hbase的概述
本文参考摘自:https://www.cnblogs.com/oraclestudy/articles/5665780.html#top
概述
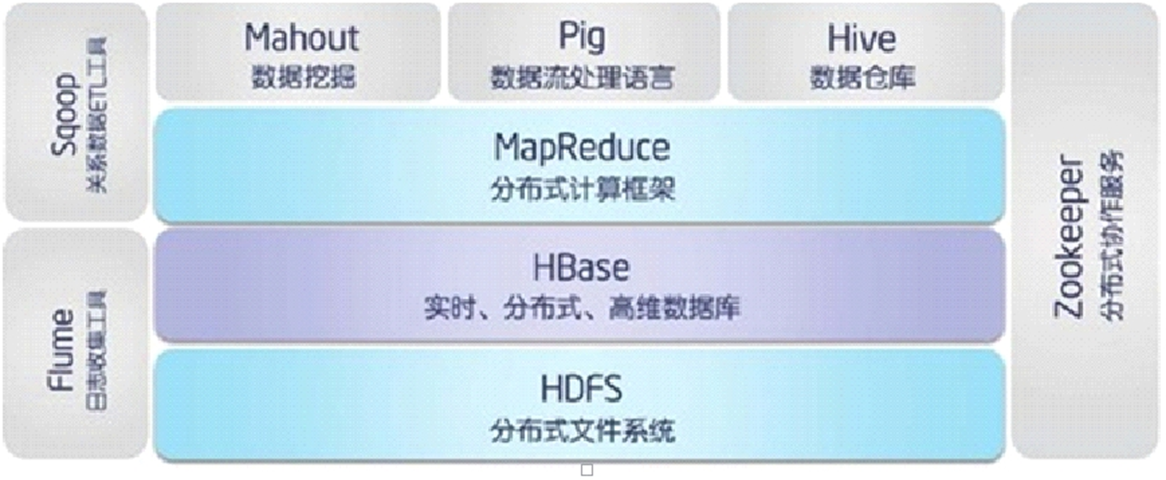
上图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
此外,Pig(不常用了)和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
HBase是一个构建在HDFS上的分布式列存储系统;
HBase是基于Google BigTable模型开发的,典型的key/value系统;
HBase是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储;
从逻辑上讲,HBase将数据按照表、行和列进行存储。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Hbase表的特点
大:一个表可以有数十亿行,上百万列;
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
面向列:面向列(族)的存储和权限控制,列(族)独立检索;
稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
数据类型单一:Hbase中的数据都是字符串,没有类型。
HBase访问接口
1. Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
2. HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
3. Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
4. REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
5. Pig(过时),可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
6. Hive,当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase
HBase数据模型


Row Key:
行键,Table的主键,
Table中的记录按照Row Key排序,按照字典顺序排序的。
