版权声明:该版权归博主个人所有,在非商用的前提下可自由使用,转载请注明出处. https://blog.csdn.net/qq_24696571/article/details/86500520
HBase架构
- HBase是基于HDFS的,是实时的 , 分布式的(高可靠性,高性能) , 可伸缩的(横向扩展) , 高维的非关系型数据库 .
- mysql等关系型数据库是面向于行的 , 关系型数据库有3大优点: 容易理解 , 使用方便 , 易于维护 . 但也有三大缺点: 高并发读写需求(磁盘IO是一个很大的瓶颈 , 很难承受高访问) , 海量数据的读写性能低 , 扩展性和可用性差 .
- 关系型数据库,导致性能欠佳的最主要原因是多表的关联查询 , 以及复杂的多表关联查询 .
- HBase 非关系型数据库时面向于列的 , 非关系型数据库还有redis , MongoDB等 .
- HBase利用MapReduce来处理海量数据, 利用Zookeeper来作分布式协同服务 Hbase和Zookeeper具有强依赖关系(没有不行).
- 数据库依据不同的应用场合, 可以分为几类: 高性能并发读写的键值对数据库: Redis , Tokyo , Cabinet , Flare , 面向海量数据访问的面向文档数据库: MongoDB , CouchDB . 面向可扩展性的分布式数据库: HBase
- 严谨的银行系统适合用关系型数据库, 微博,视频等实时,高并发的业务系统适合用非关系型数据库
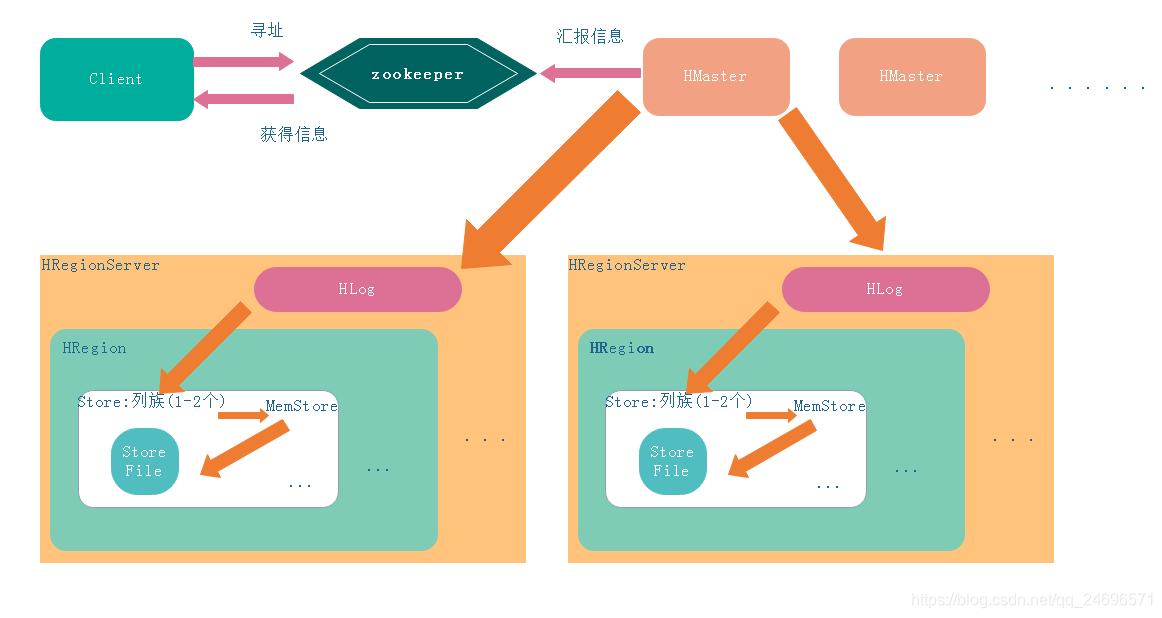
- HRegionServer , HRegion , Store(1-2) , StoreFile到达阈值后都会进行等分裂变
HBase预分区
在HBase创建的一般表 , 一张表只有一个region , 所有添加的数据都只向一个region中进行操作 , 当这个region过大就会产生split裂变 . split裂变会带来资源损耗 , 预分区用多个region来一起承受数据的添加 , 就可以减少spilit裂变操作的产生 .
标的预分区要结合业务场景来选择合适的分区的key值区间 , 预分区不同的region都有各自的startKey和endKey , 左壁右开 , 作为单一region数据存储的区间范围 .
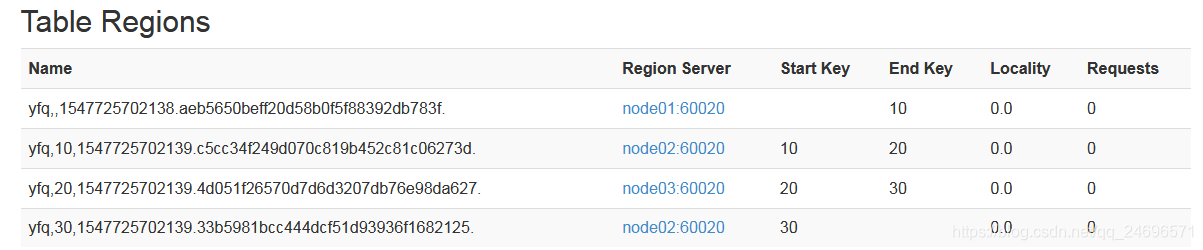
- 创建预分区表:
create 'yfq','cf1',SPLITS => ['10','20','30']
- yfq:表名 __ cf1:列族___按[]中的值分为了以下4个区
- 值得注意的是,区间划分不是对比int类型,而是对比String类型,例如rowkey的值:00101,取开头2位,它将被划分在第一个分区 .
HBase操作命令
- 进入hbase数据库:
hbase shell,shell6中回删按键:ctrl+backspace - 帮助文档:
help - 查看表
list - 创建表
- 创建带列族的表
- 创建一张名为t1,列族是cf1的表:
create 't1' , 'cf1'- 往表中添加数据
put '[表名]','[rowkey]','[列族]:[字段名]','[值]',
例子:put ‘t1’,‘00101’,‘cf1:name’,'zhangsan’
- 创建带列族和版本的表
- 创建一张名为t2,列族为cf1,带5个版本的表
create 't2',{NAME => 'cf1', VERSIONS => 5}
- 查询表内容
1.scan,对全表进行扫描,慎用,数据量越多处理速度越慢
scan '[表名]',例子:scan 't1’
查询特定版本的内容:scan 't2',{RAW=>true,VERSIONS=>10}
- get
get '[表名]','[rowkey]','[列族:字段名]',例子:get ‘t1’,‘00101’,‘cf1:name’
- 删除表
- 删除表需要首先屏蔽表,
disabled [表名]- 删除该表
drop [表名]