缓存的有点:
1)加速读写,因为缓存都是全内存的(比如Redis和Memcached),而存储层通常读写性能不够强悍,通过缓存可以有效地加速读写。
2)帮助减少后端的访问量和复杂计算,降低了后端的负载。
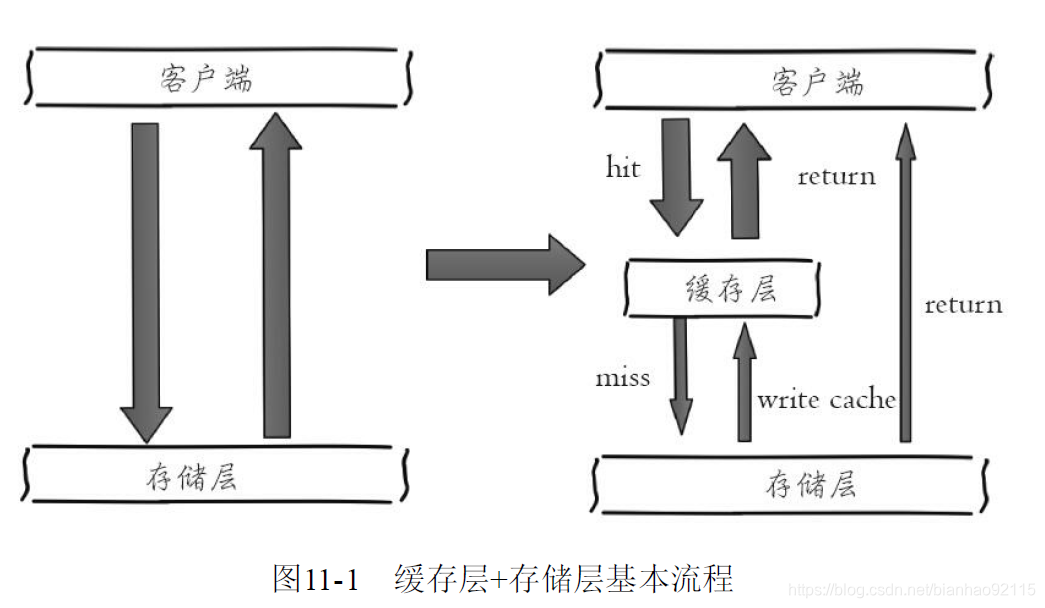
数据不一致:缓存层和存储层的数据存在着一定的时间窗口不一致性。
缓存的使用场景基本包含如下两种:
1)开销大的复杂计算,一些复杂的操作或者计算(例如大量的联表查询,分组计算),如果不加缓存,不但无法满足高并发,也会给MySql带来巨大负担。
2)加速请求响应。
缓存更新策略:
缓存中的数据通常是有生命周期的,需要在指定时间后被删除或者更新。
1.LRU/LFU/FIFO算法剔除
使用场景:剔除算法用于缓存使用量超过了预设最大值的时候,如果对现有数据进行剔除。
要清理哪些数据是由算法决定的,开发人员只能决定使用哪种算法,数据一致性是最差的。
2.超时剔除
可以给缓存设置过期时间,过期后自动剔除。例如Redis提供的expire命令。存在数据不一致问题。
3.主动更新
应用方对数据一致性要求高,需要在真实数据更新后立即更新缓存数据。可以利用消息系统或者其他方式通知缓存更新。
一致性最高,但如果主动更新发生问题,那么这条数据很可能长时间不会更新,建议和超时剔除一起使用。
低业务一致性建议配置最大内存和淘汰策略的方式使用。
高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后剔除脏数据。
穿透优化
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中。
缓存穿透可能会使后端存储负载过大,如果发现大量存储层空命中,可能就是出现了缓存穿透的问题。
造成缓存穿透的问题有两个:1)自身业务代码或者数据出现问题。2)一些恶意,爬虫等造成的大量空命中。
可以通过缓存空对象来解决这个问题。
无底洞优化
为了业务扩容添加了大量Redis或者Memecache节点后,性能反而下降了。这时因为大量节点做水平扩容,批量操作通常需要从不同节点上获取,浪费了很多时间。
无底洞问题原因:
客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时会不断增大。
网络连接数变多,对节点的性能也有一定的影响。
缓存雪崩,指的是缓存层宕机后,流量全部跑向后端。
1)保证缓存层服务高可用性。Redis Sentinel和Redis Cluster 都实现了高可用。
2)依赖隔离组件为后端限流并降级。无论是缓存层还是存储层都会有出错的概率,如果有一个资源不可用,可能会造成线程全部阻塞在这个资源上。
降级机制在高并发系统中是非常普遍的:比如推荐服务中,如果是个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是空的。
在实际项目中,我们需要对重要的资源(例如Redis,MySQL,HBase,外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中。但是线程池如何管理,比如关闭,开启,资源池阀值等做起来还是相当复杂的,这里推荐一个Java依赖隔离工具hystrix。
互斥锁:如果有多个线程都在构造缓存时,如果set(nx和ex)结果为true,说明此时没有其他线程重建缓存,可以执行重建缓存的逻辑。如果set的结果为false,说明此时已经有其他线程正在执行构建缓存的工作了。