相信有了前面三章的基础了解,我们对爬虫的基础知识已经有所掌握。
本篇内容是从易到难给大家讲解一些常用爬虫的手写。
包括图片爬虫、链接爬虫、多线程爬虫等等。
京东图片爬虫实战:
实现目标:将京东商城手机类的商品图片全部下载到本地。
首先打开京东首页。选择我们要下载的商品分类链接。

点击链接之后,我们会看到这样一个Url
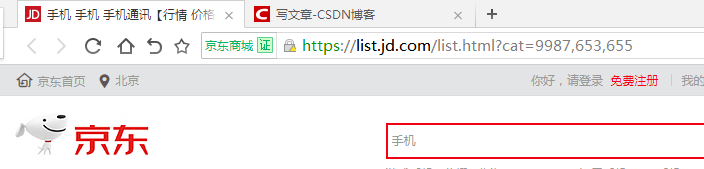
这就是我们要爬取的第一个页面。
复制下来他的url。https://list.jd.com/list.html?cat=9987,653,655
接下来将页面拖动到最后可看到
页面解析:
这里有很多分页。那么如何获取其他页面的信息呢。
我们需要观察网址的变化:点击分页观察url。


可发现,每页的字段都有一个page,通过GET的方式请求的。我们可以得到页面url的关键字段:

page=2代表着第几页。
所以我们可以使用for循环来获取其他的页面。
信息提取:
我们需要的是每个页面的图片信息。所以需要使用正则表达式来匹配源码中图片的链接部分。然后通过urllib.request.urlretrieve() 将对应链接的图片保存到本地。
信息过滤:
除了我们想要的手机图片外,还会匹配到其他跟我们目标不同的图片。
所以我们要先进行一次信息过滤。只留下我们所需要的。
我们F12进入审查模式

观察发现图片都是在
也就是说其实中的<div class="page clearfix">可以作为结束的特殊标识。所以我们进行的第一次过滤,我们的正则表达式可以构造为:
pat1='<div id ="plist".+?<div class = "page clearfix">'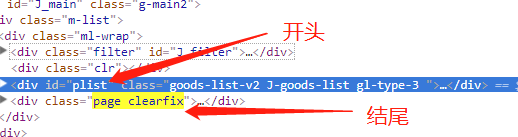
每个页面之间的基本格式是一样的,只是其中的图片链接网址不一样,所以此时,我们可以根据该规律构造出我们需要的正则表达式:
'<img width="200" heght="200" data-img="1" data-lazy-img = "//(.+?\.jpg)">'
编写代码:


import re #导入re模块
import urllib.request,urllib.error #导入urllib
def craw(url,page): #定义一个函数
html=urllib.request.urlopen(url).read() #获取页面信息
html=str(html) #将信息转化为字符串
pat1='<div id="plist".+? <div class="page clearfix">'
result1=re.compile(pat1).findall(html) #在html1内查询符合pat1的
result1=result1[0] #获取起始位置的plist,也就是第一个包含了所以图片的。
pat2 ='<img width="220" height="220" data-img="1" data-lazy-img="//(.+?\.jpg)">'
imagelist = re.compile(pat2).findall(result1) #在result1内查询所以的图片链接
x = 1
for imageurl in imagelist: #这里我没有用with open、是我手动创建的文件夹。
imagename = "D:/work/日常任务2/img1/"+str(page)+str(x)+".jpg"
imageurl = "http://"+imageurl
try:
urllib.request.urlretrieve(imageurl,filename=imagename)
except urllib.error.URLError as e:
if hasattr(e,"code"):
x+=1
if hasattr(e,"reason"):
x+=1
x+=1
if __name__ == '__main__':
for i in range(1,30): #30代表获取的范围
url= "http://list.jd.com/list.html?cat=9987,653,655&page="+str(i)
craw(url,i)


第一个实战也圆满结束了,我们获取了第一页到29页的所有目标图片,并且将图片存储到本地目录img1下。图片的名字为:页号+顺序号.jpg
通过这个项目的学习,相信大家已经对如何手写爬虫代码有了一定的思路,可以尝试下自己手写一个网络爬虫项目了。
链接爬虫实战:
所谓的 链接爬虫 就是说 我们想把一个网页中所有得链接地址提取出来,那么我们就需要来用链接爬虫来实现。
本项目链接爬虫实现的思路如下:
1、确定要爬取的入口链接。
2、根据需求构建好链接提取的正则表达式。
3、模拟成浏览器并爬取对应网页。
4、根据2中的正则表达式提取出该网页中包含的链接。
5、过滤掉重复的链接。
6、后续操作,保存写入打印等等
下面我们模拟一下获取blog.csdb.net网页上的所有链接。


