CBOW 表示可以通过求单词表示向量和或者通过将一个单词词袋向量乘
以一个每一行对应于一个稠密单词表示的矩阵(这样的矩阵也叫作嵌入矩阵( embedd i ng
matricy ))来得到。

网络中每行神经元的值可以看作是一个向量
全连接层可以看作是从四维到六维
的线性变换。全连接层实现了一个向量与矩阵的乘法, h=xW
由线性变换产生的向量称为层。最外层的线性变换产生输出层,其他线性变换产生隐
层。非线性激活操作接在每个隐层后面
一个网络的参数是其中的矩阵和偏置项,二者定义了网络中的线性变换
带有tanh 与sigmoid 激活函数的网络层往往容易饱和造成该层的输出都接近于
1 ,这是激活函数的上界。饱和神经元具有很小的梯度,所以应该避免。带有ReLU 激活
函数的网络层不会饱和,但是会“死掉”一一大部分甚至所有的值为负值,因此对于所有的
输入来说都裁剪为0 ,从而导致该层梯度全为0
饱和神经元是由值太大的输入层造成的。这可以通过
更改初始化、缩放输人值的范围或者改变学习速率来控制
归一激活函数后的饱和值
死神经元是由进入网络层的负
值引起的(例如,在大规模的梯度更新后可能会发生),减少学习率将减缓这种现象
语言模型是给一个句子分配概率的任务
困惑度是一种信息论测度, 用来测量一个概率模型预测样本的好坏,困惑度越低越好
一种避免0 概率事件的方法是使用平滑技术
退避( back off) :如果没有观测到h 元文法,那么就基于
(K-1) 元文法计算一个估计值
基于最大似然估计( MLE)
的语言模型很容易训练,可扩展到大规模语料,实际应用
中表现良好。然而,它有几个重要的缺点。
- 平滑技术错综复杂而且需要回退到低阶
- 缺乏对上下文的泛化
词-上下文矩阵
每行i 表示一个单词,每列j 表示词出现处的语言学上下文,矩阵项M[i,j] 为在大语料库中量化得到的词与上下文之间的关联强度。
Wi 是词表中的第i 个词,而Cj 是上下文表中的第j 个词。
矩阵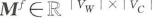 是词-上下文矩阵
是词-上下文矩阵
Word 2 Vec

窗口方法
窗口大小的影晌 窗口较大易于产生更大的主题相似性,而较小的窗口易于产生更多的功能和句法相似性
窗口位置 当使用CBOW 或s kip gram 上下文表示时,窗口中的所有不同的上下文词同等重要。与焦点词近的上下文词以及离它更远的上下文词之间没有任何区别
变体 许多基于窗口方法的变化方案是可行的
对软对齐权重
CNN 专门用来识别文本中一个
序列里的富信息η 元语法和带槽η 元语法,忽略它们的位置但考虑局部有序模式。RNN用来捕捉序列内敏感模式和规则,它可以建模非马尔可夫依赖,观测一个焦点词周围的“无限窗口”,同时放大该窗口内富含信息量的序列模式。最后,我们会讨论序列生成模型和条件生成。
卷积层背后的主要想法是对序列中所有的走元语法应用同一个参数化的函数。这样构建了m 个向量,每一个代表序列中一个特定走元语法。这种表示对于h 元语法本身和其内部的词序敏感,但是对于一个序列中不同位置的同一个走元语法会得到相同的表示。

RNN 就是一个深度神经网络(或者说, 一个带
有少量复杂结点的非常大的计算图),其中不同部分计算过程中的参数是共享的,不同层还可以附加额外的输入。为了训练一个RNN 网络,所需要做的即为对给定的输入序列构建一个展开的计算图,为展开的图添加一个损失结点,然后使用反(反向传播)算法计算关于该损失的梯度。这个过程在RNN 的文献中被称为沿时间展开的反向传播CBPTT)
RNN 常见使用模式
接收器
编码器
传感器
双向RNN
堆叠RNN
用于表示梭的RNN
长短期记忆网络(LSTM)结构[日ochreiter and Schmidhuber, 19 9 7 ]被设计用于解决梯
度消失问题,并且是第一种引入门机制的结构。LSTM 结构明确地将状态向量S; 分解为两部分, 一半称为“记忆单元”,另一半是运行记忆。记忆单元被设计用来保存跨时间的记忆以及梯度信息,同时受控于可微门组件
Cj 是记忆组件, hj 是隐藏状态组件
门的值由当前输入Xj 和前一个状态hj- 1 的线性组合通过-个sigmoid 激活函数来得到。
一个更新候选项z 由Xj 和hj-1 的线性组合通过一个tanh 激活函数来得到。
遗忘门控制有多少先前的记忆被保留( f⊙Ci-I ), 输入门控制有多少更新被保留(i⊙z)。最后, hj ( yj 的输出〉由记忆Cj
的内容通过一个ta nh 非线性激活函数并受输出门的控制来决定。这样的门机制能够使得
与记忆Cj 相关的梯度即使跨过了很长的时间距离仍然保留较高的值
RNN接收器:读入一个序列,最后产生一个二值或者多
分类的结果。
RNN特征提取器
生成器的训练
在训练生成器时,一般的方法是简单地将其当作一个转换器来进行训练
树状LSTM
需要树形结构:
需要长距离的语义依存信息的任务(例如上面的语义关系分类任务)Semantic relation extraction
输入为长序列,即复杂任务,且在片段有足够的标注信息的任务(例如句子级别的Stanford情感树库分类任务),此外,实验中作者还将这个任务先通过标点符号进行了切分,每个子片段使用一个双向的序列模型,然后总的再使用一个单向的序列模型得到的结果比树形结构的效果更好一些。