过拟合问题
(1)underfitting(欠拟合)
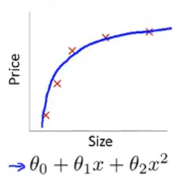
如果我们的假设函数是一个一次函数,我们可能最后得到的是这样的一条直线,很容易看出它的拟合效果不是很好,这种情况我们称之为欠拟合。

(2)just right(拟合的很好)
(3)overfittiing(过拟合)
如果我们给假设函数加入很多的高阶项,最后得到的曲线会想尽一切办法,把所有的数据点都拟合进去,这样的情况称过拟合
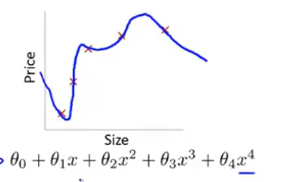
这种情况下,看似所有的数据都被拟合进去,但是这条曲线却会不停波动,不是一个好的假设函数,这种状况的原因是因为我们有太多变量θ,却没有足够的数据集去限制这些变量。
正则化
如何解决过拟合问题,一般来说有两种方法
1.减少特征变量
导致过拟合的原因就是我们有太多的特征变量而没有足够的数据集,如果我们能够通过手动选择减少一些变量,或者通过一个叫 model selection的算法自动识别能减少哪些变量,就能够解决过拟合问题。
2.regularization(正则化)
如果我们不能够减少变量的数量,那么也可以用正则化的思想去解决过拟合问题。这个方法的思想是在代价函数里加入惩罚项
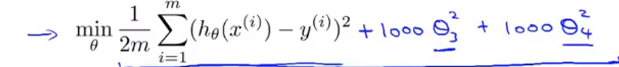
例如像这样在上面过拟合例子的代价函数里对θ3,θ4加入惩罚项,这样做的结果是我们最后得到的假设函数中,θ3,θ4就会很小,看起来就和二次函数差不多。
在实际情况中,我们并不知道哪些项应该尽可能小最好,所以在正则化中,我们采取的方法是对每一个参数都加入惩罚项,这样得到一个新的代价函数
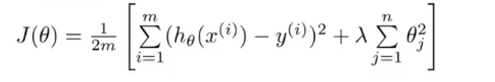
这里的
叫做正则化参数,它有两个目标,一是要与前面的项关联,去更好的拟合数据,第二个目标是尽量让每个参数更小,以实现正则化的目标。
需要在这两个目标中间找到一个平衡。
所以如果这里
太大,如
,那么会导致对每一项的惩罚力度过大,从而每一项都接近于0,这样只会得到一条直线,从而导致欠拟合问题。