版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013517122/article/details/83793296
初次听到 base58 编解码很是不解, 已经存在了 base64 编解码, 为什么还要出现 base58 呢, 因此各处搜集资料, 了解原理, 用途, 终于把它搞定, Mark下, 免得今后忘记找不到了.
1. base 58 编码由来
1. base_58 是用于 Bitcoin 中使用的一种独特的编码方式,主要用于产生Bitcoin的钱包地址
2. 相比 base_64,base_64 不使用数字 "0",字母大写"O",字母大写 "I",和字母小写 "l",以及 "+" 和 "/" 符号
2. base 58 编码表
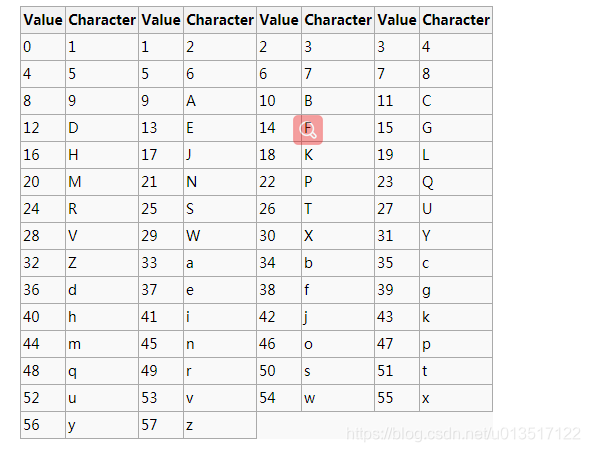
3. base 58 编码实现
//编码表
static const char b58digits_ordered[] = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz";
bool b58enc(char *b58, size_t *b58sz, const void *data, size_t binsz)
{
const uint8_t *bin = data;
int carry;
ssize_t i, j, high, zcount = 0;
uint8_t buf[12 * 1024] = {0};
size_t size;
//计算待编码数据前面 0 的个数
while (zcount < (ssize_t)binsz && !bin[zcount])
++zcount;
//计算存放转换数据所需要的数组的大小 138/100 --> log(256)/log(58)
size = (binsz - zcount) * 138 / 100 + 1;
memset(buf, 0, size);
//遍历待转换数据
for (i = zcount, high = size - 1; i < (ssize_t)binsz; ++i, high = j)
{
//将数据从后往前依次存放
for (carry = bin[i], j = size - 1; (j > high) || carry; --j)
{
carry += 256 * buf[j];
buf[j] = carry % 58;
carry /= 58;
}
}
for (j = 0; j < (ssize_t)size && !buf[j]; ++j);
if (*b58sz <= zcount + size - j)
{
*b58sz = zcount + size - j + 1;
return false;
}
if (zcount)
memset(b58, '1', zcount);
for (i = zcount; j < (ssize_t)size; ++i, ++j)
b58[i] = b58digits_ordered[buf[j]];
b58[i] = '\0';
*b58sz = i + 1;
return true;
}
4. base 58 解码实现
static const int8_t b58digits_map[] = {
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8,-1,-1,-1,-1,-1,-1,
-1, 9,10,11,12,13,14,15,16,-1,17,18,19,20,21,-1,
22,23,24,25,26,27,28,29,30,31,32,-1,-1,-1,-1,-1,
-1,33,34,35,36,37,38,39,40,41,42,43,-1,44,45,46,
47,48,49,50,51,52,53,54,55,56,57,-1,-1,-1,-1,-1,
};
bool b58dec(void *bin, size_t *binszp, const char *b58)
{
size_t binsz = *binszp;
const unsigned char *b58u = (const unsigned char*)b58;
unsigned char *binu = bin;
uint32_t outi[12 * 1024] = {0};
size_t outisz = (binsz + 3) / 4;
uint64_t t;
uint32_t c;
size_t i, j;
uint8_t bytesleft = binsz % 4;
uint32_t zeromask = bytesleft ? (0xffffffff << (bytesleft * 8)) : 0;
unsigned zerocount = 0;
size_t b58sz;
b58sz = strlen(b58);
memset(outi, 0, outisz * sizeof(*outi));
// Leading zeros, just count
for (i = 0; i < b58sz && b58u[i] == '1'; ++i)
++zerocount;
for (; i < b58sz; ++i)
{
if (b58u[i] & 0x80)
// High-bit set on invalid digit
return false;
if (b58digits_map[b58u[i]] == -1)
// Invalid base58 digit
return false;
c = (unsigned)b58digits_map[b58u[i]];
for (j = outisz; j--; )
{
t = ((uint64_t)outi[j]) * 58 + c;
c = (t & 0x3f00000000) >> 32;
outi[j] = t & 0xffffffff;
}
if (c)
// Output number too big (carry to the next int32)
return false;
if (outi[0] & zeromask)
// Output number too big (last int32 filled too far)
return false;
}
j = 0;
switch (bytesleft) {
case 3:
*(binu++) = (outi[0] & 0xff0000) >> 16;
//-fallthrough
case 2:
*(binu++) = (outi[0] & 0xff00) >> 8;
//-fallthrough
case 1:
*(binu++) = (outi[0] & 0xff);
++j;
//-fallthrough
default:
break;
}
for (; j < outisz; ++j)
