说到spark的shuffle,我们就不得不先提一下hadoop的shuffle,但是过程我就不说啦,有兴趣的可以看我之前发的MR原理的博文里面有说hadoop的MR shuffle的运行方式https://blog.csdn.net/dudadudadd/article/details/111593379
总的来说,hadoop哪怕到现在默认的也是那么一套shuffle形式,当然hadoop也是支持你自定义分组来该shuffle结果的
这个默认的shuffle处理方式就是哈希,一开始的时候spark跟着老大哥hadoop看齐,shuffle的方式模仿了老大哥的hash思想,以key的hash值,往外溢出文件的形式,进行shuffle
敲黑板了注意! 我有必要提醒各位一句的是,spark的shuffle第一代的时候,只是模仿了hadoop的思想,并不是照搬啊!
有人以为是一模一样的,他们之间是有差异的,hadoop是以环形缓冲区的模式基于内存向外溢出文件,具体怎么出的可以去看我之前发的mr原理,而spark第一代的时候是没有缓冲区、排序等那些高级操作,他是直接按key的hash往外溢出数据
但是之后用着用着发现不对劲,发现老大哥,在舍弃物理空间,来换取计算结果的路上越走越远,一直不回头,要在跟着老大哥的步伐走,老大哥一次运行基于磁盘出一个结果,但是Spark自身链式调用,一调一大串,这要是吧物理空间给搞挂了,那可不是闹着玩的。
这里就讲到了这篇论文的第一个知识点,就是Spark第一代的hashshuffle,首先第一代我给大家配个图,大家一目就了然了
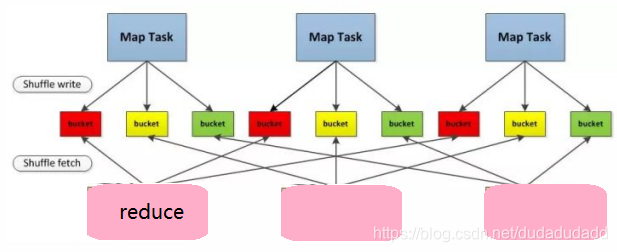
如上图,第一代的时候,因为一个任务会产生多个map,而map的多少默认是由数据的切片多少决定的,比方说一个很大的文件,五个切片存储,那么默认就会启动五个map去拉数据,Map的数量我们是可以改的,但是由这里讲的是shuffle,所以就不涉及了,有兴趣的大家可以去看看其他资料
言归正传,在第一代的时候,每个map之间向外溢出数据的文件不是互通的,也就是说,任务有多少个reduce,那么每一个map都会开放reduce个溢出文件,reduce的个数又是由分区个数决定的,这也就导致了,一开始的时候,我们设置的分区数越大,那么所消耗的物理空间有越大,比如map为3,reduce为3,那么溢出的文件数就有9个,这就是Spark第一代的shuffle,
大量的溢出文件,对输出流以及内存来说消耗都是巨大的,一个搞不好就OOM了
这个时候spark有点慌了,心说老大哥你真是坑我呀,你舍弃这么多空间获得一个结果就落盘,但是我不一样呀,我链式调用一运行一大片算法,这么奢侈的浪费物理空间,那万一哪一天垮了怎么办?
所以这个时候,spark在shuffle的机制上开始自强了,就有了spark的shuffle2.0时代,2.0的时候大方向还是Hashshuffle,但是优化了溢出文件的方式,溢出文件不在是不互通的,而是以executor为单位,每一个executor中的所有map溢出的相同分区的数据都只溢出到一个文件中
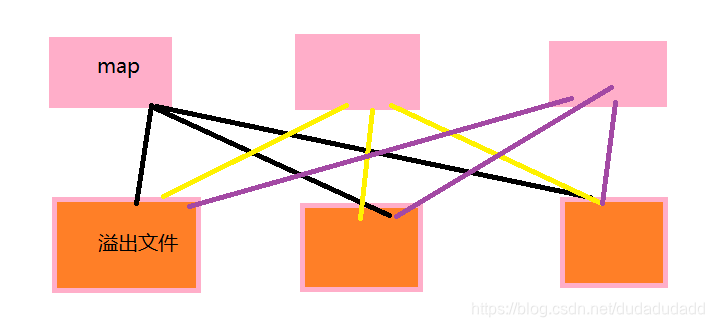
但是这种优化之后的Hashshuffle,还是慢慢的又无法满足市场需求了,因为它是直接输出,没有排序一说,也是这不能说是Spark自身的一个缺陷,而是一个设计的必然,Spark的rdd集相当灵活,脱离的MR的key-value键值对数据的范围,所以Spark设计之初,也就没有在意排序之类的操作,而且溢出文件的格式,对于Spark来说还是很多
因此在这些需求变得越来越有必要的时候,Spark也是马上对自己的shuffle进行了升级,出现了Spark的3.0时代,叫做sort shuffle
sort shuffle一出世,好家伙,那可不得了,连executor为单位的溢出文件也不要了,所以的map往一个文件里输出,而数据在溢出这个文件中的时候,也不是直接进入的,是被按照原先的分区id进行排序之后进入,这里说的分区id是Spark每个分区的标识,这种方式就有点像Hadoop的分组思想,只不过Spark用来分区了,而分区内的数据会默认按照Hash值排序的,不过每个分区的范围是多少,分区和分区之前的偏移量是多少,这些数据则被记录在另一个索引文件中,也就是说,sort shuffle只会有两个文件产生,可以说是弥补了Hash shuffle的所以弊端,但是需要记录索引文件因此在性能上还是没有达到巅峰
这还没完,可以说Spark能发展的这么火不是没有原因的
Spark有三个重要的版本:
第一个是1.5.0版本,在这个版本中Spark对sort shuffle再次升级,把索引文件舍弃了,将本基于对象结构的排序,变为了直接在二进制系列化数据上排序,并使用指针代替分区的范围以及偏移量,这种shuffle被称为Unsafe shuffle,这种sort shuffle,由于不在需要耗费多余的cpu和io流去理会索引文件,因此在资源使用上更加的优秀
第二个是1.6.0版本,Spark因为Unsafe shuffle使用要求有些高,因此把普通的sort shuffle和Unsafe shuffle融合,Spark在任务运行的时候自动识别用那种shuffle
第三个是2.0.0版本,在这个版本中,Spark将Hash shuffle彻底淘汰,从底层代码中将Hash shuffle删除,从此Spark的shuffle只有sort shuffle,直到至今为止