答:引用来源: 百度文库《完全理解Java中生产者和消费者模型》http://wenku.baidu.com/view/cfdf0f89cc22bcd126ff0c3e.html
在平时的编程中,经常遇到一个线程要产生数据,而另一个线程要处理产生出来的数据,这其实就是生产者和消费者的关系。生产者在产生数据后可以直接调用消费者处理数据;也可以把数据放在一个缓冲区中,让消费者从缓冲区中取出数据处理,两种方式从调用方式上来说,第一种可是说是同步的,即生产者在生产出数据后要等待消费者消耗掉后才能生产下一个数据,等待时间的长短取决于消费者处理数据的能力;第二种方式是异步的,生产者只管生产数据,然后扔到一个缓冲区内,不管数据是否被立即处理了,消费者则从缓冲区中依次取出数据进行自己节奏的处理。从线程模型角度来说,第一种是单线程的,而第二种则是多线程的。多线程必须要考虑的一个问题是线程之间的协作,协作即协调合作,不要乱套,以生产者和消费者模型而言,就是当缓冲区里没有数据时消费者要等待,等待生产者生产数据,当缓冲区满的时候生产者要等待,等待消费者消耗掉一些数据空出位置好存放数据。
java中为了实现多线程之间的协助,需要用到几个特性:wait(),notify(),notifyAll(),synchronized,synchronized相当于操作系统里的临界区或者锁的概念,所谓临界区就是说一次只能有一个线程进去,其他想进入的线程必须等待,加了synchronized锁后,才能调用wait(),notify()和notifyAll()操作,wait方法被调用后,当前线程A(举例)进入被加锁对象的线程休息室,然后释放锁,等待被唤醒。释放的锁谁来获取?当然是由先前等待的另一个线程B得到,B在获得锁后,进行某种操作后通过notify或者notifyAll把A从线程休息室唤醒,然后释放锁,A被唤醒后,重新获取锁定,进行下一语句的执行。
再回到生产者和消费者模型,如果引入了缓冲区的话就需要处理生产者线程和消费者线程之间的协作,缓冲区可以有这几种,队列缓冲区,比如队列或者栈,队列缓冲区的特点是其长度是动态增长的,这就意味着内存的动态分配带来的性能开销,同时队列缓冲区还会产生因为多线程之间的同步和互斥带来的开销。环形缓冲区可以解决内存分配带来开销的问题,因为环形缓冲区长度是固定的。但是环形缓冲区还是无法解决同步互斥带来的多线程切换的开销,如果生产者和消费者都不止一个线程,带来的开销更大,终极解决办法是引入双缓冲区,何为双缓冲区?双缓冲区顾名思义是有两个长度固定的缓冲区A B,生产者和消费者只使用其中一个,当两个缓冲区都操作完成后完成一次切换,开始时生产者开始向A里写数据,消费者从B里读取数据,当A写满同时B也读完后,切换一下,这时消费者从A里取数据,生产者向B写数据,由于生产者和消费者不会同时操作同一个缓冲区,所以不会发生冲突。
生产者和消费者模型不止是用在多线程之间,不同进程之间也可以有。线程和进程到底有什么区别?这是很多程序员搞不清的问题,其实很简单,进程有自己的地址空间和上下文,线程是在一个进程上并发执行的代码段。其实在win32系统中进程只是占用一定长度的地址空间,进程中总是有一个主线程来运行。消费者和生产者模型应用于进程间通信的典型例子是分布式消息处理,消息的消费者进程需要一个缓冲区缓冲收到的消息,消息的生产者进程也需要一个缓冲区缓冲将要发送的消息,这样可以一定程度上减少因为网络断开引起的消息丢失。
对于此模型,应该明确一下几点:
1,生产者仅仅在仓储未满时生产,仓满则停止生产。
2, 消费 者仅仅在仓储有产品时才能消费,仓空则等待。
3, 当消费者发现仓储没有产品的时候会通知生产者生产。
4, 生产者在生产出可消费产品的时候,应该通知等待的消费者去消费。 以下是它的具体实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
public
class
ProducerConsumer {
public
static
void
main(String []args) {
SyncStack ss=
new
SyncStack();
Producer p=
new
Producer(ss);
Consumer c=
new
Consumer(ss);
new
Thread(p).start();
new
Thread(c).start();
}
}
class
WoTou {
int
id;
WoTou(
int
id) {
this
.id=id;
}
public
String toString() {
return
"WoTou : "
+id;
}
}
class
SyncStack {
int
index=
0
;
WoTou[] arrWT=
new
WoTou[
6
];
public
synchronized
void
push(WoTou wt) {
while
(index==arrWT.length) {
try
{
this
.wait();
}
catch
(InterruptedException e) {
e.printStackTrace();
}
}
this
.notify();
arrWT[index]=wt;
index++;
}
public
synchronized
