title: "《Redis的设计与实现》读书笔记(1)"
date: 2019-05-29T23:40:00+08:00
draft: false
tags: ["Redis","读书笔记"]
---
一、数据结构与对象
1.SDS(简单字符串)
struct sdsstr{
int len;
int free;
char buf[];
};//sds.h小结:
- Redis只会使用C字符串作为字面量,在大多数情况下,使用SDS作为字符串表示
- SDS的优点:
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少修改字符串长度是所需的内存重分配次数
- 二进制安全
- 兼容部分C字符串
2.list(双向链表)
typedef struct listNode{
struct listNode *orev;
struct listNode *next;
void *value;
}listNode; //adlist.h
typedef struct list{
listNode *head;
listNode *tail;
unsigned long len;
void* (*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr,void *key);
}list;//adlist.h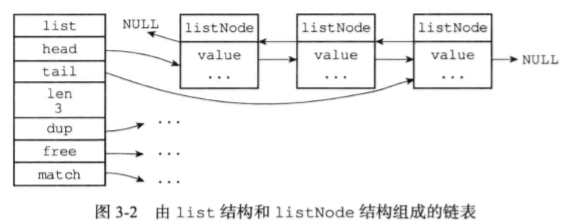
小结:
- 链表被广泛用于实现Redis的各种功能,如列表键,发布订阅,慢查询,监视器等
- Redis的链表实现是双端链表
- Redis的链表无环
- 因为value是void*类型的,所以Redis的链表可以用于保存各种不同类型的值
3.dict(字典)
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 链往后继节点
struct dictEntry *next;
} dictEntry;
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
/*
* 字典
*
* 每个字典使用两个哈希表,用于实现渐进式 rehash
*/
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2个)
dictht ht[2];
// 记录 rehash 进度的标志,值为-1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
} dict;
/*
* 特定于类型的一簇处理函数
*/
typedef struct dictType {
// 计算键的哈希值函数, 计算key在hash table中的存储位置,不同的dict可以有不同的hash function.
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比两个键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 键的释构函数
void (*keyDestructor)(void *privdata, void *key);
// 值的释构函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
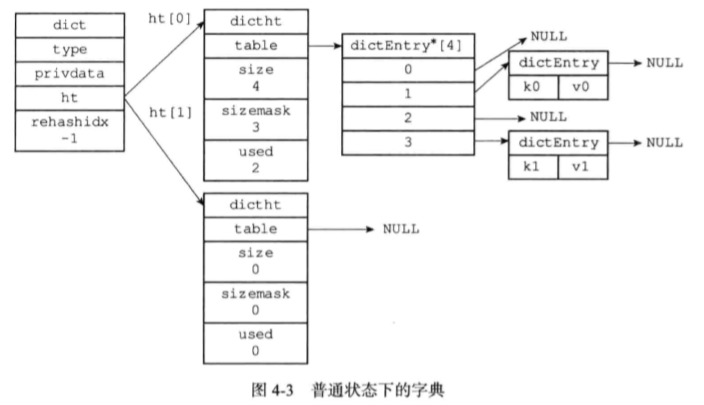
小结:
- 字典被广泛用于实现Redis的各种功能,其中包括数据库和哈希键
- 使用链地址解决冲突
- 字典中有两个哈希表(ht[0],ht[1]),一个平常使用(ht[0]),一个rehash时使用(ht[1])
- 为啥rehash:使负载因子在一个合理的范围内,需要对哈希表的大小进行扩展或收缩
- 扩展时机:执行BGSAVE或BGREWRITEADF时,负载因子大于5;没有正在执行BGSAVE和BGREWRITEAOF时,负载因子大于1.
