Kafka系列为自己学习与使用Kafka中遇到的问题与总结。本系列将介绍如下内容:
- Kafka入门及应用场景 & 部署 & 简单测试
- Kafka核心概念
- Kafka常用命令
- Kafka监控
- Kafka消费语义分析
- Flume + Kafka + SparkStreaming打造通用的流处理基础平台
- 生产案例分享
是一个长期更新的系列,希望自己能够坚持:)
入门及应用场景
官网描述所发生的改变

分布式的流式平台;原来叫消息平台,这是因为现在kafka加入了stream,所以有了说法上的改变
3个特性

一个流式平台有以下3个特性:
- 发布和订阅流式的消息,类似于消息队列
- 以高容错的方式存储消息
- 处理流式消息
2种应用场景

Kafka一般有2种应用场景:
- 离线场景:数据写到Kafka,后面写个应用程序然后每个批次去消费它,也是可以的美图就是这样在做,数据接到Kafka之后,然后基于MapReduce构建ETL操作,将数据落到HDFS上
一般来说,使用Kafka对接实时处理框架比较多 - 构建实时的流式应用,指的是Kafka stream,在生产中用的不是很多
常见的应用场景:作为消息中间件,一般部署在流式组件的前一个,主要为了避免高峰期计算来的压力
部署
Zookeeper简介&部署
简介
Zookeeper官网:http://zookeeper.apache.org/
作用:Zookeeper是一个协调服务,一般会用zk来做HA
版本:生产上Zookeeper的版本是3.4.6
机器数量:生产集群小于100台,Zookeeper部署7台
生产集群大于100台,Zookeeper部署7台 或 9台
注意:并不是Zookeeper的机器越多越好,因为在选举的时候如果机器很多,选举肯定是很繁忙的(个人经验)
遇到问题可以去查看zookeeper.out,有具体的报错信息,可以进行排查
也可以使用ps –ef|grep zookeeper去查看进程是否存活
部署
参考之前的Blog:Zookeeper集群搭建 & 数据同步性测试
使用
HDFS HA、YARN HA都依赖于Zookeeper,Kafka、HBase也依赖于Zookeeper
进入到客户端的相关操作:
- zkCli.sh进入到当前机器的客户端界面,localhost模式
- 指定其中一台zookeeper地址进入
命令:ZooKeeper -server host:port

- 命令帮助,进入console,输入help
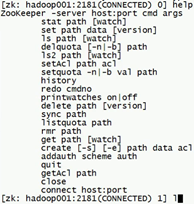
- 几个简单的命令介绍:
ls /
ls /zookeeper
rmr path
jdk和scala部署
jdk的部署路径:/usr/java
JDBC的部署路径:/usr/share/java
原因:CDH环境中server端和agent端会优先读取这个路径,如果不这样配置会很麻烦
使用CDH建议这样配置
Scala版本:2.11.8
Kafka部署
版本介绍
Kafka版本:0.8.x 0.10.x
主要是这两个分支,为什么是这两个,结合SparkStreaming官网:
https://spark.apache.org/docs/2.2.0/streaming-kafka-integration.html
选用版本:kafka_2.11-0.10.0.1.tgz
原因:后续SparkStreaming对接Kafka使用direct模式
部署步骤
集群部署
需要修改的配置文件:$KAFKA_HOMR/config/server.properties
broker.id=1
port=9092
host.name=xxxx
log.dirs=/opt/software/kafka/logs
zookeeper.connect=xxxx:2181,xxxx:2181,xxxx:2181/kafka
3台机器,对应修改broker.id和host.name即可
且在每台机器上去创建对应的log.dirs路径即可
环境变量配置
配置在/etc/profile下,具体步骤略
简单测试
启动/停止
每台机器执行:
nohup kafka-server-start.sh config/server.properties &
后台启动,以防Kafka进程挂掉
停止命令:
bin/kafka-server-stop.sh
模拟实验
Kafka创建完成之后,在zookeeper中的目录是怎么样的呢?如下图:

该操作是没有指定 /kafka 目录的情况,因此都是散乱的目录;指定后就都在 /kafka 下了
修改server.properties:
zookeeper.connect=xxxx:2181,xxxx:2181,xxxx:2181/kafka
这样操作后,会将对应的信息写到zookeeper中的/kafka目录下
创建topic:

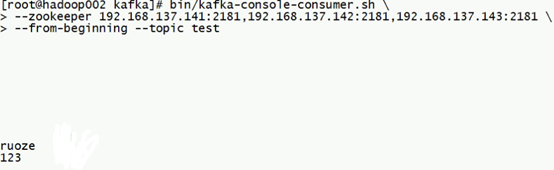
开启生产者:

开启消费者:

在生产者的console下输入,即开始向Kafka中写入数据:

消费者开始消费:
常见的架构
Kafka部署完成的进程,实质上是一个broker
一般的流程:producer --> broker cluster --> consumer
一般的架构:Flume --> Kafka --> Spark Streaming
以生产为例:

xx日志和xx日志用的同一套Kafka集群,针对不同的日志设立不同的topic
可以抽象的将topic理解为文件夹,如果指定了topic为yy,那么所有对应的数据都会在yy下面;而计算程序在代码中就会指定到对应的topic中去读取数据,进行消费
具体含义下面的文章中会介绍