base64原理及其编解码的python实现
base64
base64简介
base64是一种基于64个可打印字符来表示二进制数据的表示方法。26=64,所以每6bit为一个单元,对应某个可打印字符。3字节有24bit,对应4个base64单元,即3字节任意二进制数据可由4个可打印字符来表示。在base64中,可打印字符包括字母A到Z、a到z和0到9,共62个字符,以及+和/字符。base64常用于只能处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME电子邮件、XML复杂数据等。
base64编码表
常规的base64编码表:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
使用者可以根据需要改变编码表元素或元素顺序实现变表base64编解码
base64编码原理
编码时,3字节的数据先后放入一个24bit的缓冲区中,先来的字节占高位。数据不足3字节时,缓冲区中剩下的bit应用0不足。从高到低,每次取出6bit,按照其十进制的值在编码表中取出相应的字符作为编码后的输出,直到全部输入数据转换完成。
例如,编码“Man”
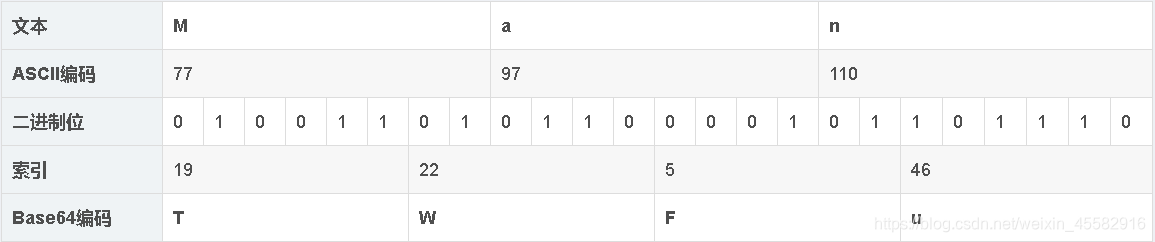
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使要编码的字节数能够被3整除,然后再进行base64的编码。在编码后的base64文本后加上1个或2个等号“=”,代表补足的字节数。也就是说,当最后剩余1个八位字节(1个byte)时,最后1个6位的base64字节块有四位是0值,最后附加上2个等号“=”;当最后剩余2个八位字节(2个byte)时,最后1个6位的base64字节块有两位是0值,最后附加1个等号“=”。
例如,分别编码“A”和“BC”
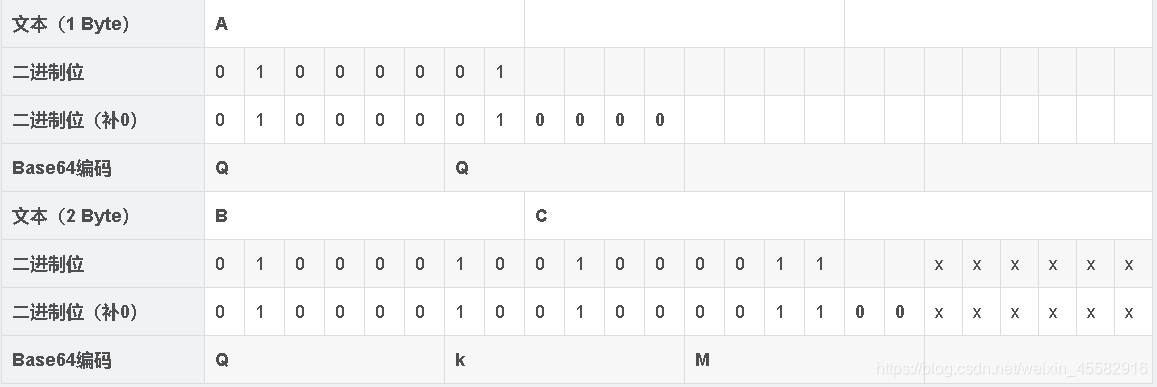
所以,识别base64编码的一种方法是看末尾是否有等号“=”。但是这种识别方法并不是万能的,当编码的字符长度刚好是3的倍数时,编码后的字符串末尾不会出现等号“=”。
base64编解码的python实现
#coding:utf-8
#base="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" 原表
base=[0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47, 0x48, 0x49, 0x4A,
0x4B, 0x4C, 0x4D, 0x4E, 0x4F, 0x50, 0x51, 0x52, 0x53, 0x54,
0x55, 0x56, 0x57, 0x58, 0x59, 0x5A, 0x61, 0x62, 0x63, 0x64,
0x65, 0x66, 0x67, 0x68, 0x69, 0x6A, 0x6B, 0x6C, 0x6D, 0x6E,
0x6F, 0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77, 0x78,
0x79, 0x7A, 0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37,
0x38, 0x39, 0x2B, 0x2F] #原表的ascii码表示,方便进行原表变换
#对原表进行变换,不要变表时,注释掉原表变换的代码即可
#for i in range(0,10):
#base[i],base[19-i]=base[19-i],base[i]
#base_changed是变表,需要转成字符串的形式
base_changed=''.join(chr(i) for i in base)
print("Current Base:\n%s " %base_changed) #打印base_changed变表
def base64_encode(inputs): #inputs是待编码的字符串
# 将字符串转化为2进制
bin_str = []
for i in inputs:
x = str(bin(ord(i))).replace('0b', '')
bin_str.append('{:0>8}'.format(x))
# 输出的字符串
outputs = ""
# 不够三倍数,需补齐的次数
nums = 0
while bin_str:
# 每次取三个字符的二进制
temp_list = bin_str[:3]
if (len(temp_list) != 3):
nums = 3 - len(temp_list)
while len(temp_list) < 3:
temp_list += ['0' * 8]
temp_str = "".join(temp_list)
# 将三个8字节的二进制转换为4个十进制
temp_str_list = []
for i in range(0, 4):
temp_str_list.append(int(temp_str[i * 6:(i + 1) * 6], 2))
if nums:
temp_str_list = temp_str_list[0:4 - nums]
for i in temp_str_list:
outputs += base_changed[i]
bin_str = bin_str[3:]
outputs += nums * '='
print("Encoded String:\n%s " % outputs)
def base64_decode(inputs): #inputs是base64字符串
# 将字符串转化为2进制
bin_str = []
for i in inputs:
if i != '=':
x = str(bin(base_changed.index(i))).replace('0b', '')
bin_str.append('{:0>6}'.format(x))
# 输出的字符串
outputs = ""
nums = inputs.count('=')
while bin_str:
temp_list = bin_str[:4]
temp_str = "".join(temp_list)
# 补足8位字节
if (len(temp_str) % 8 != 0):
temp_str = temp_str[0:-1 * nums * 2]
# 将四个6字节的二进制转换为三个字符
for i in range(0, int(len(temp_str) / 8)):
outputs += chr(int(temp_str[i * 8:(i + 1) * 8], 2))
bin_str = bin_str[4:]
print("Decoded String:\n%s " % outputs)
#plain是待编码的字符串
plain="This_is_a_base64_example"
base64_encode(plain)
#enc是经base64编码的字符串
enc="VGhpc19pc19hX2Jhc2U2NF9leGFtcGxl"
base64_decode(enc)
运行结果

其他base编码
base16
24=16
base16编码表:
0123456789ABCDEF
实际上就是Hex(十六进制)编码
base32
25=32
base32编码表:
ABCDEFGHIJKLMNOPQRSTUVWXYZ234567
base36、base58、 base62、 base85、base91、 base92
请参阅Base系列编码浅析