- 收缩时机: 负载因子小于0.1
- rehash步骤:为ht[1]分配空间(扩展时:2倍,收缩时:大于used的2^n)-> 重新计算哈希值和索引值,放置到ht[1]的指定位置 ->释放ht[0],将ht[1]设置为ht[0],并在ht[1]设置一个空白哈希表
- rehash是渐进式的,通过$rehashidx$字段记录进度
- 为啥rehash:使负载因子在一个合理的范围内,需要对哈希表的大小进行扩展或收缩
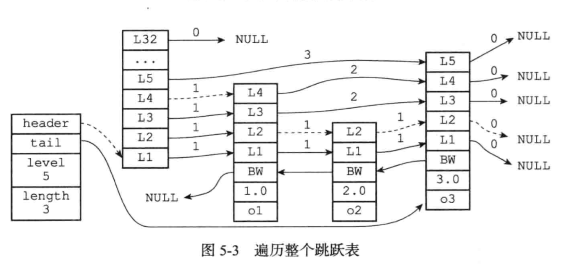
4.skiplist(跳跃表)
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode; //redis.h
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;//redis.h
// t_zset.c 跳跃表的增删
/*
* 创建一个层数为 level 的跳跃表节点,
* 并将节点的成员对象设置为 obj ,分值设置为 score 。
*
* 返回值为新创建的跳跃表节点
*
* T = O(1)
*/
zskiplistNode *zslCreateNode(int level, double score, robj *obj) {
// 分配空间
zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
// 设置属性
zn->score = score;
zn->obj = obj;
return zn;
}
/*
* 创建并返回一个新的跳跃表
*
* T = O(1)
*/
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 分配空间
zsl = zmalloc(sizeof(*zsl));
// 设置高度和起始层数
zsl->level = 1;
zsl->length = 0;
// 初始化表头节点
// T = O(1)
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
// 设置表尾
zsl->tail = NULL;
return zsl;
}
/*
* 释放给定的跳跃表节点
*
* T = O(1)
*/
void zslFreeNode(zskiplistNode *node) {
decrRefCount(node->obj);
zfree(node);
}
/*
* 释放给定跳跃表,以及表中的所有节点
*
* T = O(N)
*/
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
// 释放表头
zfree(zsl->header);
// 释放表中所有节点
// T = O(N)
while(node) {
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
// 释放跳跃表结构
zfree(zsl);
}
/*
* 创建一个成员为 obj ,分值为 score 的新节点,
* 并将这个新节点插入到跳跃表 zsl 中。
*
* 函数的返回值为新节点。
*
* T_wrost = O(N^2), T_avg = O(N log N)
*/
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
redisAssert(!isnan(score));
// 在各个层查找节点的插入位置
// T_wrost = O(N^2), T_avg = O(N log N)
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
// 如果 i 不是 zsl->level-1 层
// 那么 i 层的起始 rank 值为 i+1 层的 rank 值
// 各个层的 rank 值一层层累积
// 最终 rank[0] 的值加一就是新节点的前置节点的排位
// rank[0] 会在后面成为计算 span 值和 rank 值的基础
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 沿着前进指针遍历跳跃表
// T_wrost = O(N^2), T_avg = O(N log N)
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
// 比对分值
(x->level[i].forward->score == score &&
// 比对成员, T = O(N)
compareStringObjects(x->level[i].forward->obj,obj) < 0))) {
// 记录沿途跨越了多少个节点
rank[i] += x->level[i].span;
// 移动至下一指针
x = x->level[i].forward;
}
// 记录将要和新节点相连接的节点
update[i] = x;
}
/* we assume the key is not already inside, since we allow duplicated
* scores, and the re-insertion of score and redis object should never
* happen since the caller of zslInsert() should test in the hash table
* if the element is already inside or not.
*
* zslInsert() 的调用者会确保同分值且同成员的元素不会出现,
* 所以这里不需要进一步进行检查,可以直接创建新元素。
*/
// 获取一个随机值作为新节点的层数
// T = O(N)
level = zslRandomLevel();
// 如果新节点的层数比表中其他节点的层数都要大
// 那么初始化表头节点中未使用的层,并将它们记录到 update 数组中
// 将来也指向新节点
if (level > zsl->level) {
// 初始化未使用层
// T = O(1)
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
// 更新表中节点最大层数
zsl->level = level;
}
// 创建新节点
x = zslCreateNode(level,score,obj);
// 将前面记录的指针指向新节点,并做相应的设置
// T = O(1)
for (i = 0; i < level; i++) {
// 设置新节点的 forward 指针
x->level[i].forward = update[i]->level[i].forward;
// 将沿途记录的各个节点的 forward 指针指向新节点
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
// 计算新节点跨越的节点数量
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// 更新新节点插入之后,沿途节点的 span 值
// 其中的 +1 计算的是新节点
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
// 未接触的节点的 span 值也需要增一,这些节点直接从表头指向新节点
// T = O(1)
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 设置新节点的后退指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
// 跳跃表的节点计数增一
zsl->length++;
return x;
}
/* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank
*
* 内部删除函数,
* 被 zslDelete 、 zslDeleteRangeByScore 和 zslDeleteByRank 等函数调用。
*
* T = O(1)
*/
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
// 更新所有和被删除节点 x 有关的节点的指针,解除它们之间的关系
// T = O(1)
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
// 更新被删除节点 x 的前进和后退指针
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
// 更新跳跃表最大层数(只在被删除节点是跳跃表中最高的节点时才执行)
// T = O(1)
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
// 跳跃表节点计数器减一
zsl->length--;
}
/* Delete an element with matching score/object from the skiplist.