WoTou pop() {
while
(index==
0
) {
try
{
this
.wait();
}
catch
(InterruptedException e) {
e.printStackTrace();
}
}
this
.notify();
index--;
return
arrWT[index];
}
}
class
Producer
implements
Runnable {
SyncStack ss=
null
;
Producer(SyncStack ss) {
this
.ss=ss;
}
public
void
run() {
for
(
int
i=
0
;i<
20
;i++) {
WoTou wt=
new
WoTou(i);
ss.push(wt);
System.out.println(
"生产了:"
+wt);
try
{
Thread.sleep((
int
)(Math.random()*
2
));
}
catch
(InterruptedException e) {
e.printStackTrace();
}
}
}
}
class
Consumer
implements
Runnable {
SyncStack ss=
null
;
Consumer(SyncStack ss) {
this
.ss=ss;
}
public
void
run() {
for
(
int
i=
0
;i<
20
;i++) {
WoTou wt=ss.pop();
System.out.println(
"消费了:"
+wt);
try
{
Thread.sleep((
int
)(Math.random()*
1000
));
}
catch
(InterruptedException e) {
e.printStackTrace();
}
}
}
}
|
附:1程序、进程和线程
程序,就是一段静态的可执行的代码。 进程,就是程序的一次动态的执行过程。
线程,是程序 从头到尾的执行路线,也称为轻量级的进程。一个进程在执行过程中,可以产生多个线程,形成多个执行路线。但线程间是彼此相互独立的。各个线程可以共享相同的内存空间,并利用共享内存来完成数据交换、实时通信和一些同步的工作。而进程都占有不同的内存空间。
单线程是指一个 程序只有一条从开始到结束的顺序的执行路线。 多线程是多个彼此独立的线程,多条执行路线。
2.wait()、notify()可以在任何位置调用,suspend()、resume()只能在synchronized()方法或代码块中调用。 3线程同步
当多个用户线程在并发运行中,可能会因为同时访问一些内容而产生错误问题。例如,同一时刻,一个线程在读取数据,另外一个线程在处理数据,当处理数据的线程没有等到读取数据的线程读取完毕就去处理数据,必然得到错误的结果。
二、Java参数传递和引用传递的区别?
答:引用来源: 《java中的值传递和引用传递》,http://blog.csdn.net/wyzsc/article/details/6341107
Java中没有指针,所以也没有引用传递了,仅仅有值传递 不过可以通过对象的方式来实现引用传递 类似java没有多继承 但可以用多次implements 接口实现多继承的功能
值传递:方法调用时,实际参数把它的值传递给对应的形式参数,方法执行中形式参数值的改变不影响实际参
数的值。
引用传递:也称为传地址。方法调用时,实际参数的引用(地址,而不是参数的值)被传递给方法中相对应的形式参数,在方法执行中,对形式参数的操作实际上就是对实际参数的操作,方法执行中形式参数值的改变将会影响实际参数的值。
Java参数按值传递
面试题:当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
答:是值传递。Java 编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是该对象的引用一个副本。指向同一个对象,对象的内容可以在被调用的方法中改变,但对象的引用(不是引用的副本)是永远不会改变的。
-------------------------------------------------------------
在 Java 应用程序中永远不会传递对象,而只传递对象引用。因此是按引用传递对象。但重要的是要区分参数是如何传递的,这才是该节选的意图。Java 应用程序按引用传递对象这一事实并不意味着 Java 应用程序按引用传递参数。参数可以是对象引用,而 Java 应用程序是按值传递对象引用的。
Java 应用程序中的变量可以为以下两种类型之一:引用类型或基本类型。当作为参数传递给一个方法时,处理这两种类型的方式是相同的。两种类型都是按值传递的;没有一种按引用传递。
按 值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本。因此,如果函数修改了该参数,仅改变副本,而原始值保持不变。按引用传递意味 着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本。因此,如果函数修改了该参数的值,调用代码中的原始值也随之改变。如果 函数修改了该参数的地址,调用代码中的原始值不会改变.
