最近在看原前清皇帝溥仪的自传《我的前半生》, 这本小说记载了自他登基以来经历的奢华的宫闱生活,对答应日寇加冕成为伪满皇帝站在人民对立面的忏悔,以及在我党红色政权的拯救以及接收共产主义的洗礼的无限感恩。小说中多次提到各个年号下的所发生的一些事件,所以我想通过爬虫来抓取这部小说出现的“光绪”,“宣统”两朝年号下发生的事件,也是对爬虫知识的一次实际应用。
1).导入坐标依赖以及application.properties配置文件信息

2).编写SpringBoot启动类
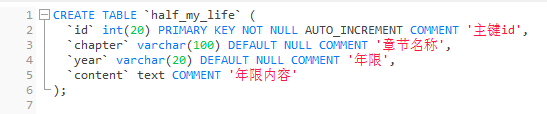
3).实体类及数据库信息

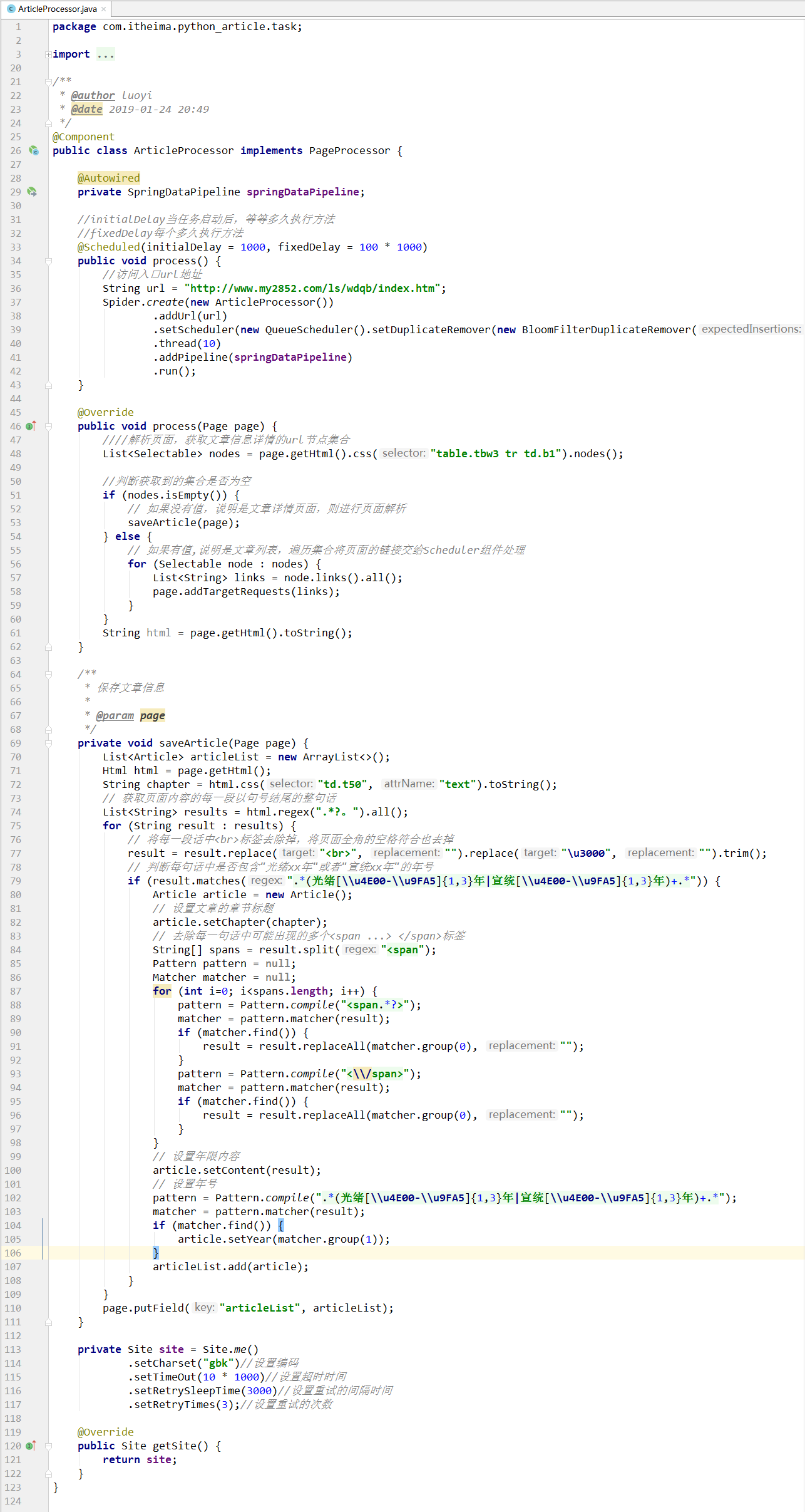
4).将页面内容进行处理
①. 定时任务scheduler
在案例中我们使用的是Spring内置的Spring Task,这是Spring3.0加入的定时任务功能。我们使用注解的方式定时启动爬虫进行数据爬取。
我们使用的是@Scheduled注解,在使用@Scheduled注解之前需要在Spring Boot启动类启动开启定时任务的注解@EnableScheduling。
@Scheduled注解属性如下:
1)cron:cron表达式,指定任务在特定时间执行;
2)fixedDelay:上一次任务执行完后多久再执行,参数类型为long,单位ms
3)fixedDelayString:与fixedDelay含义一样,只是参数类型变为String
4)fixedRate:按一定的频率执行任务,参数类型为long,单位ms
5)fixedRateString: 与fixedRate的含义一样,只是将参数类型变为String
6)initialDelay:延迟多久再第一次执行任务,参数类型为long,单位ms
7)initialDelayString:与initialDelay的含义一样,只是将参数类型变为String
8)zone:时区,默认为当前时区,一般没有用到
