这两天在为公司的框架添加一个Base64加解密的模块,于是就想分享一下Base64的原理及自己的C++实现,借鉴了poco库。博文中的代码都是这两天写的代码的简洁版,可以完成Base64的编解码,方便易用。
不推荐造轮子,但是轮子在别的车上,你得自己拆下来,然后根据自己车的尺寸DIY你的轮子,安在自己的车上,当然,你还需要了解这个轮子的原理,万一哪天轮子坏了要你来修呢。
Base64简介
Base64是一种字节编码方式,一个字节可表示256个值,那么ASCII中0x20 ~ 0x7E是可打印字符,也就是说只有这么些范围的字符打印出来是可见的。Base64编码就是把字节转化成ASCII码中可打印的字符(Base64编码是从二进制到可见字符的过程)。它是一种任意二进制到文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
Base64应用
- 由于二进制的一些字符在网络协议中属于控制字符,不能直接传送,因此需要用Base64编码之后传输,编码之后传输的是一些很普通的ASCII字符。
- Base64常用于邮件编码,当邮件中有二进制数据时,就要编码转换。
- 图片的编码
- Url中有二进制数据,这个时候需要Base64编码(Web安全的Base64)
- 可以进行简单的加密,Base64的编解码规则是透明的,因此用Base64加密时要加盐。
Base64原理
用一句话来说明Base64编码的原理:“把3个字节变成4个字节”。
这么说吧,3个字节一共24个bit,把这24个bit依次分成4个组,每个组6个bit,再把这6个bit塞到一个字节中去(最高位补两个0就变成8个bit),就会变成4个字节。没了。
因为6个bit最多能表示
,也就是说Base64编码出来的字符种类只有64个,这也是Base64名字的由来。
那我们就要从ASCII中0x20 ~ 0x7E是可打印字符选出64个普通的ASCII字符
下面就是映射表(来自维基百科):
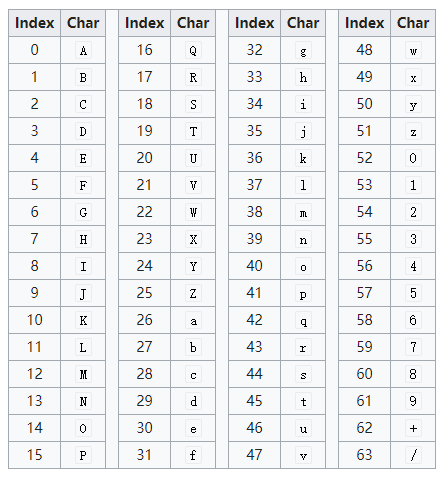
解密的过程就是一个逆的过程,加解密下面有一张我自己绘制的图,看了你就明白了。
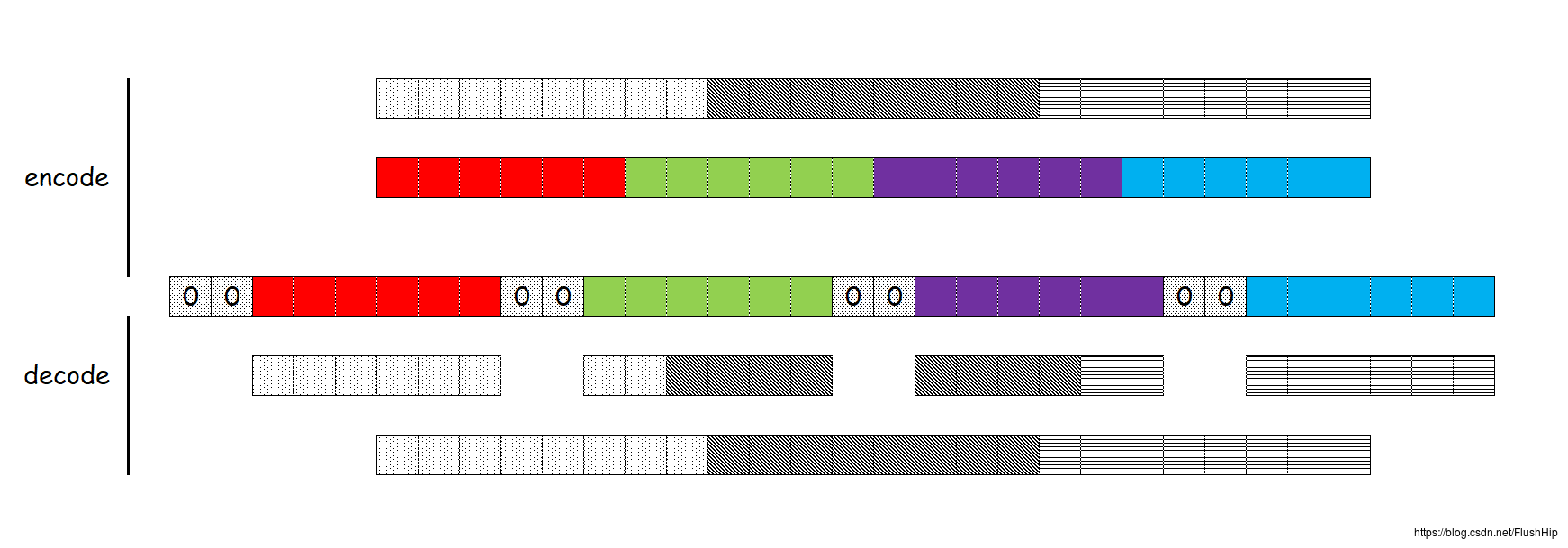
看了这张图片,你会发现貌似只有字节数是3的倍数才能处理啊,那么显示情况中,不是3的倍数的情况多的是,怎么办?补零加=号,看下图:
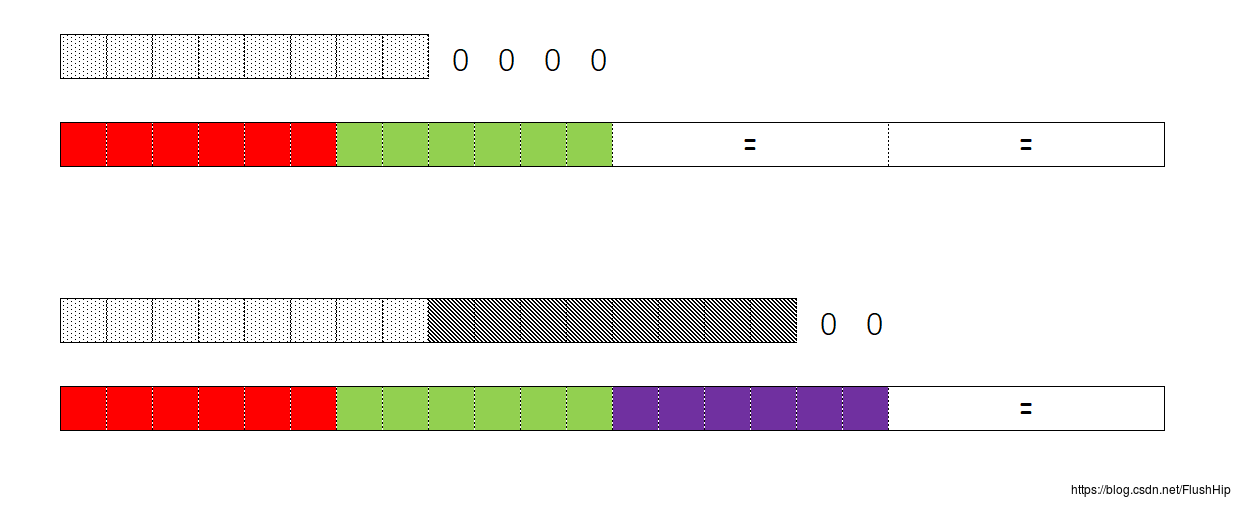
因此Base64编码后有时候可以看到=或者==这都是正常的。
那么解码的密文就有一定的要求的,从前面的分析中得出来,加密之后形成的密文长度一定是4的倍数,且字符串中的字符一定要在映射表中,或者字符为=,还有,只可能有一个=或一个==。
C++编码实现Base64
首先需要做出两张表,一张是编码映射表,一张是解码映射表。
编码表:
const unsigned char Base64EncodeMap[64] =
{
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/'
};打编码表可以使用下面的代码:
for (int i = 0; i < 26; Base64EncodeMap[0 + i] = 'A' + i, ++i) {}
for (int i = 0; i < 26; Base64EncodeMap[26 + i] = 'a' + i, ++i) {}
for (int i = 0; i < 10; Base64EncodeMap[52 + i] = '0' + i, ++i) {}
Base64EncodeMap[62] = '+';
Base64EncodeMap[62] = '/';解码表:
unsigned char Base64DecodeMap[256] =
{
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0x3E, 0xFF, 0xFF, 0xFF, 0x3F,
0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x3A, 0x3B,
0x3C, 0x3D, 0xFF, 0xFF, 0xFF, 0x00, 0xFF, 0xFF,
0xFF, 0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06,
0x07, 0x08, 0x09, 0x0A, 0x0B, 0x0C, 0x0D, 0x0E,
0x0F, 0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16,
0x17, 0x18, 0x19, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0x1A, 0x1B, 0x1C, 0x1D, 0x1E, 0x1F, 0x20,