当传递给函数的参数不是引用时,传递的都是该值的一个副本(按值传递)。区别在于引用。在 C++ 中当传递给函数的参数是引用时,您传递的就是这个引用,或者内存地址(按引用传递)。在 Java 应用程序中,当对象引用是传递给方法的一个参数时,您传递的是该引用的一个副本(按值传递),而不是引用本身。
Java 应用程序按值传递参数(引用类型或基本类型),其实都是传递他们的一份拷贝.而不是数据本身.(不是像 C++ 中那样对原始值进行操作。)
例1:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
//在函数中传递基本数据类型,
public
class
Test {
public
static
void
change(
int
i,
int
j) {
int
temp = i;
i = j;
j = temp;
}
public
static
void
main(String[] args) {
int
a =
3
;
int
b =
4
;
change(a, b);
System.out.println(
"a="
+ a);
System.out.println(
"b="
+ b);
}
}
结果为:
a=
3
b=
4
原因就是 参数中传递的是 基本类型 a 和 b 的拷贝,在函数中交换的也是那份拷贝的值,
而不是数据本身;
|
例2:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//传的是引用数据类型
public
class
Test {
public
static
void
change(
int
[] counts) {
counts[
0
] =
6
;
System.out.println(counts[
0
]);
}
public
static
void
main(String[] args) {
int
[] count = {
1
,
2
,
3
,
4
,
5
};
change(count);
}
}
在方法中 传递引用数据类型
int
数组,实际上传递的是其引用count的拷贝,他们都指向数组对象,
在方法中可以改变数组对象的内容。即:对复制的引用所调用的方法更改的是同一个对象。
|
例3:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
//对象的引用(不是引用的副本)是永远不会改变的
class
A {
int
i =
0
;
}
public
class
Test {
public
static
void
add(A a) {
a =
new
A();
a.i++;
}
public
static
void
main(String args[]) {
A a =
new
A();
add(a);
System.out.println(a.i);
}
}
输出结果是
0
在该程序中,对象的引用指向的是A ,而在change方法中,传递的引用的一份副本则指向了一个新的
OBJECT,并对其进行操作。而原来的A对象并没有发生任何变化。 引用指向的是还是原来的A对象。
|
例4:
String 不改变,数组改变
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public
class
Example {
String str =
new
String(
"good"
);
char
[] ch = {
'a'
,
'b'
,
'c'
};
public
static
void
main(String args[]) {
Example ex =
new
Example();
ex.change(ex.str, ex.ch);
System.out.print(ex.str +
" and "
);
System.out.println(ex.ch);
}
public
void
change(String str,
char
ch[]) {
str =
"test ok"
;
ch[
0
] =
'g'
;
}
}
程序
3
输出的是 good and gbc.
String 比较特别,看过String 代码的都知道, String 是
final
的。所以值是不变的。
函数中String对象引用的副本指向了另外一个新String对象,而数组对象引用的副本没有改变,
而是改变对象中数据的内容.对于对象类型,也就是Object的子类,如果你在方法中修改了它的
成员的值,那个修改是生效的,方法调用结束后,它的成员是新的值,但是如果你把它指向一个
其它的对象,方法调用结束后,原来对它的引用并没用指向新的对象。
|
Java参数,不管是原始类型还是引用类型,传递的都是副本(有另外一种说法是传值,但是说传副本更好理解吧,传值通常是相对传址而言)。
如果参数类型是原始类型,那么传过来的就是这个参数的一个副本,也就是这个原始参数的值,这个跟之前所谈的传值是一样的。如果在函数中改变了副本的 值不会改变原始的值.
如果参数类型是引用类型,那么传过来的就是这个引用参数的副本,这个副本存放的是参数的地址。如果在函数中没有改变这个副本的地址,而是改变了地址中的 值,那么在函数内的改变会影响到传入的参数。如果在函数中改变了副本的地址,如new一个,那么副本就指向了一个新的地址,此时传入的参数还是指向原来的 地址,所以不会改变参数的值。
( 对象包括对象引用即地址和对象的内容)
a.传递值的数据类型:八种基本数据类型和String(这样理解可以,但是事实上String也是传递的地址,只是string对象和其他对 象是不同的,string对象是不能被改变的,内容改变就会产生新对象。那么StringBuffer就可以了,但只是改变其内容。不能改变外部变量所指 向的内存地址)。
b.传递地址值的数据类型:除String以外的所有复合数据类型,包括数组、类和接口
下面举例说明:
在 Java 应用程序中永远不会传递对象,而只传递对象引用。因此是按引用传递对象。但重要的是要区分参数是如何传递的,这才是该节选的意图。 Java 应用程序按引用传递对象这一事实并不意味着 Java 应用程序按引用传递参数。参数可以是对象引用,而 Java 应用程序是按值传递对象引用的。
Java 应用程序中的变量可以为以下两种类型之一:引用类型或基本类型。当作为参数传递给一个方法时,处理这两种类型的方式是相同的。两种类型都是按值传递的;没有一种按引用传递。