*
* 从跳跃表 zsl 中删除包含给定节点 score 并且带有指定对象 obj 的节点。
*
* T_wrost = O(N^2), T_avg = O(N log N)
*/
int zslDelete(zskiplist *zsl, double score, robj *obj) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
// 遍历跳跃表,查找目标节点,并记录所有沿途节点
// T_wrost = O(N^2), T_avg = O(N log N)
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
// 遍历跳跃表的复杂度为 T_wrost = O(N), T_avg = O(log N)
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
// 比对分值
(x->level[i].forward->score == score &&
// 比对对象,T = O(N)
compareStringObjects(x->level[i].forward->obj,obj) < 0)))
// 沿着前进指针移动
x = x->level[i].forward;
// 记录沿途节点
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object.
*
* 检查找到的元素 x ,只有在它的分值和对象都相同时,才将它删除。
*/
x = x->level[0].forward;
if (x && score == x->score && equalStringObjects(x->obj,obj)) {
// T = O(1)
zslDeleteNode(zsl, x, update);
// T = O(1)
zslFreeNode(x);
return 1;
} else {
return 0; /* not found */
}
return 0; /* not found */
}
小结:
- 跳跃表是zset的底层实现之一
- 每个跳跃表节点的层高都是1~32之间的随机数
- 在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的
- 跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序
5.intset(整数集合)
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;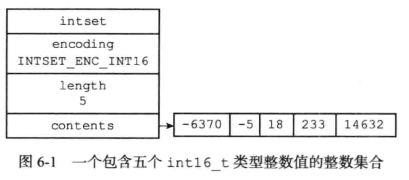
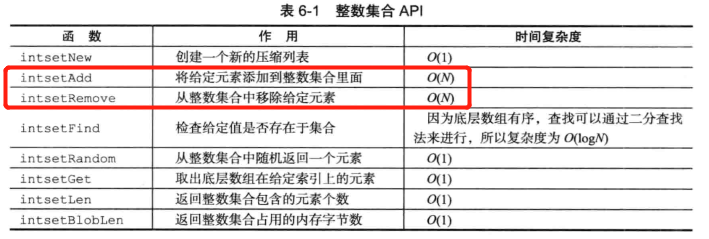
小结:
- 整数集合是集合键的底层实现之一,contents数组按值从小到大排序,并且数组中不包含任何重复项
- 升级操作
- 什么时候升级:当添加新元素到intset中时,新元素的类型比所有现有元素的类型要长时
- 升级步骤:
- 根据新元素的类型,扩展整数集合底层数组的空间大小(在原数组的基础上),并为新元素分配中间
- 将contents数组现有的所有元素转换成与新元素相同的类型,并将类型转换后的元素放在正确的位置上,维持数组的有序性质不变(先放置排名大的)
- 将新元素添加到底层数组(新元素要么大于所有元素(插到末尾),要么小于所有元素(吵到开头))
- 升级的好处:带来的操作上的灵活性,尽可能节约内存
- 整数集合只支持升级操作,不支持降级操作
6.ziplist(压缩列表)
/* The ziplist is a specially encoded dually linked list that is designed
* to be very memory efficient.
*
* Ziplist 是为了尽可能地节约内存而设计的特殊编码双端链表。
*
* It stores both strings and integer values,
* where integers are encoded as actual integers instead of a series of
* characters.