0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27, 0x28,
0x29, 0x2A, 0x2B, 0x2C, 0x2D, 0x2E, 0x2F, 0x30,
0x31, 0x32, 0x33, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF,
0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF
};打解码表可以使用下面的代码:
for (int i = 0; i < (1 << 8); Base64DecodeMap[i++] = 0xFF) {}
for (int i = 0; i < (1 << 8); Base64DecodeMap[Base64EncodeMap[i]] = i, ++i) {}
Base64DecodeMap['='] = 0;编解码的步骤就是上面两张图,用位运算就可以搞定了。下面是核心代码。
/*Encode*/
// 0 index byte
index = _group[0] >> 2;
_buf.push_back(_encodeMap[index]);
// 1 index byte
index = ((_group[0] & 0x03) << 4) | (_group[1] >> 4);
_buf.push_back(_encodeMap[index]);
// 2 index byte
index = ((_group[1] & 0x0F) << 2) | (_group[2] >> 6);
_buf.push_back(_encodeMap[index]);
// 3 index byte
index = _group[2] & 0x3F;
_buf.push_back(_encodeMap[index]);/*Decode*/
buff[0] = (_decodeMap[_group[0]] << 2) | (_decodeMap[_group[1]] >> 4);
if (_group[2] != '=')
{
buff[1] = ((_decodeMap[_group[1]] & 0x0F) << 4) | (_decodeMap[_group[2]] >> 2);
top = 2;
}
if (_group[3] != '=')
{
buff[2] = (_decodeMap[_group[2]] << 6) | _decodeMap[_group[3]];
top = 3;
}
for (unsigned int i = 0; i < top; ++i)
{
_buf.push_back(buff[i]);
}
然后把编码做成一个类Base64Encrypt,解码也做成一个类Base64Decrypt。
你要考虑到的一点是,编解码有时候不会一次性完成,为什么呢,实际情况中,要编解码的字符串可能很长,你不可能把字符串一次性读到内存中,因此就要分批编解码,但是我们编码是以3个字节为一组进行编码,因此,在类中需要设置一个缓存,长度为3,当缓存满了,就直接把让3个字节去编码。poco库就是这么实现的。
编码出来的结果用vector去存储,但是vector存储又会发生内存的频繁复制(考虑下vector的实现)。怎么办呢?由于Base64的编解码规则是透明的,给你一段字符串,你马上可以计算出加密出来的字符串有多长。这样子就可以使用std::vector::reserve成员函数来为vector预先分配空间。
Base64Encrypt
class Base64Encrypt
{
public:
Base64Encrypt() : _groupLength(0) {}
Base64Encrypt(const void *input, size_t length) : Base64Encrypt()
{
Update(input, length);
}
void Update(const void *input, size_t length)
{
static const size_t LEN = 3;
_buf.reserve(_buf.size() + (length - (LEN - _groupLength) + LEN - 1) / LEN * 4 + 1);
const unsigned char *buff = reinterpret_cast<const unsigned char *>(input);
unsigned int i;
for (i = 0; i < length; ++i)
{
_group[_groupLength++] = buff[i];