按 值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本。因此,如果函数修改了该参数,仅改变副本,而原始值保持不变。按引用传递意味 着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本。因此,如果函数修改了该参数,调用代码中的原始值也随之改变。
当传递给函数的参数不是引用时,传递的都是该值的一个副本(按值传递)。区别在于引用。在 C++ 中当传递给函数的参数是引用时,您传递的就是这个引用,或者内存地址(按引用传递)。在 Java 应用程序中,当对象引用是传递给方法的一个参数时,您传递的是该引用的一个副本(按值传递),而不是引用本身。
Java 应用程序按值传递所有参数,这样就制作所有参数的副本,而不管它们的类型。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
class
Test
{
public
static
void
main(String args[])
{
int
val;
StringBuffer sb1, sb2;
val =
10
;
sb1 =
new
StringBuffer (
"apples"
);
sb2 =
new
StringBuffer (
"pears"
);
System .out.println(
"val is "
+ val);
System .out.println(
"sb1 is "
+ sb1);
System .out.println(
"sb2 is "
+ sb2);
System .out.println(
""
);
System .out.println(
"calling modify"
);
// 按值传递所有参数
modify(val, sb1, sb2);
System .out.println(
"returned from modify"
);
System .out.println(
""
);
System .out.println(
"val is "
+ val);
System .out.println(
"sb1 is "
+ sb1);
System .out.println(
"sb2 is "
+ sb2);
}
public
static
void
modify(
int
a, StringBuffer r1,
StringBuffer r2)
{
System .out.println(
"in modify..."
);
a =
0
;
r1 =
null
;
//1
r2.append(
" taste good"
);
System .out.println(
"a is "
+ a);
System .out.println(
"r1 is "
+ r1);
System .out.println(
"r2 is "
+ r2);
}
}
|
Java 应用程序的输出
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
val is
10
sb1 is apples
sb2 is pears
calling modify
in modify...
a is
0
r1 is
null
r2 is pears taste good
returned from modify
val is
10
sb1 is apples
sb2 is pears taste good
|
这段代码声明了三个变量:一个整型变量和两个对象引用。设置了每个变量的初始值并将它们打印出来。然后将所有三个变量作为参数传递给 modify 方法。
modify 方法更改了所有三个参数的值:
将第一个参数(整数)设置为 0 。
将第一个对象引用 r1 设置为 null 。
保留第二个引用 r2 的值,但通过调用 append 方法更改它所引用的对象(这与前面的 C++ 示例中对指针 p 的处理类似)。
当执行返回到 main 时,再次打印出这三个参数的值。正如预期的那样,整型的 val 没有改变。对象引用 sb1 也没有改变。如果 sb1 是按引用传递的,正如许多人声称的那样,它将为 null 。但是,因为 Java 编程语言按值传递所有参数,所以是将 sb1 的引用的一个副本传递给了 modify 方法。当 modify 方法在 //1 位置将 r1 设置为 null 时,它只是对 sb1 的引用的一个副本进行了该操作,而不是像 C++ 中那样对原始值进行操作。
另外请注意,第二个对象引用 sb2 打印出的是在 modify 方法中设置的新字符串。即使 modify 中的变量 r2 只是引用 sb2 的一个副本,但它们指向同一个对象。因此,对复制的引用所调用的方法更改的是同一个对象。
传值---传递基本数据类型参数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public
class
PassValue{
static
void
exchange(
int
a,
int
b){
//静态方法,交换a,b的值
int
temp;
temp = a;
a = b;
b = temp;
}
public
static
void
main(String[] args){
int
i =
10
;
int
j =
100
;
System.out.println(
"before call: "
+
"i="
+ i +
"/t"
+
"j = "
+ j);
//调用前
exchange(i, j);
//值传递,main方法只能调用静态方法
System.out.println(
"after call: "
+
"i="
+ i +
"/t"
+
"j = "
+ j);
//调用后
}
}
|
运行结果:
|
1
2
|
before call: i =
10
j =
100
after call: i =
10
j =
100
|
说明:调用exchange(i, j)时,实际参数i,j分别把值传递给相应的形式参数a,b,在执行方法exchange()时,形式参数a,b的值的改变不影响实际参数i和j的值,i和j的值在调用前后并没改变。
引用传递---对象作为参数
如果在方法中把对象(或数组)作为参数,方法调用时,参数传递的是对象的引用(地址),即在方法调用时,实际参数把对对象的 引用(地址)传递给形式参数。这是实际参数与形式参数指向同一个地址,即同一个对象(数组),方法执行时,对形式参数的改变实际上就是对实际参数的改变, 这个结果在调用结束后被保留了下来。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class