*
* Ziplist 可以储存字符串值和整数值,
* 其中,整数值被保存为实际的整数,而不是字符数组。
*
* It allows push and pop operations on either side of the list
* in O(1) time. However, because every operation requires a reallocation of
* the memory used by the ziplist, the actual complexity is related to the
* amount of memory used by the ziplist.
*
* Ziplist 允许在列表的两端进行 O(1) 复杂度的 push 和 pop 操作。
* 但是,因为这些操作都需要对整个 ziplist 进行内存重分配,
* 所以实际的复杂度和 ziplist 占用的内存大小有关。
*/
/*
* ziplist 属性宏
*/
// 定位到 ziplist 的 bytes 属性,该属性记录了整个 ziplist 所占用的内存字节数
// 用于取出 bytes 属性的现有值,或者为 bytes 属性赋予新值
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 定位到 ziplist 的 offset 属性,该属性记录了到达表尾节点的偏移量
// 用于取出 offset 属性的现有值,或者为 offset 属性赋予新值
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 定位到 ziplist 的 length 属性,该属性记录了 ziplist 包含的节点数量
// 用于取出 length 属性的现有值,或者为 length 属性赋予新值
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// 返回 ziplist 表头的大小
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 返回指向 ziplist 第一个节点(的起始位置)的指针
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 返回指向 ziplist 最后一个节点(的起始位置)的指针
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 返回指向 ziplist 末端 ZIP_END (的起始位置)的指针
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
/*
空白 ziplist 示例图
area |<---- ziplist header ---->|<-- end -->|
size 4 bytes 4 bytes 2 bytes 1 byte
+---------+--------+-------+-----------+
component | zlbytes | zltail | zllen | zlend |
| | | | |
value | 1011 | 1010 | 0 | 1111 1111 |
+---------+--------+-------+-----------+
^
|
ZIPLIST_ENTRY_HEAD
&
address ZIPLIST_ENTRY_TAIL
&
ZIPLIST_ENTRY_END
非空 ziplist 示例图
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+---------+--------+-------+--------+--------+--------+--------+-------+