import re
import urllib.request
def getlink(url):
headers = ("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) "
"AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/39.0.2171.71 Safari/537.36")
opener = urllib.request.build_opener() #模拟成浏览器
opener.addheaders = [headers]
urllib.request.install_opener(opener) #将opener设置为全局global
file = urllib.request.urlopen(url) #获取页面信息
data = str(file.read()) #转换格式
pat = '(https?://[^\s)";]+\.(\w|/)*)' #根据需求构建好链接表达式
link = re.compile(pat).findall(data) #匹配我们需要的信息
link = list(set(link)) #通过转换去除重复元素
return link
url = "http://blog.csdn.net/" #将爬取的地址赋值给url
linklist = getlink(url) #获取对方网页中包含的链接地址
for link in linklist: #遍历我们需要的链接
print(link[0])
可看到打印结果:

链接爬取项目完成。
嗅事百科爬虫实战:
项目目标:爬取嗅事百科上的段子。
(www.qiushibaike.com)
本项目实现思路:
1、如同爬取京东图片一样,分析页面规律,构造出网址变量。通过循环进行爬取。
2、构建一个自定义函数,来实现爬取某个网页上的段子。
3、通过循环分别获取多页的各业URL链接,每页分别调用一次getcontent(url.page)函数。
长话短说、看了这么久直接上代码吧。



分别爬取了用户及其对应的内容。代码不难,加油
import urllib.request
import re
def getcontent(url,page):
#老套路 先把自己模拟成浏览器 可百度搜索UA池
headers = ("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64)"
" AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36")
opener = urllib.request.build_opener() #构造
opener.addheaders = [headers]
urllib.request.install_opener(opener) #设置opener为全局
data = urllib.request.urlopen(url).read().decode('utf-8')
#构建对应用户提取的正则表达式
userpat ='<div class="author clearfix">.*?<h2>(.*?)</h2>'
#构建内容提取的正则表达式
contentpat = '<div.*?span>(.*?)</span>'
#寻找所有的用户
userlist = re.compile(userpat,re.S).findall(data) #re.S在匹配时为点任意匹配模式
#所有内容
contentlist = re.compile(contentpat,re.S).findall(data)
# print(data)
x=1
for content in contentlist:
content = content.replace("\n","")
name = "content"+str(x)
exec(name+'=content')
x+=1
y=1
for user in userlist:
name = "content"+str(y)
print("用户"+str(page)+str(y)+"是:"+user)
print("内容是:")
exec("print("+name+")")
print("\n")
y+=1
for i in range(1,3): #rang(1,3)为爬取页面范围
url = "http://www.qiushibaike.com/hot/page/"+str(i)
getcontent(url,i)
运行结果如下:

多线程爬虫:
首先,什么是多线程爬虫。
之前我们写的爬虫,程序在执行起来是有先后顺序的,这种执行解构可以称为单线程结构,对应的爬虫称为单线程爬虫。如下图所示

而多线程爬虫,指的是爬虫中的某部分程序可以并行执行,既在多条线上执行,这种执行结构称为多线程爬虫,对应的爬虫称为多线程爬虫。如下图

多线程爬虫实战:
要在python中使用多线程,我们可以导入threading模块使用多线程功能。我们可以定义一个类并继承threading.Thread类,将该类定义成一个线程。
在该类中,可以使用__init__(self)方法对线程进行初始化,在run(self)方法中写上该线程要执行的程序。我们可以声明多个这样的类来构建多个线程并通过对应线程对象的start()方法启动对应的线程。
写一个简单的多线程功能:
import threading
class A(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
for i in range(10):
print("我是线程A")
class B(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
for i in range(10):
print("我是线程B")
t1=A()
t1.start()
t2=B()
t2.start()
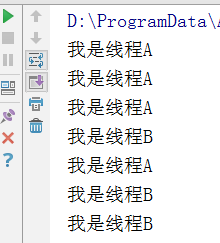
可以看出,A与B是并行执行的。
下面是多线程爬取糗事百科段子的代码:
看不太明白也没关系,我们后续也会进行更细致的讲解。
# 使用了线程库
import threading
# 队列
from queue import Queue
# 解析库
from lxml import etree
# 请求处理
import requests
# json处理
import json
import time
class ThreadCrawl(threading.Thread):
def __init__(self, threadName, pageQueue, dataQueue):
#threading.Thread.__init__(self)
# 调用父类初始化方法
super(ThreadCrawl, self).__init__()
# 线程名
self.threadName = threadName
# 页码队列
self.pageQueue = pageQueue
# 数据队列
self.dataQueue = dataQueue
# 请求报头
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
def run(self):
print("启动 " + self.threadName)
while not CRAWL_EXIT:
try:
# 取出一个数字,先进先出
# 可选参数block,默认值为True
#1. 如果对列为空,block为True的话,不会结束,会进入阻塞状态,直到队列有新的数据
#2. 如果队列为空,block为False的话,就弹出一个Queue.empty()异常,
page = self.pageQueue.get(False)
url = "http://www.qiushibaike.com/8hr/page/" + str(page) +"/"
#print url
content = requests.get(url, headers = self.headers).text
time.sleep(1)
self.dataQueue.put(content)
#print len(content)
except:
pass
print("结束 " + self.threadName)
class ThreadParse(threading.Thread):
def __init__(self, threadName, dataQueue, filename, lock):
super(ThreadParse, self).__init__()
# 线程名
self.threadName = threadName
# 数据队列
self.dataQueue = dataQueue
# 保存解析后数据的文件名
self.filename = filename
# 锁
self.lock = lock
def run(self):
print("启动" + self.threadName)
while not PARSE_EXIT:
try:
html = self.dataQueue.get(False)
self.parse(html)
except:
pass
print("退出" + self.threadName)
def parse(self, html):
# 解析为HTML DOM
html = etree.HTML(html)
node_list = html.xpath('//div[contains(@id, "qiushi_tag")]')
for node in node_list:
# xpath返回的列表,这个列表就这一个参数,用索引方式取出来,用户名
username = node.xpath('./div/a/@title')[0]
# 图片连接
image = node.xpath('.//div[@class="thumb"]//@src')#[0]
# 取出标签下的内容,段子内容
content = node.xpath('.//div[@class="content"]/span')[0].text
# 取出标签里包含的内容,点赞
zan = node.xpath('.//i')[0].text
# 评论
comments = node.xpath('.//i')[1].text
items = {
"username" : username,
"image" : image,
"content" : content,
"zan" : zan,
"comments" : comments
}
# with 后面有两个必须执行的操作:__enter__ 和 _exit__
# 不管里面的操作结果如何,都会执行打开、关闭
# 打开锁、处理内容、释放锁
with self.lock:
# 写入存储的解析后的数据
self.filename.write(json.dumps(items, ensure_ascii = False).encode("utf-8") + "\n")
CRAWL_EXIT = False
PARSE_EXIT = False
def main():
# 页码的队列,表示20个页面
pageQueue = Queue(20)
# 放入1~10的数字,先进先出
for i in range(1, 21):
pageQueue.put(i)
# 采集结果(每页的HTML源码)的数据队列,参数为空表示不限制
dataQueue = Queue()
filename = open("duanzi.json", "a")
# 创建锁
lock = threading.Lock()
# 三个采集线程的名字
crawlList = ["采集线程1号", "采集线程2号", "采集线程3号"]
# 存储三个采集线程的列表集合
threadcrawl = []
for threadName in crawlList:
thread = ThreadCrawl(threadName, pageQueue, dataQueue)
thread.start()
threadcrawl.append(thread)
# 三个解析线程的名字
parseList = ["解析线程1号","解析线程2号","解析线程3号"]
# 存储三个解析线程
threadparse = []
for threadName in parseList:
thread = ThreadParse(threadName, dataQueue, filename, lock)
thread.start()
threadparse.append(thread)
# 等待pageQueue队列为空,也就是等待之前的操作执行完毕
while not pageQueue.empty():
pass
# 如果pageQueue为空,采集线程退出循环
global CRAWL_EXIT
CRAWL_EXIT = True
print("pageQueue为空")
for thread in threadcrawl:
thread.join()
print("1")
while not dataQueue.empty():
pass
global PARSE_EXIT
PARSE_EXIT = True
for thread in threadparse:
thread.join()
print("2")
with lock:
# 关闭文件
filename.close()
print("谢谢使用!")
if __name__ == "__main__":
main()
总结:
本篇文章是基于前面3篇基础而做出来的实战项目。内容由易到难。
只要多回顾之前的知识,掌握好爬虫的思维,就能顺利写出来我们所需要的爬虫代码。
后续文章会继续讲解,请关注博客更新。
下一篇:初识Python爬虫框架Scrapy