Book{
String name;
private
folat price;
Book(String n,
float
){
//构造方法
name = n;
price = p;
}
static
void
change(Book a_book, String n,
float
p){
//静态方法,对象作为参数
a_book.name = n;
a_book.price = p;
}
public
void
output(){
//实例方法,输出对象信息
System.out.println(
"name: "
+ name +
"/t"
+
"price: "
+ price);
}
}
public
class
PassAddr{
public
static
void
main(String [] args){
Book b =
new
Book(
"java2"
,
32
.5f);
System.out.print(
"before call:/t"
);
//调用前
b.output();
b.change(b,
"c++"
,
45
.5f);
//引用传递,传递对象b的引用,修改对象b的值
System.out.print(
"after call:/t"
);
//调用后
b.output();
}
}
|
运行结果:
|
1
2
|
before call: name:java2 price:
32.5
after call: name:c++ price:
45.5
|
说明:调用change(b,"c++",45.5f)时,对象b作为实际参数,把引用传递给相应的形式参数a_book,实际上a_book也指向同一 个对象,即该对象有两个引用名:b和a_book。在执行方法change()时,对形式参数a_book操作就是对实际参数b的操作。
三、什么是数据库事务,解释数据库锁及其特性。
答:引用来源: 《数据库中的事务和锁》,http://blog.csdn.net/zztfj/article/details/7879613
一、事务的ACID特性
1、A (Atomicity) 原子性
事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。
2、C (Consistency)一致性
事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构(如 B树索引或双向链表)都必须是正确的。
3、I (Isolation) 隔离性
并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务识别数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是第二个事务修改它之后的状态,事务不会识别中间状态的数据。
4、D (Durability) 持久性
事务完成之后,它对于系统的影响是永久性的。该修改即使出现系统故障也将一直保持。
二、完整的事务
BEGIN a transaction: 设置事务的起始点
COMMIT a transaction: 提交事务,使事务提交的数据成为持久,不可更改的部分.
ROLLBACK a transaction:撤消一个事务,使之成为事务开始前的状态.
SAVE a transaction:建立一个标签,做为部分回滚时使用,使之恢复到标签初的状态.
事务的语法:
BEGIN TRAN[SACTION] [<transaction name>|<@transaction variable>][WITH MARK [’<description>’]][;]
COMMIT [TRAN[SACTION] [<transaction name>|<@transaction variable>]][;]
ROLLBACK TRAN[SACTION] [<transaction name>|<save point name>|<@transaction variable>|<@savepoint variable>][;]
SAVE TRAN[SACTION] [<save point name>| <@savepoint variable>][;]
事务完整的例子:
|
1
|
<span style=
"color: rgb(0, 0, 0);"
>USE AdventureWorks2008;
-- We’re making our own table - what DB doesn’t matter<br>-- Create table to work with<br>CREATE TABLE MyTranTest<br>(<br>OrderID INT PRIMARY KEY IDENTITY<br>);<br>-- Start the transaction<br>BEGIN TRAN TranStart;<br>-- Insert our first piece of data using default values.<br>-- Consider this record No1. It is also the 1st record that stays<br>-- after all the rollbacks are done.<br>INSERT INTO MyTranTest<br>DEFAULT VALUES;<br>-- Create a "Bookmark" to come back to later if need be<br>SAVE TRAN FirstPoint;<br>-- Insert some more default data (this one will disappear<br>-- after the rollback).<br>-- Consider this record No2.<br>INSERT INTO MyTranTest<br>DEFAULT VALUES;<br>-- Roll back to the first savepoint. Anything up to that<br>-- point will still be part of the transaction. Anything<br>-- beyond is now toast.<br>ROLLBACK TRAN FirstPoint;<br>INSERT INTO MyTranTest<br>DEFAULT VALUES;<br>-- Commit the transaction<br>COMMIT TRAN TranStart;<br>-- See what records were finally committed.<br>SELECT TOP 2 OrderID<br>FROM MyTranTest<br>ORDER BY OrderID DESC;<br>-- Clean up after ourselves<br>DROP TABLE MyTranTest;<br></span>