{
*(binu++) = (outi[j] >> 0x18) & 0xff;
*(binu++) = (outi[j] >> 0x10) & 0xff;
*(binu++) = (outi[j] >> 8) & 0xff;
*(binu++) = (outi[j] >> 0) & 0xff;
}
// Count canonical base58 byte count
binu = bin;
for (i = 0; i < binsz; ++i)
{
if (binu[i]) {
if (zerocount > i) {
/* result too large */
return false;
}
break;
}
--*binszp;
}
*binszp += zerocount;
return true;
}
4. base 58 编码示例
4.1 示例编码
//示例代码片段
void OnBnClickedButtonBase58Encode()
{
CString strData, strTemp, strDisp;
BOOL retCode;
BYTE convertBuf[12 * 1024] = { 0 };
UINT convertBufLen = 0;
//清空显示区内容
m_re_result.SetWindowTextA(_T(""));
//获取要编码的数据
GetDlgItemText(IDC_EDIT_DATA, strData);
if (strData.GetLength() == 0) {
AfxMessageBox(_T("Please input encode data, Then try again"));
return;
}
if (strData.GetLength() % 2 != 0) {
AfxMessageBox(_T("decode data length is must be multiple of 2-Character, Try again after check "));
return;
}
//数据转换
retCode = CstringToByte(strData, g_DataBuf);
if (retCode == FALSE) {
AfxMessageBox(_T("Convert CString to Byte Failed, Try again after check "));
return;
}
ShowMessageString(_T("*********** Start Encoding ***********"), COLOR_BLUE);
convertBufLen = strData.GetLength();
g_DataBufLen = strData.GetLength() / 2;
retCode = b58enc((char *)convertBuf, (size_t *)&convertBufLen, g_DataBuf, (size_t)g_DataBufLen);
if (retCode) {
//显示函数, 用于显示结果
ShowMessageString((char *)convertBuf, COLOR_BLACK);
ShowMessageString(_T("*********** End Encoding ***********"), COLOR_BLUE);
ShowMessageString(_T("编码成功"), COLOR_BLACK);
}
else {
ShowMessageString(_T("编码失败"), COLOR_RED);
}
}
4.2 示例效果
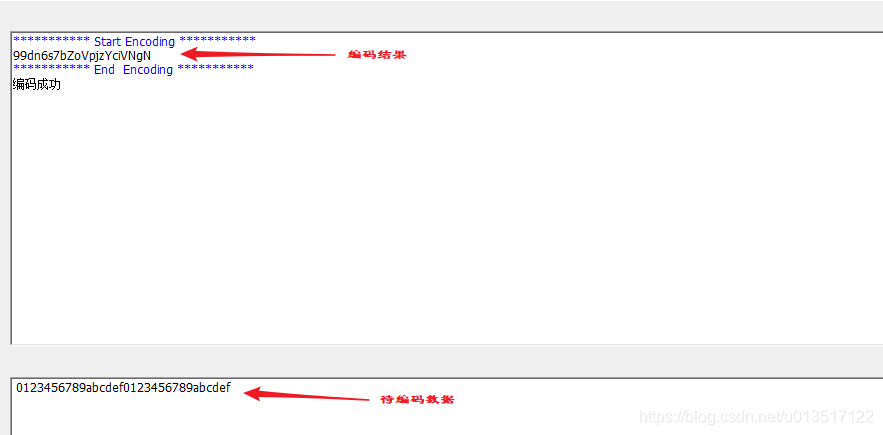
5. base 58 解码示例
5.1 示例解码
//示例代码片段
void OnBnClickedButtonBase58Decode()
{
CString strData, strTemp, strDisp;
BOOL retCode;
BYTE convertBuf[12 * 1024] = { 0 };
UINT convertBufLen = 0;
//清空显示区内容
m_re_result.SetWindowTextA(_T(""));
//获取要编码的数据
GetDlgItemText(IDC_EDIT_DATA, strData);
if (strData.GetLength() == 0) {
AfxMessageBox(_T("Please input decode data, Then try again"));
return;
}
ShowMessageString(_T("*********** Start Decoding ***********"), COLOR_BLUE);
//类型转换
strcpy((char *)g_DataBuf, strData);
retCode = b58dec((char *)convertBuf, (size_t *)&g_DataBufLen, (char *)g_DataBuf);
if (retCode) {
//转换数据, 用于显示
for (int i = 0; i < g_DataBufLen; i++) {
strTemp.Format("%02x", convertBuf[i]);
strDisp += strTemp;
}
//显示函数, 用于显示结果
ShowMessageString(strDisp, COLOR_BLACK);
ShowMessageString(_T("*********** End Decoding ***********"), COLOR_BLUE);
ShowMessageString(_T("解码成功"), COLOR_BLACK);
}
else {
ShowMessageString(_T("解码失败"), COLOR_RED);
}
}
5.2 示例效果

6. base 58 与 base 64 异同
相同:
1. 一般都用于URL, 邮件文本, 可见字符显示.
2. 都会造成信息冗余, 数据量增大, 因此不会用于大数据传输编码.
区别:
1. 编码集不同, base 58 的编码集在 base 64 的字符集的基础上去掉了比较容易混淆的字符.
2. base 64 采用直接切割 bit 的方法(8->6), 而 base 58 采用大数进制转换, 效率更低, 使用场景更少.
Note: base 58 解码时需要将长度传入, 这点与 base 64 有区别, 在代码实现时应注意.
示例 Demo 的源码有以下 3 个路径可以获取:
1. 评论区留下邮箱地址, 我看到后第一时间发送源码.
2. CSDN [https://download.csdn.net/download/u013517122/10768735]
3. github [[email protected]:Huihh/DE_MSG.git]