决定一行数据
Row key只能存储64k的字节数据
Timestamp:
时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
时间戳的类型是 64位整型。
时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
Column Family:
列族,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘course’;
列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:math, course:english, 新的列族成员(列)可以随后按需、动态加入;
权限控制、存储以及调优都是在列族层面进行的;
HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
cell单元格:
由行和列的坐标交叉决定;
单元格是有版本的;
单元格的内容是未解析的字节数组;
由{row key, column( =<family> +<qualifier>), version} 唯一确定的单元。
cell中的数据是没有类型的,全部是字节码形式存贮。
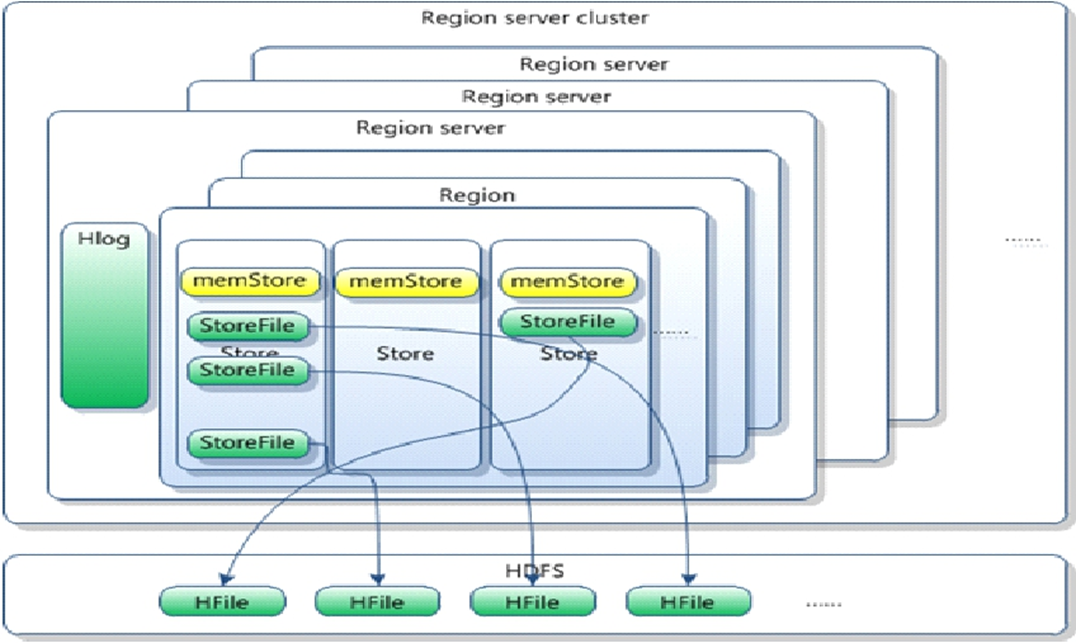
HLog(WAL log):
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
Table & Region
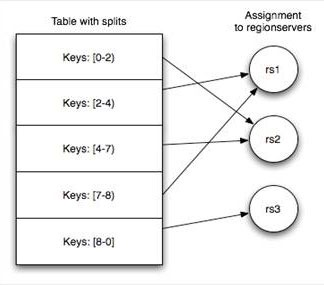
当Table随着记录数不断增加而变大后,会逐渐分裂成多份splits,成为regions,一个region由[startkey,endkey)表示,不同的region会被Master分配给相应的RegionServer进行管理:
ROOT- && .META. Table
HBase中有两张特殊的Table,-ROOT-和.META.
META.:
记录了用户表的Region信息,.META.可以有多个regoin
ROOT:
记录了.META.表的Region信息,-ROOT-只有一个region
Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
MapReduce on HBase
在HBase系统上运行批处理运算,最方便和实用的模型依然是MapReduce,如下图:
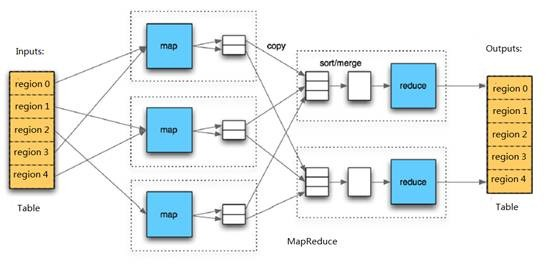
HBase Table和Region的关系,比较类似HDFS File和Block的关系,HBase提供了配套的TableInputFormat和TableOutputFormat API,可以方便的将HBase Table作为Hadoop MapReduce的Source和Sink,对于MapReduce Job应用开发人员来说,基本不需要关注HBase系统自身的细节。
HBase系统架构
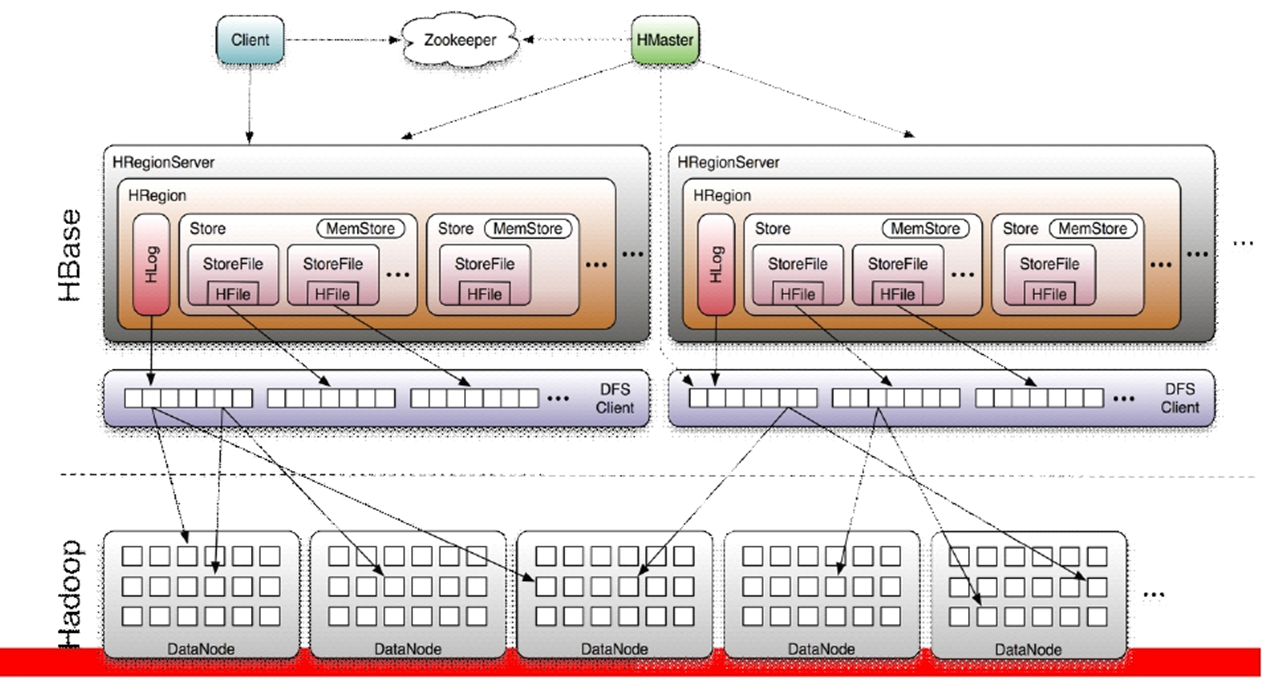
Client
包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
保证任何时候,集群中只有一个master
存贮所有Region的寻址入口。
实时监控Region server的上线和下线信息。并实时通知Master
存储HBase的schema和table元数据
Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改操作
RegionServer
Region server维护region,处理对这些region的IO请求
Region server负责切分在运行过程中变得过大的region
Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据
每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region(裂变)
当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
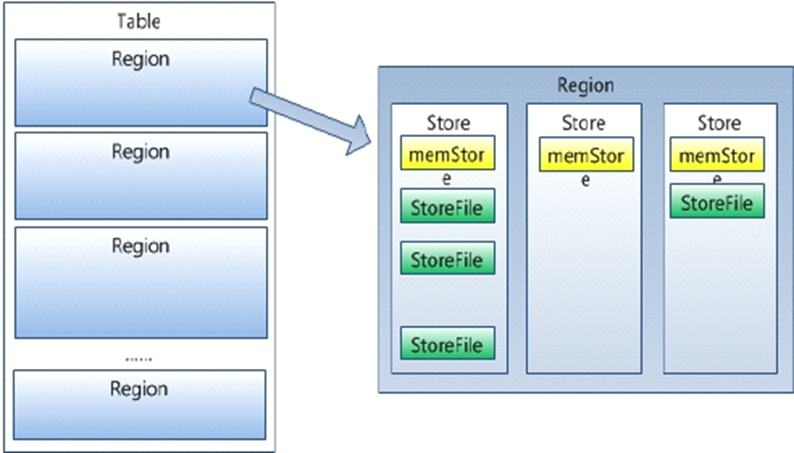
Memstore 与 storefile
一个region由多个store组成,一个store对应一个CF(列族)
store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile
当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
客户端检索数据,先在memstore找,找不到再找storefile
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。