|
三、锁
锁定是 Microsoft SQL Server数据库引擎用来同步多个用户同时对同一个数据块的访问的一种机制。
在事务获取数据块当前状态的依赖关系(比如通过读取或修改数据)之前,它必须保护自己不受其他事务对同一数据进行修改的影响。事务通过请求锁定数据块来达到此目的。锁有多种模式,如共享或独占。锁模式定义了事务对数据所拥有的依赖关系级别。如果某个事务已获得特定数据的锁,则其他事务不能获得会与该锁模式发生冲突的锁。如果事务请求的锁模式与已授予同一数据的锁发生冲突,则数据库引擎实例将暂停事务请求直到第一个锁释放。
四大冲突问题
1、脏读
某个事务读取的数据是另一个事务正在处理的数据。而另一个事务可能会回滚,造成第一个事务读取的数据是错误的。
2、不可重复读
在一个事务里两次读入数据,但另一个事务已经更改了第一个事务涉及到的数据,造成第一个事务读入旧数据。
3、幻读
幻读是指当事务不是独立执行时发生的一种现象。例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
4、更新丢失
多个事务同时读取某一数据,一个事务成功处理好了数据,被另一个事务写回原值,造成第一个事务更新丢失。
锁模式:
1、共享锁
共享锁(S 锁)允许并发事务在封闭式并发控制下读取 (SELECT)资源。有关详细信息,请参阅并发控制的类型。资源上存在共享锁(S锁)时,任何其他事务都不能修改数据。读取操作一完成,就立即释放资源上的共享锁(S锁),除非将事务隔离级别设置为可重复读或更高级别,或者在事务持续时间内用锁定提示保留共享锁(S锁)。
2、更新锁(U锁)
更新锁在共享锁和排他锁的杂交。更新锁意味着在做一个更新时,一个共享锁在扫描完成符合条件的数据后可能会转化成排他锁。
这里面有两个步骤:
1) 扫描获取Where条件时。这部分是一个更新查询,此时是一个更新锁。
2) 如果将执行写入更新。此时该锁升级到排他锁。否则,该锁转变成共享锁。
更新锁可以防止常见的死锁。
3、排他锁
排他锁(X 锁)可以防止并发事务对资源进行访问。排他锁不与其他任何锁兼容。使用排他锁(X锁)时,任何其他事务都无法修改数据;仅在使用 NOLOCK提示或未提交读隔离级别时才会进行读取操作。
事务隔离级别
SQL Server通过SET TRANSACTION ISOLATION LEVEL语句设置事务隔离级别:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}
[ ; ]
Read Committed是SQL Server和Oracle的预设隔离等级。
1、READ UNCOMMITTED
Read UnCommitted事务可以读取事务已修改,但未提交的的记录。
Read UnCommitted事务会产生脏读(Dirty Read)。
Read UnCommitted事务与select语句加nolock的效果一样,它是所有隔离级别中限制最少的。
2、READ COMMITTED
一旦创建共享锁的语句执行完成,该锁顶便释放。
Read Committed是SQL Server的预设隔离等级。
Read Committed只可以防止脏读。
|
1
|
<span style=
"color: rgb(0, 0, 0);"
>
--先创建表: <br>CREATE TABLE tb(id int,val int) <br>INSERT tb VALUES(1,10) <br>INSERT tb VALUES(2,20) <br> <br>然后在连接1中,执行: <br>SET TRANSACTION ISOLATION LEVEL READ COMMITTED<br>BEGIN TRANSACTION<br> SELECT * FROM tb; --这个SELECT结束后,就会释放掉共享锁 <br> <br> WAITFOR DELAY '00:00:05' --模拟事务处理,等待5秒 <br> <br> SELECT * FROM tb; --再次SELECT tb表 <br>ROLLBACK --回滚事务 <br> <br>在连接2中,执行 <br>UPDATE tb SET<br> val = val + 10 <br>WHERE id = 2; <br> <br>-------- <br>回到连接1中.可以看到.两次SELECT的结果是不同的. <br>因为在默认的READ COMMITTED隔离级别下,SELECT完了.就会马上释放掉共享锁.<br></span>
|
3、REPEATABLE READ
REPEATABLE READ事务不会产生脏读,并且在事务完成之前,任何其它事务都不能修改目前事务已读取的记录。
其它事务仍可以插入新记录,但必须符合当前事务的搜索条件——这意味着当前事务重新查询记录时,会产生幻读(Phantom Read)。
4、SERIALIZABLE
SERIALIZABLE可以防止除更新丢失外所有的一致性问题,即:
1.语句无法读取其它事务已修改但未提交的记录。
2.在当前事务完成之前,其它事务不能修改目前事务已读取的记录。
3.在当前事务完成之前,其它事务所插入的新记录,其索引键值不能在当前事务的任何语句所读取的索引键范围中。
5、SNAPSHOT
Snapshot事务中任何语句所读取的记录,都是事务启动时的数据。
这相当于事务启动时,数据库为事务生成了一份专用“快照”。在当前事务中看到不其它事务在当前事务启动之后所进行的数据修改。
Snapshot事务不会读取记录时要求锁定,读取记录的Snapshot事务不会锁住其它事务写入记录,写入记录的事务也不会锁住Snapshot事务读取数据。
四、悲观锁和乐观锁
1、悲观锁
悲观锁是指假设并发更新冲突会发生,所以不管冲突是否真的发生,都会使用锁机制。
悲观锁会完成以下功能:锁住读取的记录,防止其它事务读取和更新这些记录。其它事务会一直阻塞,直到这个事务结束.
