2014年ICLR。
overfeat是一个feature extractor。
主要特点是网络前5层做特征提取层,后面几层可以修改以适应分类、定位和检测不同任务。
两个重要的基础知识:FCN和offset max-pooling。
FCN可以满足网络输入任意大小图像的需求。
offset max-pooling:作用于layer 5 pooling前的特征图。
考虑AlexNet是使用multi-view的方式来投票分类测试;然而这种方式可能忽略图像的一些区域,在重叠的view区域会有重复计算;而且还只在单一的图片缩放比例上测试图片,这个单一比例可能不是反馈最优的置信区域。
作者在多个缩放比例,不同位置上,对整个图片密集地进行卷积计算;这种滑窗的方式对于一些模型可能由于计算复杂而被禁止,但是在卷积网络上进行滑窗计算不仅保留了滑窗的鲁棒性,而且还很高效。每一个卷积网络的都输出一个m*n-C维的空间向量,C是分类的类别数;不同的缩放比例对应不同的m和n。
因为物体和view可能没有很好的匹配分布(物体和view越好的匹配,网络输出的置信度越高)。为了解决这个问题,我们采取在最后一个max-pooling层换成offset max-pooling,平移pooling;这种平移max-pooling是一种数据增益技术。
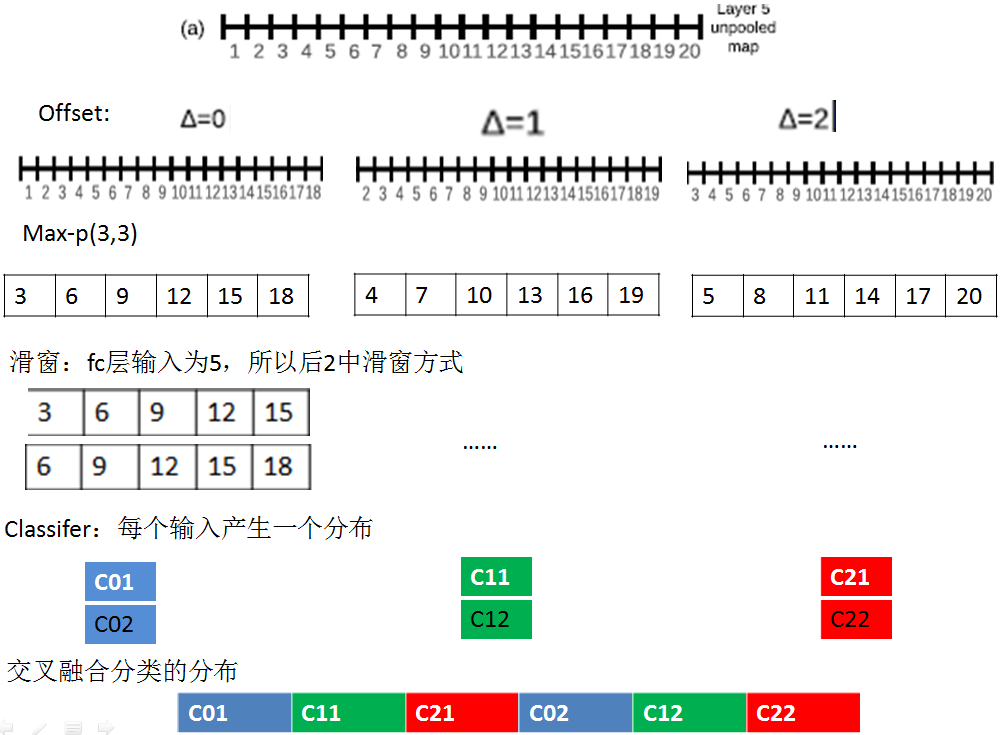
其实这个offset max-pooling技术提升效果并不明显。
同时在各个view和缩放比例下计算分类和回归网络,分类器对类别c的输出作为类别c在对应比例和view出现的置信分数;
每个回归网络(每个类分别一个回归网络),以最后一个卷积层作为输入,回归层也有两个全连接层,隐层单元为4096,1024(为什么作者没有说,估计也是交叉实验验证的),最后的输出层有4个单元,分别是预测bounding box的四个边的坐标。和分类使用offset-pooling一样,回归预测也是用这种方式,来产生不同的预测结果。
结合预测:
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合(坐标平均值)放入B中,在进行循环计算。
最终的结果通过融合具有最高置信度的bounding box给出。
检测和分类训练阶段相似,但是是以空间的方式进行;一张图片中的多个位置可能会同时训练。和定位不通过的是,图片内没有物体的时候,需要预测背景。