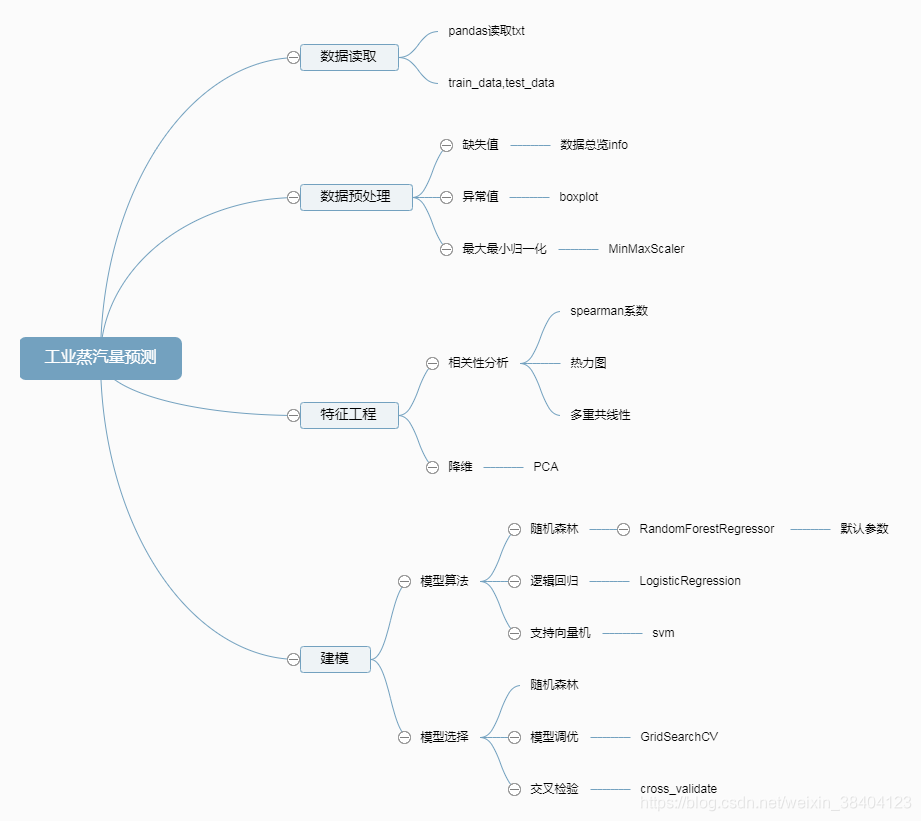
#导入需要的库
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn import svm #支持向量机
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA #主成分分析法
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
from sklearn.grid_search import GridSearchCV
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.model_selection import train_test_split,cross_val_score,cross_validate # 交叉验证所需的函数
from sklearn.model_selection import KFold,LeaveOneOut,LeavePOut,ShuffleSplit # 交叉验证所需的子集划分方法
from sklearn.model_selection import StratifiedKFold,StratifiedShuffleSplit # 分层分割
from sklearn.ensemble import RandomForestRegressor #随机森林
from statsmodels.stats.outliers_influence import variance_inflation_factor #多重共线性方差膨胀因子
#读取数据
train_data0=pd.read_table('C:\\Users\\Administrator\\Desktop\\zhengqi_train.txt',sep='\t')
test_data0=pd.read_table('C:\\Users\\Administrator\\Desktop\\zhengqi_test.txt',sep='\t')
#训练数据总览
train_data0.info()
#异常值
plt.figure(figsize=(18, 10))
plt.boxplot(x=train_data0.values,labels=train_data0.columns)
plt.hlines([-7.5, 7.5], 0, 40, colors='r')
plt.show()
#剔除异常值
train_data0=train_data0[train_data0['V9']>-7.5]
train_data0.describe()
#最大最小归一化
min_max_scaler = preprocessing.MinMaxScaler()
train_data1=min_max_scaler.fit_transform(train_data0)
test_data1=min_max_scaler.fit_transform(test_data0)
train_data1=pd.DataFrame(train_data1)
train_data1.columns=train_data0.columns
test_data1=pd.DataFrame(test_data1)
test_data1.columns=test_data0.columns
#训练数据分布情况
plt.figure(figsize=(18, 18))
for column_index, column in enumerate(train_data1.columns):
plt.subplot(10, 4, column_index + 1)
g=sns.kdeplot(train_data1[column])
g.set_xlabel(column)
g.set_ylabel('Frequency')
#特征相关性
plt.figure(figsize=(20, 16))
colnm = train_data1.columns.tolist()
mcorr = train_data1[colnm].corr(method="spearman")
mask = np.zeros_like(mcorr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
cmap = sns.diverging_palette(220, 10, as_cmap=True)
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f')
plt.show()
#特征筛选
mcorr=mcorr.abs()
numerical_corr=mcorr[mcorr['target']>0.1]['target']
print(numerical_corr.sort_values(ascending=False))
index0 = numerical_corr.sort_values(ascending=False).index