悲观锁是在使用了数据库的事务隔离功能的基础上,独享占用的资源,以此保证读取数据一致性,避免修改丢失。
悲观锁可以使用Repeatable Read事务,它完全满足悲观锁的要求。
2、乐观锁
乐观锁不会锁住任何东西,也就是说,它不依赖数据库的事务机制,乐观锁完全是应用系统层面的东西。
如果使用乐观锁,那么数据库就必须加版本字段,否则就只能比较所有字段,但因为浮点类型不能比较,所以实际上没有版本字段是不可行的。
3、死锁
当二或多个工作各自具有某个资源的锁定,但其它工作尝试要锁定此资源,而造成工作永久封锁彼此时,会发生死锁。例如:
1. 事务 A取得数据列 1 的共享锁定。
2. 事务B取得数据列 2 的共享锁定。
3. 事务A现在要求数据列 2 的独占锁定,但会被封锁直到事务B 完成并释出对数据列 2 的共享锁定为止。
4. 事务B现在要求数据列 1 的独占锁定,但会被封锁直到事务A 完成并释出对数据列 1 的共享锁定为止。
等到事务B 完成后,事务A 才能完成,但事务B被事务A 封锁了。这个状况也称为「循环相依性」(Cyclic Dependency)。事务A相依于事务B,并且事务B也因为相依于事务A 而封闭了这个循环。
SQL Server遇到死锁时会自动杀死其中一个事务,而另一个事务会正常结束(提交或回滚)。
SQL Server对杀死的连接返回错误代码是1205,异常提示是:
Your transaction (process ID #52) was deadlocked on {lock | communication buffer | thRead} resources with another process and has been chosen as the deadlock victim. Rerun your transaction.
例如以下操作就会产生死锁,两个连接互相阻塞对方的update。
|
1
|
<span style=
"color: rgb(0, 0, 0);"
>连接1: <br>
begin
tran <br> <br>
select
*
from
customers <br> <br>
update
customers
set
CompanyName = CompanyName <br> <br> <br>waitfor delay
'00:00:05'
<br> <br> <br>
select
*
from
Employees <br>–因为Employees被连接2锁住了,所以这里会阻塞。 <br>
update
Employees
set
LastName = LastName <br>
commit
tran <br> <br>连接2: <br>
begin
tran <br> <br>
select
*
from
Employees <br> <br>
update
Employees
set
LastName = LastName <br> <br> <br>waitfor delay
'00:00:05'
<br> <br> <br>
select
*
from
customers <br>
--因为customers被连接1锁住了,所以这里会阻塞。 <br>update customers set CompanyName = CompanyName <br>commit tran<br></span>
|
4、如何避免死锁
(1).按同一顺序访问对象。(注:避免出现循环)
(2).避免事务中的用户交互。(注:减少持有资源的时间,较少锁竞争)
(3).保持事务简短并处于一个批处理中。(注:同(2),减少持有资源的时间)
(4).使用较低的隔离级别。(注:使用较低的隔离级别(例如已提交读)比使用较高的隔离级别(例如可序列化)持有共享锁的时间更短,减少锁竞争)
(5).使用基于行版本控制的隔离级别:2005中支持快照事务隔离和指定READ_COMMITTED隔离级别的事务使用行版本控制,可以将读与写操作之间发生的死锁几率降至最低:
SET ALLOW_SNAPSHOT_ISOLATION ON --事务可以指定 SNAPSHOT事务隔离级别;
SET READ_COMMITTED_SNAPSHOT ON --指定 READ_COMMITTED隔离级别的事务将使用行版本控制而不是锁定。默认情况下(没有开启此选项,没有加with nolock提示),SELECT语句会对请求的资源加S锁(共享锁);而开启了此选项后,SELECT不会对请求的资源加S锁。
注意:设置 READ_COMMITTED_SNAPSHOT选项时,数据库中只允许存在执行 ALTER DATABASE命令的连接。在 ALTER DATABASE完成之前,数据库中决不能有其他打开的连接。数据库不必一定要处于单用户模式中。
(6).使用绑定连接。(注:绑定会话有利于在同一台服务器上的多个会话之间协调操作。绑定会话允许一个或多个会话共享相同的事务和锁(但每个回话保留其自己的事务隔离级别),并可以使用同一数据,而不会有锁冲突。可以从同一个应用程序内的多个会话中创建绑定会话,也可以从包含不同会话的多个应用程序中创建绑定会话。在一个会话中开启事务(begin tran)后,调用exec sp_getbindtoken @Token out;来取得Token,然后传入另一个会话并执行EXEC sp_bindsession @Token来进行绑定(最后的示例中演示了绑定连接)。
五、.NET中使用指定的隔离级别开始一个事务
BeginTransaction函数有多个重载,其中一个可以指定事务的隔离级别
BeginTransaction(IsolationLevel):以指定的隔离级别启动数据库事务。
注意:在事务提交或回滚后,该事务的隔离级别为自动提交模式的所有后续命令保存 ( SQL Server默认设置) 中。这样将产生意外结果,例如 REPEATABLE READ隔离级别持续并阻止其他用户使用某一行。若要重置隔离级别为默认值 (读取操作),执行 Transact-SQL 设置事务隔离级别读作的语句或调用SqlConnection.BeginTransaction 后面紧跟SqlTransaction.Commit。
