版权声明:转载请注明出处,谢谢~~ https://blog.csdn.net/m0_37306360/article/details/86356945
更多实时更新的个人学习笔记分享,请关注:
知乎:https://www.zhihu.com/people/yuquanle/columns
微信订阅号:AI小白入门
ID: StudyForAI
PKUseg简介
-
简单易用,支持细分领域分词,有效提升了分词准确度,支持用户自训练模型。支持用户使用全新的标注数据进行训练。
-
多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。 我们目前支持了新闻领域,网络文本领域和混合领域的分词预训练模型,同时也拟在近期推出更多的细领域预训练模型,比如医药、旅游、专利、小说等等。
-
更高的分词准确率。相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。
各类分词工具包的性能对比
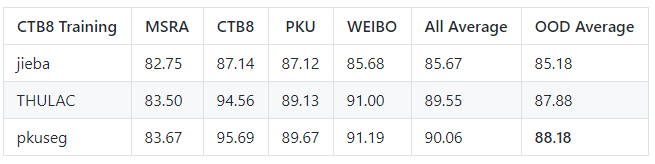
- 作者选择jieba、THULAC等国内代表分词工具包与pkuseg做性能比较。
- 考虑到jieba分词和THULAC工具包等并没有提供细领域的预训练模型,作者重新使用它们提供的训练接口在细领域的数据集上进行训练,用训练得到的模型进行中文分词。
- 作者在新闻数据(MSRA)、混合型文本(CTB8)、网络文本(WEIBO)数据上对不同工具包进行了准确率测试。使用了第二届国际汉语分词评测比赛提供的分词评价脚本。其中MSRA与WEIBO使用标准训练集测试集划分,CTB8采用随机划分。对于不同的分词工具包,训练测试数据的划分都是一致的;即所有的分词工具包都在相同的训练集上训练,在相同的测试集上测试。对于需要训练的模型,如THULAC和pkuseg,在所有数据集上,使用默认的训练超参数。
细领域训练及测试结果

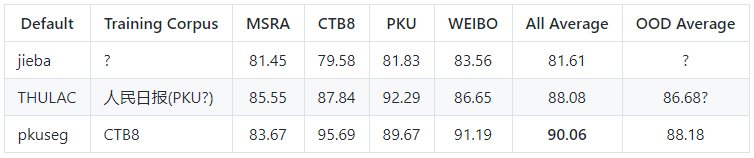
跨领域测试结果
默认模型在不同领域的测试效果
pkuseg工具Demo
- 安装:pip3 install -U pkuseg
- 国内源安装:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pkuseg
- 预训练模型地址:https://github.com/lancopku/PKUSeg-python
import pkuseg
- 使用默认模型及默认词典分词
seg = pkuseg.pkuseg() # 以默认配置加载模型
text = seg.cut('我爱北京天安门') # 进行分词
print(text)
loading model
finish
['我', '爱', '北京', '天安门']
- 设置用户自定义词典
lexicon = ['北京大学', '北京天安门'] # 希望分词时用户词典中的词固定不分开
seg = pkuseg.pkuseg(user_dict=lexicon) # 加载模型,给定用户词典
text = seg.cut('我爱北京天安门') # 进行分词
print(text)
loading model
finish
['我', '爱', '北京天安门']
- 使用其它模型
seg = pkuseg.pkuseg(model_name='./msra') # 假设用户已经下载好了msra的模型
# 并放在了'./msra'目录下,通过设置model_name加载该模型
text = seg.cut('我爱北京天安门') # 进行分词
print(text)
loading model
finish
['我', '爱', '北京', '天安门']
- 对文件分词
import pkuseg
#pkuseg.test('input.txt', 'output.txt', nthread=20) # 对input.txt的文件分词输出到output.txt中,
# 使用默认模型和词典,开20个进程
- 训练新模型
# 训练文件为'msr_training.utf8'
# 测试文件为'msr_test_gold.utf8'
# 模型存到'./models'目录下,开20个进程训练模型
# pkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20)
参数说明
- 模型配置
pkuseg.pkuseg(model_name='ctb8', user_dict=[])
model_name 模型路径。默认是'ctb8'表示我们预训练好的模型(仅对pip下载的用户)。
用户可以填自己下载或训练的模型所在的路径如model_name='./models'。
user_dict 设置用户词典。默认不使用词典。填'safe_lexicon'表示我们提供的一个中文词典(仅pip)。
用户可以传入一个包含若干自定义单词的迭代器。
- 对文件进行分词
pkuseg.test(readFile, outputFile, model_name='ctb8', user_dict=[], nthread=10)
readFile 输入文件路径
outputFile 输出文件路径
model_name 同pkuseg.pkuseg
user_dict 同pkuseg.pkuseg
nthread 测试时开的进程数
- 模型训练
pkuseg.train(trainFile, testFile, savedir, nthread=10)
trainFile 训练文件路径
testFile 测试文件路径
savedir 训练模型的保存路径
nthread 训练时开的进程数
参考资料:
代码已上传github:https://github.com/yuquanle/StudyForNLP