我们这里的使用比较简单,固定的间隔时间来启动爬虫。例如可以实现项目启动后,每隔100秒启动一次爬虫。但是有可能业务要求更高,并不是定时定期处理,而是在特定的时间进行处理,这个时候我们之前的使用方式就不能满足需求了。例如我要在工作日(周一到周五)的晚上八点执行。这时我们就需要cron表达式了。
cron的表达式是字符串,实际上是由七子表达式,描述个别细节的时间表。这些子表达式是分开的空白,代表:
1. Seconds(秒) :可以用数字0-59 表示,
2. Minutes(分) : 可以用数字0-59 表示
3. Hours(时) : 可以用数字0-23表示
4. Day-of-Month(天) :可以用数字1-31 中的任一一个值,但要注意一些特别的月份
5. Month(月) : 可以用0-11 或用字符串(JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC)
6. Day-of-Week(天) :可以用数字1-7表示(1 = 星期日)或用字符口串 (SUN, MON, TUE, WED, THU, FRI, SAT)
7. Year(年) (可选字段)
例 "0 0 12 ? * WED" 在每星期三下午12:00 执行,
“*” 代表整个时间段
“?”:表示每月的某一天,或第周的某一天( Day-of-Month 和 Day-of-Week 两者只能出现其一)
“/”:为特别单位,表示为“每”如“0/15”表示每隔15分钟执行一次,“0”表示为从“0”分开始, “3/20”表示表示每隔20分钟执行一次,“3”表示从第3分钟开始执行
“L”:用于每月,或每周,表示为每月的最后一天,或每个月的最后星期几如“6L”表示“每月的最后一个星期五”
②.程序执行流程
(1).启动类执行后延时1秒即执行process()方法,并且没隔100秒均会执行一次此方法,此方法对Spider对象进行初始化。
(2).processor(Page page)方法执行,此方法对Spider对象中的入口url解析:
如若此页面是详情页面则通过saveArticle(Page page)对页面内容解析并封装到Article类中.
如若此页面是列表页面则遍历此页面的链接并加入到Schduler组件管理。
String html = page.getHtml().toString(): 获取Schduler组件下一个url地址的页面内容。
page.putField("articleList", articleList) : 将封装的结果以键值对的形式存入Pipeline组件。
5).Pipeline组件处理结果
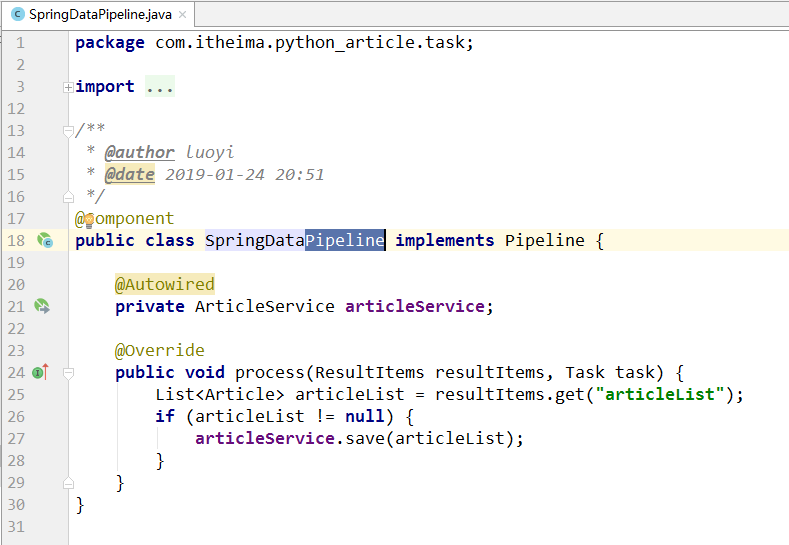
Pipeline组件类似Map集合以键值对的形式获取Processor组件封装的结果,此处的处理为将封装的ArticleList集合保存到数据库。
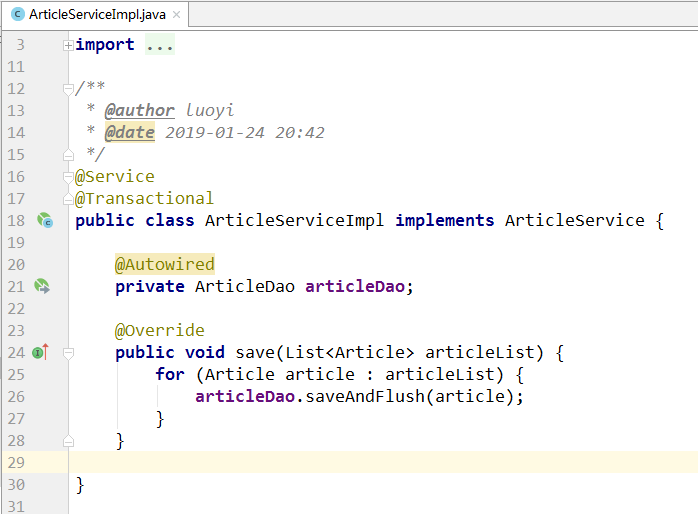
6).Service层代码

7).dao层代码
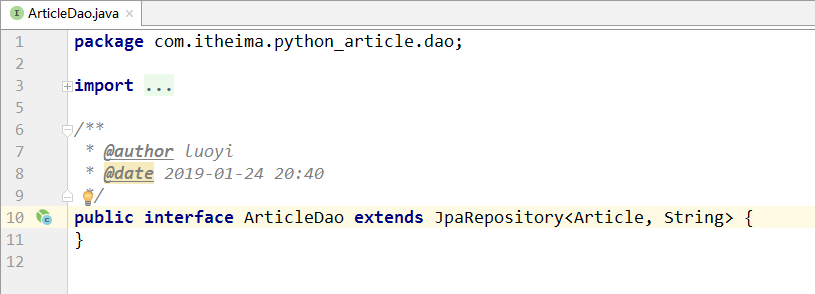
dao持久层只需继承JpaRepository接口即可,Spring-Data-Jpa框架会自动以代理的形式为我们生成实例类,并且可以直接调用父接口的方法。框架实在是神奇所在,太方便,太好用了!!!
8)获取抓取结果
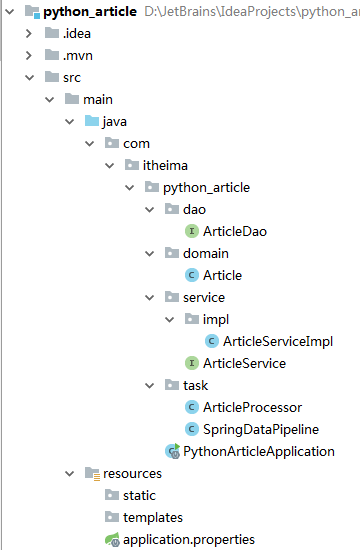
①.整个案例的目录结构:
②.数据库保存结果:

至此整个小案例的抓取效果以实现。