1.vi 文本编辑
vi xxx.log
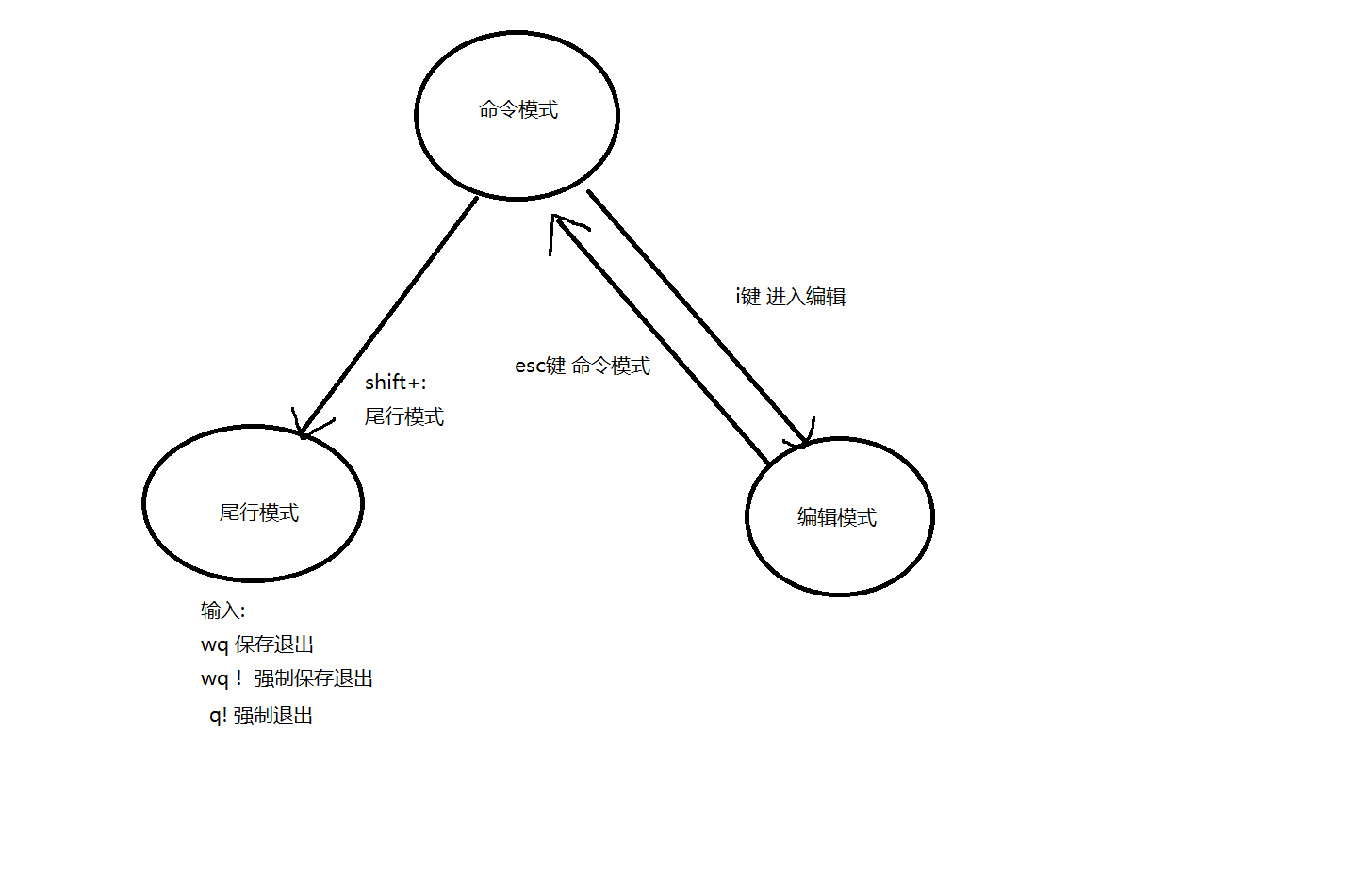
第一次进来命令行模式
按i键进入编辑模式
按esc键退回到命令行
shift+:进入尾行模式
输入wq保存
(注意wq!强制保存)
如果不小心编辑错了,不想保存
按q!强制退出不保存
生产文件 xxx.conf
修改生产文件以前一定备份,加日期
xxx_20190123.conf
命令行模式常见快捷键
dd 删除当前行
dG 删除光标(包含光标行)以下的所有行
ndd 删除包含光标的n+1行
gg跳转到第一行的第一个字母
G 跳转到最后一行的第一个字母
shift +$ 尾行最后一个字符
按i 朝右箭头按一下然后回车
生产场景:
有一个内容很多的文件,我想清空
一。先按gg 跳转到第一行的第一个字母
然后dG 删除光标(包含光标行)以下的所有
二。
echo “”> xxx.log(文件名)伪清空(判断shell脚本是否清空根据字节大小来判断)
3.cat /dev/null>ruoze.log2 真正清空
生产场景2
一个文件内容很多,我想要追加写文件
先按G
然后shift +$(一行的最后一个字母)
再按i 朝右箭头按一次再按回车 到新的一行然后开始编辑追加的内容
shift+:进入尾行模式以后 想回去继续编辑 按back
当一个文件内容很多 比如系统的log 我想要快速定位大error关键词
搜索:/+关键词 然后按回车 往下搜 按n 往上搜按N
(尾行模式输入/关键词)
给文件加行号
尾行模式 set nu
取消行号
尾行模式 set nonu
cat 文件名 |grep 关键词 简单判断
将要查看的文件上传到window 用编辑器搜索关键词
vi命令掌握透配置文件都是你的
**在生产修改配置文件一定要备份备份
2权限
看到 Permission denied 就是没有权限的意思
dr-xr-xr-- 2 root root 4096 Jan 20 19:31 1
以d开头的是目录或者是目录
-r-xr-xr-- 1 root root 66 Jan 24 20:15 jepson.log1
以-开头的是文件
r-xr-xr--是权限
r=读=4
w=写=2
x=执行=1
-=0
x一般赋给shell脚本
dr-xr-xr-- 2 root root 4096 Jan 20 19:31 1
drwxr-xr-x 3 root root 4096 Jan 20 10:46 2
drwxr-xr-x 3 root root 4096 Jan 20 10:50 3
dr-xr-xr-- 2 root root 4096 Dec 13 09:36 4
drwxr-xr-x 2 root root 4096 Dec 20 22:46 bin
drwxr-xr-x 2 root root 4096 Jan 20 11:04 jepson.log
-r-xr-xr-- 1 root root 66 Jan 24 20:15 jepson.log1
-rw-r--r-- 1 root root 0 Dec 21 11:00 jepson.log2
-rw-r--r-- 1 root root 44 Jan 20 11:02 jepson.log4
-rw-r--r-- 1 root root 10 Jan 20 17:52 ruoze.log
权限 (未知) 用户 用户组 建立日期 文件名称
第5
除了以-和d开头以外还可以是l开头
l开头的是连接
ln -s 现有文件 软连接文件夹名称
软连接相当于快捷键,快捷键删除原路径下的文件或文件夹不变
