核心概念
broker: 进程
producer: 生产者 flume
consumer: 消费者 ss (spark streaming,,,)
topic: 主题 分区+副本数 文件夹
partition: 分区一个分区可以有多个副本
consumergroup:
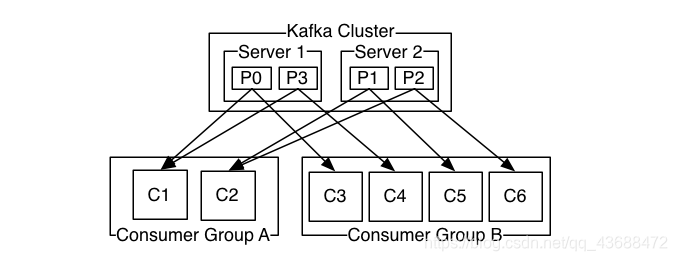
重点解析:
1.一个组内,共享一个公共的GROUPID
2.组内的所有消费者协调一起,去消费topic的所有的分区,并且不重复
3.每个分区p0只能由一个消费组A的一个消费者C1来消费(po只能让A组的c1消费,不能c2在消费)
4.容错性的消费机制
offset:
有序的 不可变的序列 相当于MySQL自增长主键
每个分区记录offset 偏移量 都是从1开始
segment: 每个分区都是由一系列的segment文件组
segment: log+index 两两出现
命名规则: 第一组为00000000000000000000
第二组为00000000000000002000
名称是由上一组的最后一条消息的offset来命名
例子:
通过offset为2800对应的消息
00000000000000000000.index
00000000000000000000.log
00000000000000002000.index
00000000000000002000.log
00000000000000004200.index
00000000000000004200.log
1.log文件记录message 全部
2.index文件记录 相对offset和对应的消息的物理偏移量 字节位置
稀疏存储
3.2800-2000=800 相对offset 800