if (_groupLength == LEN)
{
Encode();
}
}
}
const unsigned char *CipherText()
{
Final();
return _buf.data();
}
std::string GetString()
{
const char *pstr = (const char *)CipherText();
size_t length = GetSize();
return std::string(pstr, length);
}
void Reset()
{
_buf.clear();
_groupLength = 0;
for (unsigned int i = 0; i < sizeof(_group) / sizeof(_group[0]); ++i)
{
_group[i] = 0;
}
}
size_t GetSize()
{
CipherText();
return _buf.size();
}
private:
Base64Encrypt(const Base64Encrypt &) = delete;
Base64Encrypt & operator = (const Base64Encrypt &) = delete;
void Encode()
{
unsigned char index;
// 0 index byte
index = _group[0] >> 2;
_buf.push_back(Base64EncodeMap[index]);
// 1 index byte
index = ((_group[0] & 0x03) << 4) | (_group[1] >> 4);
_buf.push_back(Base64EncodeMap[index]);
// 2 index byte
index = ((_group[1] & 0x0F) << 2) | (_group[2] >> 6);
_buf.push_back(Base64EncodeMap[index]);
// 3 index byte
index = _group[2] & 0x3F;
_buf.push_back(Base64EncodeMap[index]);
_groupLength = 0;
}
void Final()
{
unsigned char index;
if (_groupLength == 1)
{
_group[1] = 0;
// 0 index byte
index = _group[0] >> 2;
_buf.push_back(Base64EncodeMap[index]);
// 1 index byte
index = ((_group[0] & 0x03) << 4) | (_group[1] >> 4);
_buf.push_back(Base64EncodeMap[index]);
// 2 index byte
_buf.push_back('=');
// 3 index byte
_buf.push_back('=');
}
else if (_groupLength == 2)
{
_group[2] = 0;
// 0 index byte
index = _group[0] >> 2;
_buf.push_back(Base64EncodeMap[index]);
// 1 index byte
index = ((_group[0] & 0x03) << 4) | (_group[1] >> 4);
_buf.push_back(Base64EncodeMap[index]);
// 2 index byte
index = ((_group[1] & 0x0F) << 2) | (_group[2] >> 6);
_buf.push_back(Base64EncodeMap[index]);
// 3 index byte
_buf.push_back('=');
}
_groupLength = 0;
}
private:
std::vector<unsigned char> _buf;
unsigned char _group[3];
int _groupLength;
static const unsigned char Base64EncodeMap[64];
};注意_buf.reserve(_buf.size() + (length - (LEN - _groupLength) + LEN - 1) / LEN * 4 + 1);这行代码,好好体会下。
Base64Decrypt
class Base64Decrypt
{
public:
Base64Decrypt() : _groupLength(0) {}
Base64Decrypt(const void *input, size_t length) : Base64Decrypt()
