最近在学习大数据的数据迁移,要从关系型数据库里导数据到hive数据库里,其中碰到了很多麻烦,曾试过使用sqoop方式导入数据不过功能不够全面比如表结构及数据筛选问题,现在使用kettle来进行数据迁移工作,其中碰到了很多问题不过都能给出相应的解决方案,如此写下这篇文档供各位工程师参考
那么如何将mysql数据导入到hive里呢,kettle里有自带方法,可以通过表输入和表输出来实现,不过自带的方法载入数据极其缓慢,不推荐使用这种方法
以下着重讲解我使用的方法
1,将mysql数据导入到hdfs里
我使用的是kettle7.0,hadoop是2.6,hive是1.2
先在kettle建立转换,添加表输入
配置相关查询条件与数据连接
在这儿hive里因为没有相关表,因此再建立个表输出
将表输入连接上表输出
这儿很重要,需要先配置好hive的相关连接
其中目标表可以在这儿定义,也可以在外定义变量,如果hive里有相应的表可以直接跳过这一步
点击下面的sql,开始创建从mysql输出的对应表
红框中的一段是原本没有的,可以自己添加相应hive表分隔符号,完成后点击执行即可
然后
然后添加一个

这儿的配置非常重要,关系到导入hive表中的数据
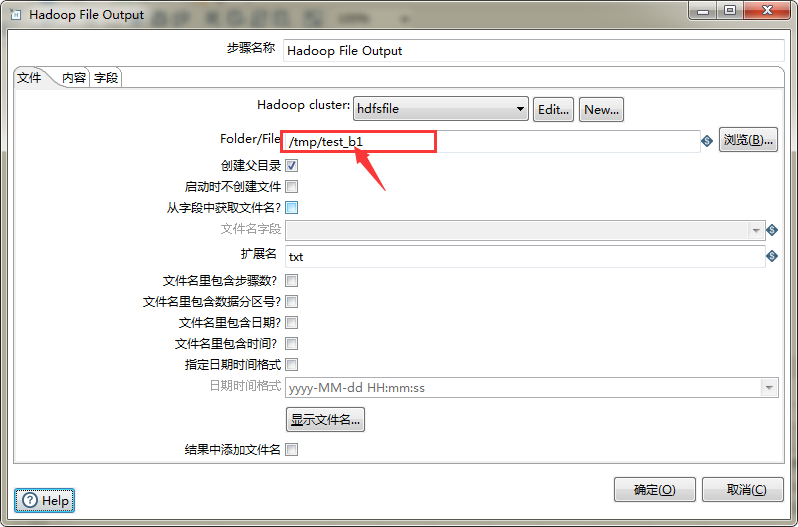
连接上hdfs目录后,这儿可以选择缓存目录,在目录后可添加名字作为新文件来保存
内容这儿可以选择相应分隔符来对数据分隔操作,头部一定要去掉,不然导入hdfs时会将表头的字段名一起导入,还有编码最好是换成utf-8保证中文的使用
字段这儿要先获取字段,然后先关字段要选择对应格式,比如我这儿id是0000054,就要选为#格式,不然会使最后hive导入的id这儿为null,日期也是
到这儿为止就可以运行下转换了
转换完成的文件会放在hdfs系统里,可以使用eclipse的dfs功能查看hadoop下的hdfs文件
2,将hdfs文件导入到hive数据库里
这一步很重要,目前我使用的方法是直接load文件进去
这个是kettle的工作,转换里的是上面的步骤,新添加个hadoop copy files
左边为原始目录也就是存放hdfs文件的地址,后面是hive数据库文件目录的地址,如果需要直接替换hive里面的内容在设置里勾选替换就可以了