eg
[root@hadoop001 ruozedata]# ll
total 36
dr-xr-xr-- 2 root root 4096 Jan 20 19:31 1
drwxr-xr-x 3 root root 4096 Jan 20 10:46 2
drwxr-xr-x 3 root root 4096 Jan 20 10:50 3
dr-xr-xr-- 2 root root 4096 Dec 13 09:36 4
drwxr-xr-x 2 root root 4096 Dec 20 22:46 bin
drwxr-xr-x 2 root root 4096 Jan 20 11:04 jepson.log
-r-xr-xr-- 1 root root 66 Jan 24 20:15 jepson.log1
-rw-r--r-- 1 root root 0 Dec 21 11:00 jepson.log2
-rw-r--r-- 1 root root 44 Jan 20 11:02 jepson.log4
-rw-r--r-- 1 root root 10 Jan 20 17:52 ruoze.log
[root@hadoop001 ruozedata]# ^C
[root@hadoop001 ruozedata]# ln -s 4 44
[root@hadoop001 ruozedata]# ll
total 36
dr-xr-xr-- 2 root root 4096 Jan 20 19:31 1
drwxr-xr-x 3 root root 4096 Jan 20 10:46 2
drwxr-xr-x 3 root root 4096 Jan 20 10:50 3
dr-xr-xr-- 2 root root 4096 Dec 13 09:36 4
lrwxrwxrwx 1 root root 1 Jan 24 20:51 44 -> 4
drwxr-xr-x 2 root root 4096 Dec 20 22:46 bin
drwxr-xr-x 2 root root 4096 Jan 20 11:04 jepson.log
-r-xr-xr-- 1 root root 66 Jan 24 20:15 jepson.log1
-rw-r--r-- 1 root root 0 Dec 21 11:00 jepson.log2
-rw-r--r-- 1 root root 44 Jan 20 11:02 jepson.log4
-rw-r--r-- 1 root root 10 Jan 20 17:52 ruoze.log
[root@hadoop001 ruozedata]#
查看文件的大小
ll -h
du -sh
查看文件夹的大小
du -sh
修改权限命令
chmod 444 文件名称
这样的文件进去以后
显示只读
只读文件编辑后保存用wq!
chmod -R 777 文件夹名(xxx) R相当于递归 把xxx文件夹下的所有文件和文件夹权限都改为777
生产场景
一般软件安装mysql数据库 都有自己的所属用户 mysqladmin 用户组 mysqladmin
su - mysqladmin : 有权限创建 读 写 执行
目录 755
chown -R jepson:jepson 目录xxx 目录xxx下的所有目录的用户和用户组都变成 jepson
eg
[root@hadoop001 ruozedata]# chown -R jepson:jepson 1
[root@hadoop001 ruozedata]# ll