{
Update(input, length);
}
void Update(const void *input, size_t length)
{
static const size_t LEN = 4;
_buf.reserve(_buf.size() + (length + (LEN - _groupLength) + LEN - 1) / LEN * 3 + 1);
const unsigned char *buff = reinterpret_cast<const unsigned char *>(input);
unsigned int i;
for (i = 0; i < length; ++i)
{
if (Base64DecodeMap[buff[i]] == 0xFF)
{
throw std::invalid_argument("ciphertext is illegal");
}
_group[_groupLength++] = buff[i];
if (_groupLength == LEN)
{
Decode();
}
}
}
const unsigned char *PlainText()
{
if (_groupLength)
{
throw std::invalid_argument("ciphertext's length must be a multiple of 4");
}
return _buf.data();
}
void Reset()
{
_buf.clear();
_groupLength = 0;
for (unsigned int i = 0; i < sizeof(_group) / sizeof(_group[0]); ++i)
{
_group[i] = 0;
}
}
size_t GetSize()
{
PlainText();
return _buf.size();
}
private:
Base64Decrypt(const Base64Decrypt &) = delete;
Base64Decrypt & operator = (const Base64Decrypt &) = delete;
void Decode()
{
unsigned char buff[3];
unsigned int top = 1;
if (_group[0] == '=' || _group[1] == '=')
{
throw std::invalid_argument("ciphertext is illegal");
}
buff[0] = (Base64DecodeMap[_group[0]] << 2) | (Base64DecodeMap[_group[1]] >> 4);
if (_group[2] != '=')
{
buff[1] = ((Base64DecodeMap[_group[1]] & 0x0F) << 4) | (Base64DecodeMap[_group[2]] >> 2);
top = 2;
}
if (_group[3] != '=')
{
buff[2] = (Base64DecodeMap[_group[2]] << 6) | Base64DecodeMap[_group[3]];
top = 3;
}
for (unsigned int i = 0; i < top; ++i)
{
_buf.push_back(buff[i]);
}
_groupLength = 0;
}
private:
std::vector<unsigned char> _buf;
unsigned char _group[4];
int _groupLength;
static unsigned char Base64DecodeMap[256];
};使用Base64Decrypt需要用try-catch代码块包裹起来,因为对密文进行解码,密文可能不合法,这个时候Base64Decrypt类只能通过抛出std::invalid_argument异常来告诉用户。
Web安全版Base64
Web安全版Base64其实和标准版一样,只不过映射表中的+对应-, /对应_,所有代码只要根据这两个地方具体改动,就可以完成Web安全版的Base64,Web安全版Base64也叫SafeUrlBase64。
测试
怎么知道你写的Base64是正确的,这需要测试,我们需要知道一段字符串通过Base64加密出来正确的密文,这个可以通过在线的Base64编解码网站实现,不过,更推荐Python中的base64模块,其中的base64.b64encode方法编码,base64.urlsafe_b64encode可以进行Web安全的Base64编码,有了正确的密文,进行比较;之后可以把这些正确的密文解码回来,看看是不是等于之前的字符串。
参考: