发生变化)
更多关于PageRank算法的内容可以查看以下的文章:
2.TextRank算法
对于文本关键词提取也是类似的,与之前的TF-IDF算法需要依赖语料库不同,基于TextRank的关键词抽取算法,可以把文本中的每个词看作是一个节点/网页,把文本中词的共现关系看作是边/链接。与PageRank不同的是,PageRank中是有向边,而TextRank中是无向边或可以看作是双向边,具有共现关系的两个词互相指向。
所谓的共现关系,就是对文本进行预处理(分词,去停用词,以及词性标注/筛选(可能指定关键词为名词动词或其他,其他词性都过滤掉不考虑。可选操作))后,设置一个默认大小为m的窗口,在文本中从头到尾依次滑动,同一个窗口中的任意两个词之间都连一条边(无向边,入度和出度
完全一致)。画出图之后,对每个词
赋于一个初始值
,然后代入上述公式进行迭代,直到收敛(在某次更新前后,
不再变化).最终选择按词语/节点的Rank值降序排列,选择TopN作为我们的关键词。
- 基于TextRank抽取文本关键词的主要步骤:
1.对给定的文本进行断句,按?。!等进行分隔
2.对于每个句子,进行分词,去除停用词,词性标注。并保留指定的词性,如名词、动词等,去掉其他无关词性的词语。作为候选的关键词。
3.基于候选关键词,构建图G=(V,E),其中V是节点集/候选关键词集合,通过设置窗口和共现关系构造任意两个节点/词语之间的边,两个节点/词语之间存在边当且仅当这两个节点/词语在长度为m的窗口中共同出现过,窗口从头到尾不断滑动。
4.根据PageRank迭代公式,初始化每个节点/词语的权重/Rank值(可以是1/N,N为节点/词语数量),针对每个节点/词语,代入上述公式进行迭代,直至收敛。
5.对所有节点/词语最终的权重/Rank值进行降序排列,选择TopN作为我们的关键词
6. 由5得到最重要的N个词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“Matlab code for plotting ambiguity function”,如果“Matlab”和“code”均属于候选关键词,则组合成“Matlab code”加入关键词序列。
下图是针对以下文本,按上述步骤进行处理,构建的图(窗口大小m=2,关键词指定为动词和名词):

TextRank算法论文: TextRank: Bringing Order into Text
3.TextRank与TF-IDF比较
至此,我们介绍完了TextRank和TF-IDF进行关键词抽取的思想,接下来对2者进行一个比较:
1.tf-idf中计算idf值需要依赖于语料库,这给他带来了统计上的优势,即它能够预先知道一个词的重要程度.这是它优于textrank的地方. 而textrank只依赖文章本身,它认为一开始每个词的重要程度是一样的.
2.tf-idf是纯粹用词频的思想(无论是tf还是idf都是)来计算一个词的得分,最终来提取关键词,完全没有用到词之间的关联性. 而textrank用到了词之间的关联性(将相邻的词链接起来),这是其优于tf-idf的地方.
综上,TF-IDF和TextRank各有优劣,在实际使用中效果差异不大,可以同时使用互相参考。