total 36
drwxrwxrwx 2 jepson jepson 4096 Jan 20 19:31 1
drwxrwxrwx 3 root root 4096 Jan 20 10:46 2
drwxrwxrwx 3 root root 4096 Jan 20 10:50 3
drwxrwxrwx 2 root root 4096 Dec 13 09:36 4
lrwxrwxrwx 1 root root 1 Jan 24 20:51 44 -> 4
drwxrwxrwx 2 root root 4096 Dec 20 22:46 bin
drwxrwxrwx 2 root root 4096 Jan 20 11:04 jepson.log
-rwxrwxrwx 1 root root 66 Jan 24 20:15 jepson.log1
-rwxrwxrwx 1 root root 0 Dec 21 11:00 jepson.log2
-rwxrwxrwx 1 root root 44 Jan 20 11:02 jepson.log4
-rwxrwxrwx 1 root root 10 Jan 20 17:52 ruoze.log
[root@hadoop001 ruozedata]# cd 1
[root@hadoop001 1]# ll
total 8
-rwxrwxrwx 1 jepson jepson 10 Jan 20 19:30 jepson.log
-rwxrwxrwx 1 jepson jepson 10 Jan 20 19:31 ruoze.log
linux用户 jepson :读
一般情况下 安装软件的用户都将其执行命令
chmod -R 755 mysqladmin 用户组和其他用户可以读和执行
整套Linux学习过程
-R参数的命令你们就记住这两个 其他都是小r
eg cp -r zip -r复制文件夹
x是执行的权限一般XXX.sh文件需要这个权限 sh文件一般都是shell脚本
shell脚本的开头一定是
#!/bin/bash
执行shell脚本 1. ./XXX.sh 2.sh XXX.sh
3.上传下载
yum install lrzsz 下载下载和上传的软件
rz window ==>linux 上传命令 从window上传到linux
rz命令使用 想把文件下载到那个目录下,就cd切换到那个目录,
然后执行rz命令(直接输入rz),此时就会跳出会话窗口让你选择你要上传的文件
sz linux ==> window 下载命令 从linux下载到window
sz命令的使用 可以cd到要下载的文件所在的目录下然后执行 sz +要下载的文件名
或者 sz +目录所在路径+要下载文件名
在使用xshell时上传和下载命令执行后会出来window窗口供你选择
但是在CRT中下载命令执行以后他会有一个默认路径,
下载完成以后可能不清楚下载到哪了,这时在把会话窗口打开,点击相应的ip右键点击属性,
然后出现一个窗口在窗口的左侧界面选择X/Y/Zmodem,然后窗口的右侧会出现Download的选项,
download就是你下载的路径
**路径修改以后要重新打开一个窗口来下载 要不然不生效
4.系统命令
top 查看机器运载情况
load average: 0.00(一分钟), 0.00(5分钟), 0.00(十分钟)
生产服务器 这三个值最好不要超过10 经验值
超过10的一般需要查看一下
再就是看CPU% 如果占比率很高要根据第一列的pid查看是什么进程 看看是否被挖矿
ps -ef|grep pid
内存