component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL
*/
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;

小结:
- 压缩列表作为一种节约内存而开发的顺序型数据结构,被用作列表键和哈希键的底层实现
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值
- 添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引发连锁更新操作
- 场景:在一个ziplist中,有多个连续的,长度介于250-253字节的节点e1至eN,因为e1至eN的所有节点的长度都小于254字节,所以记录这些节点长度只需1字节的previous_entry_length属性,即e1至eN的所有节点的previous_entry_length属性都是1字节长的。当插入一个长度大于等于254字节的新节点到list头,e1的previous_entry_length需要扩展至5字节,以保存new节点的长度,因此e1节点的长度也大于254字节,e2的previous_entry_length也需要扩展。。。直到eN节点
- 连锁更新的最坏时间复杂度为$O(N^2)$
- 尽管连锁更新的复杂度较高,但它真正造成性能问题的几率是很低的,push,Insert等操作的平均时间复杂度是$O(N)$
7.对象
typedef struct redisObject {
// 类型
/*
* 位段(bit-field)是以位为单位来定义结构体(或联合体)中的成员变量所占的空间。含有位段的结构体* (联合体)称为位段结构。
*/
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;
/* Object types */
// 对象类型
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
// 对象编码
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds string encoding */type命令:查看数据库键对象类型
object encoding:查看数据库键的值对象编码
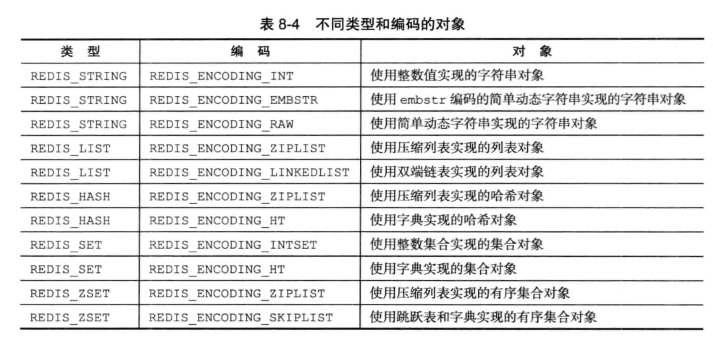
7.1 字符串对象
字符串对象的编码可以是int,raw或者embstr
使用embstr编码的好处:
- embstr编码创建字符串对象所需的内存分配次数从raw编码的两次降为一次
- 释放符串对象所需的内存分配次数从raw编码的两次降为一次
- embstr编码的字符串对象的所有数据都保存在一块连续的内存里面
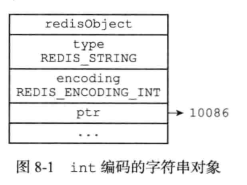
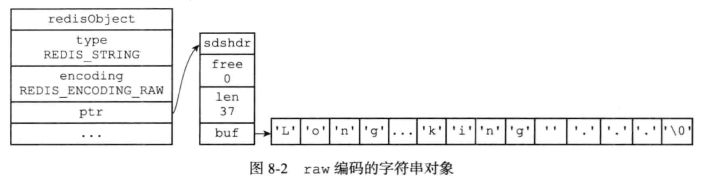

编码转换:
int->raw:使保存的整数值变为字符串值时
embstr->raw:Redis没有为embster编码的字符串编写相应的修改函数,embstr是只读的,当对embstr编码的对象执行修改命令时,程序会先将embstr转换为raw,再修改
7.2 列表对象
列表对象的编码可以是ziplist或者linkedlist
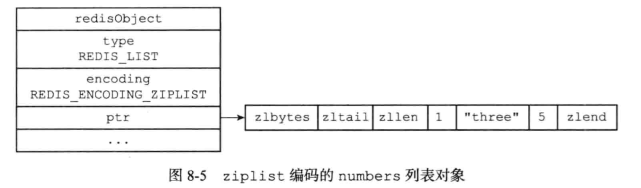
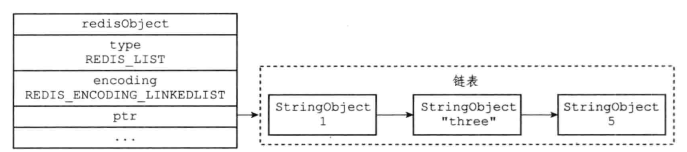
编码转换:
当列表对象可以同时满足一下两个条件时,列表对象使用ziplist编码:
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表对象保存的元素数量小于512个
以上两个条件的上限值是可以修改的,具体可参看配置文件中的list-max-ziplist-value选项和list-max-ziplist-entries选项
7.3 哈希对象
哈希对象的编码可以是ziplist或者hashtable。

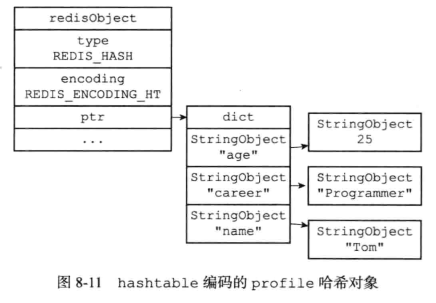
编码转换:
当哈希对象可以同时满足一下两个条件时,哈希对象使用ziplist编码:
- 哈希对象保存的所有字符串元素的长度都小于64字节
- 哈希对象保存的键值对数量小于512个
以上两个条件的上限值是可以修改的,具体可参看配置文件中的hash-max-ziplist-value选项和hash-max-ziplist-entries选项
7.4 集合对象
集合对象的编码可以是intset或者hashtable
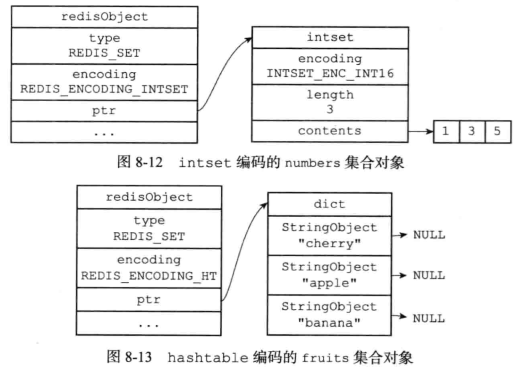
编码转换:
当集合对象可以同时满足一下两个条件时,集合对象使用intset编码:
- 集合对象保存的所有元素都是整数值
- 集合对象保存的元素数量小于512个
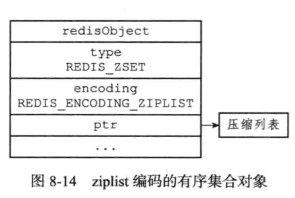
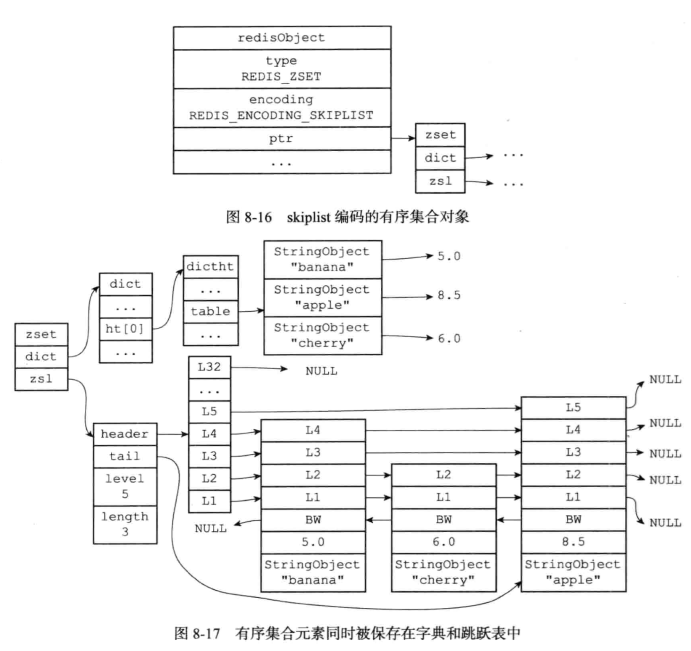
7.5 有序集合对象
有序集合的编码可以是ziplist或者skiplist
/*
* 有序集合
*/
typedef struct zset {
// 字典,键为成员,值为分值
// 用于支持 O(1) 复杂度的按成员取分值操作
dict *dict;
// 跳跃表,按分值排序成员
// 用于支持平均复杂度为 O(log N) 的按分值定位成员操作
// 以及范围操作
zskiplist *zsl;
} zset;

编码转换:
当有序集合对象可以同时满足一下两个条件时,集合对象使用ziplist编码:
- 有序集合对象保存的所有元素成员的长度都小于64字节
- 有序集合对象保存的元素数量小于128个
7.6 类型的检查和多态
Redis用于操作键的命令基本可以分为两种类型。其中一种可以对任何类型的键执行,如$DEL$命令,$EXPIRE$命令,$RENAME$命令,$TYPE$命令,$OBJECT$命令等。另一种智能对特定类型的键造作,如$SET$,$GET$只能对字符串键执行,$HDEL$,$HSET$命令只能对哈希键执行。
7.6.1 类型检查的实现
根据redisObject结构的type属性实现。
7.6.2多态命令的实现
根据redisObject结构的encoding来选择正确的命令代码执行命令。
7.7内存回收
通过redisObject的refcount实现引用计数。
- 当创建一个新对象时,引用计数的值会被初始化为1
- 对象被一个新程序使用时,引用计数加1
- 对象不再一个程序使用时,引用计数减1
- 引用计数为0时,对象所占用的内存被释放
7.8对象共享
对象的引用计数还有对象共享的属性。
在Redis中让多个键对象共享一个值对象的步骤:
- 将数据库键的值指针指向一个现有的值对象
- 将被共享的值对象的引用计数加1
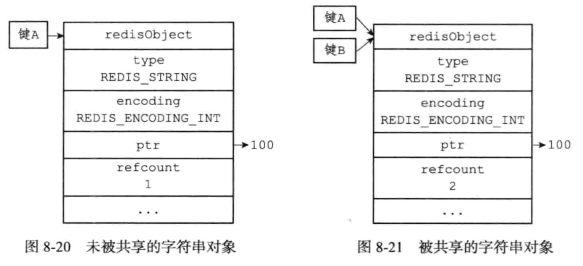
object refcount命令:查看值对象引用计数
redis共享0-9999的字符串对象,创建字符串共享对象的数量可以通过redis.h/REDIS_SHARED_INTEGERS常量修改
为什么Redis不共享包含字符串的对象

7.9对象的空转时长
redisObject结构的lru属性记录了对象最后一次被程序访问的时间
object idletime命令:可以打印给定键的空转时长,是根据当前时间减去lru得出的