print(train_data1[index0].corr('spearman'))
#多重共线性
new_numerical=['V0', 'V2', 'V3', 'V4', 'V5', 'V6', 'V10','V11',
'V13', 'V15', 'V16', 'V18', 'V19', 'V20', 'V22','V24','V30', 'V31', 'V37']
X=np.matrix(train_data1[new_numerical])
VIF_list=[variance_inflation_factor(X, i) for i in range(X.shape[1])]
VIF_list
#PCA方法降维
#保持90%的信息
pca = PCA(n_components=0.9)
new_train0=pca.fit_transform(train_data1.iloc[:,0:-1])
new_train0=pd.DataFrame(new_train0)
new_train0.describe()
train=new_train0
pca = PCA(n_components=16)
test=pca.fit_transform(test_data1)
target=train_data1.iloc[:,-1]
#数据分割
train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,
random_state=0)
#随机森林预测模型
m1=RandomForestRegressor()
m1.fit(train_data, train_target)
score1=mean_squared_error(test_target,m1.predict(test_data))
print(score1)
#逻辑回归预测模型
m2=LogisticRegression(C=1000.0,random_state=0)
m2.fit(train_data.astype('int'), train_target.astype('int'))
score2=mean_squared_error(test_target,m2.predict(test_data.astype('int')))
print(score2)
#支持向量机预测模型
m3=svm.SVC(kernel='poly')
m3.fit(train_data.astype('int'), train_target.astype('int'))
score3=mean_squared_error(test_target,m3.predict(test_data.astype('int')))
print(score3)
#多次重复,查看随机森林预测模型预测结果稳定性
model_accuracies = []
for repetition in range(100):
train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,
random_state=0)
m1=RandomForestRegressor()
m1.fit(train_data, train_target)
score=mean_squared_error(test_target,m1.predict(test_data))
model_accuracies.append(score)
sns.distplot(model_accuracies)
#网格搜索,参数调优
param_grid={'n_estimators':[1,5,10,25,50,100],
'max_features':('auto','sqrt','log2')}
m=GridSearchCV(RandomForestRegressor(),param_grid)
m=m.fit(train_data,train_target)
score=mean_squared_error(test_target,m.predict(test_data))
print(score)
print(m.best_score_)
print(m.best_params_)
#交叉检验
m = RandomForestRegressor(n_estimators=100,max_features='auto')
scores = cross_validate(m,train,target,
scoring='mean_squared_error', cv=5)
scores
#结果输出
m = RandomForestRegressor(n_estimators=100,max_features='auto')
m.fit(train_data, train_target)
predict = m.predict(test)
np.savetxt('C:\\Users\\Administrator\\Desktop\\predict.txt',predict)
工业蒸汽量预测
猜你喜欢
转载自blog.csdn.net/weixin_38404123/article/details/86645289
今日推荐
周排行