[root@hadoop001 /]# free -m
total used free shared buff/cache available
Mem: 3790 718 184 0 2887 2781
Swap: 0 0 0
[root@hadoop001 /]#
总内存 3790 已使用 718 还剩184
硬盘 df -h
[root@hadoop001 /]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 4.5G 33G 12% / 根目录总共40G 使用4.5G 还剩33G 使用率12%
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 416K 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs 380M 0 380M 0% /run/user/0
5.压缩 解压
首先要用亚马云下载解压压缩命令
yum install -y zip unzip
zip unzip
zip -r 6.zip 6/*
zip + 自命名压缩文件名称.zip +要压缩文件名称
unzip 1.zip
[root@hadoop001 ruozedata]# unzip 1.zip
Archive: 1.zip
replace 1/jepson.log? [y]es, [n]o, [A]ll, [N]one, [r]ename: y
extracting: 1/jepson.log
replace 1/ruoze.log? [y]es, [n]o, [A]ll, [N]one, [r]ename: y
extracting: 1/ruoze.log
一般出现以上的这种情况就是说明你要解压的文件姐的名称在现在目录下是存在的
总结在使用zip和unzip命令时压缩命令可以使用绝对路径 也可以使用相对路径,也可以指定到不同的路径之下
[root@hadoop001 ruozedata]# zip -r /root/ruozedata/2/3.zip /root/ruozedata/2/3
adding: root/ruozedata/2/3/ (stored 0%)
[root@hadoop001 ruozedata]# ll /root/ruozedata/2
total 8
drwxrwxrwx 2 root root 4096 Jan 20 10:46 3
-rw-r--r-- 1 root root 188 Jan 27 10:25 3.zip
[root@hadoop001 ruozedata]# zip -r 3.zip /root/ruozedata/2/3
adding: root/ruozedata/2/3/ (stored 0%)
zip -r 3.zip /root/ruozedata/2/3、
tar -xzvf 解压 tar gz
tar -czvf 6.tar.gz 6/* 压缩
tar -xzvf 6.tar.gz 解压
z在压缩gz包的时候需要
v相当于可视化
Examples:
tar -cf archive.tar foo bar # Create archive.tar from files foo and bar.
tar -tvf archive.tar # List all files in archive.tar verbosely.
tar -xf archive.tar # Extract all files from archive.tar.
6.wget 下载链接
wget后加下载链接
eg:
[root@hadoop001 ruozedata]# wget https://www.cnblogs.com/xuziyu/p/10301295.html
--2019-01-27 10:57:55-- https://www.cnblogs.com/xuziyu/p/10301295.html
Resolving www.cnblogs.com (www.cnblogs.com)... 47.111.45.248, 47.96.240.190
Connecting to www.cnblogs.com (www.cnblogs.com)|47.111.45.248|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 21955 (21K) [text/html]
Saving to: ‘10301295.html’
100%[================================================================>] 21,955 --.-K/s in 0.001s
2019-01-27 10:57:55 (17.0 MB/s) - ‘10301295.html’ saved [21955/21955]
看到saved就说明下载成功了,然后ll查看就能看到当前目录下有10301295.html文件
[root@hadoop001 ruozedata]# ll
total 76
drwxr-xr-x 2 root root 4096 Jan 27 10:17 1
-rw-r--r-- 1 root root 21955 Jan 27 10:57 10301295.html
-rw-r--r-- 1 root root 157 Jan 27 10:12 1.tar
-rw-r--r-- 1 root root 157 Jan 27 10:13 1.tar.gz
-rw-r--r-- 1 root root 344 Jan 27 10:16 1.zip
drwxrwxrwx 3 root root 4096 Jan 27 10:25 2
-rw-r--r-- 1 root root 158 Jan 27 10:23 2.zip
-rw-r--r-- 1 root root 188 Jan 27 10:26 3.zip
drwxrwxrwx 2 root root 4096 Dec 13 09:36 4
lrwxrwxrwx 1 root root 1 Jan 24 20:51 44 -> 4
drwxrwxrwx 2 root root 4096 Dec 20 22:46 bin
drwxrwxrwx 2 root root 4096 Jan 20 11:04 jepson.log
-rwxrwxrwx 1 root root 66 Jan 24 20:15 jepson.log1
-rwxrwxrwx 1 root root 0 Dec 21 11:00 jepson.log2
-rwxrwxrwx 1 root root 44 Jan 20 11:02 jepson.log4
-rwxrwxrwx 1 root root 10 Jan 20 17:52 ruoze.log
[root@hadoop001 ruozedata]#
坑: 如果下载的文件的名称是带有空格的,那就注意了 在查看的时候一定要把文件的名称给用双引号引起来,否则查看不了
7.作业调度
[root@hadoop001 ~]# crontab -e ##编辑 实际上保存目录是/tmp/crontab.hlgial"
* * * * * /root/ruozedata/test.sh >>root/ruozedata/test.log ##编辑内容
*/2 * * * * /root/ruozedata/test.sh >>root/ruozedata/test.log 这样是每个2分钟
*/10 * * * * /root/ruozedata/test.sh >>root/ruozedata/test.log 这样是每隔10分钟
*代表每的意思
都是星号代表每月每周每日每分钟
第1个*代表: 每分
第2个代表: 每小时
第3个代表: 每日
第4个代表:每 月
第5个代表: 每周
思考:每10秒该怎么办
[root@hadoop001 ruozedata]# vi test1.sh
#!/bin/bash
for((i=1;i<=6;i++));
do
date
sleep 10s
done
exit
###shell脚本写完以后一定不要忘记加执行权限
[root@hadoop001 ruozedata]# crontab -e
* * * * * /root/ruozedata/test1.sh >> /root/ruozedata/test1.log ##* * * * * /root/ruozedata/test1.sh代表每分钟执行这个shell脚本 这个shell脚本又是每隔10秒脚本离得for循环执行6次,每次间隔10秒,6次执行完以后也就是50秒过去了,再过10秒*****每隔1分钟的那个又开始执行,又开始了for循环 ,周而复始。
[root@hadoop001 ~]# crontab -l ##查看
* * * * * /root/ruozedata/test.sh >>root/ruozedata/test.log
[root@hadoop001 ~]#
###shell脚本的执行 1../+shell命令名称 2.sh +shell脚本名称 这两种执行都是在当前目录下执行的,在如果不在当前目录下就用绝对路径访问,效果和./shell脚本名称是一致的。
8.后台执行命令 不交互
在shell脚本中注释掉就是在这一行之前加#
在生产上想让shell脚本后台执行
./test.sh &
nohup ./test.sh & 短期的后台运行,因为一直执行产生的内容很多
[root@hadoop001 ruozedata]# nohup ./test.sh &
[11] 15856
[root@hadoop001 ruozedata]# nohup: ignoring input and appending output to ‘nohup.out’
[11] Done nohup ./test.sh
[root@hadoop001 ruozedata]# cat nohup.out
Sun Jan 27 15:18:29 CST 2019
Sun Jan 27 15:18:57 CST 2019
nohup ./test.sh > /root/test.log 2>&1 &