四、写出集合中常用接口及其实现类,并说明其各自特性。
答:
1.Map接口
请注意,Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
2.List接口
List是有序的Collection,用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
和下面要提到的Set不同,List允许有相同的元素。
3.Collection接口
两个标准的构造函数:无参数的构造函数用于创建一个空的Collection;有一个Collection参数的构造函数用于创建一个新的Collection
如何遍历:
|
1
2
3
4
|
Iterator it = collection.iterator();
//获得一个迭代子
while
(it.hasNext()) {
Object obj = it.next();
//得到下一个元素
}
|
由Collection接口派生的两个接口是List和Set。
4.ArrayList类
ArrayList实现了可变大小的数组。
它允许所有元素,包括null。
ArrayList没有同步。
5.Hashtable类
Hashtable继承Map接口,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。
添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。Hashtable通过initial capacity和load factor两个参数调整性能。通常缺省的load factor 0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大,这会影响像get和put这样的操作。
使用Hashtable的简单示例如下,将1,2,3放到Hashtable中,他们的key分别是“one”,“two”,“three”:
|
1
2
3
4
|
Hashtable numbers =
new
Hashtable();
numbers.put(“one”,
new
Integer(
1
));
numbers.put(“two”,
new
Integer(
2
));
numbers.put(“three”,
new
Integer(
3
));
|
要取出一个数,比如2,用相应的key:
Integer n = (Integer)numbers.get(“two”);
System.out.println(“two =”+ n);
由于作为key的对象将通过计算其散列函数来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方法。hashCode和equals方法继承自根类Object,如果你用自定义的类当作key的话,要相当小心,按照散列函数的定义,如果两个对象相同,即obj1.equals(obj2)==true,则它们的hashCode必须相同,但如果两个对象不同,则它们的hashCode不一定不同,如果两个不同对象的hashCode相同,这种现象称为冲突,冲突会导致操作哈希表的时间开销增大,所以尽量定义好的hashCode()方法,能加快哈希表的操作。
如果相同的对象有不同的hashCode,对哈希表的操作会出现意想不到的结果(期待的get方法返回null),要避免这种问题,只需要牢记一条:要同时复写equals方法和hashCode方法,而不要只写其中一个。
Hashtable是同步的。
6.Stack类
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
7.Set接口
Set是一种不包含重复的元素的Collection,即任意的两个元素e1和e2都有e1.equals(e2)==false,Set最多有一个null元素。
很明显,Set的构造函数有一个约束条件,传入的Collection参数不能包含重复的元素。
请注意:必须小心操作可变对象(Mutable Object)。如果一个Set中的可变元素改变了自身状态导致Object.equals(Object)==true将导致一些问题。
8.WeakHashMap类
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
9.Vector类
Vector非常类似ArrayList,但是Vector是同步的。
10.HashMap类
HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。但是将HashMap视为Collection时(values()方法可返回Collection),其迭代子操作时间开销和HashMap的容量成比例。因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低。
11.LinkedList类
允许null元素。
此外LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
五、(1)IO常用的类,字节流字符流处理常用类有哪些?
答:引用来源: http://blog.csdn.net/ilibaba/article/details/3955799
Java 流在处理上分为字符流和字节流。字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符、字符数组或字符串,而字节流处理单元为 1 个字节,操作字节和字节数组。
Java 内用 Unicode 编码存储字符,字符流处理类负责将外部的其他编码的字符流和 java 内 Unicode 字符流之间的转换。而类 InputStreamReader 和 OutputStreamWriter 处理字符流和字节流的转换。字符流(一次可以处理一个缓冲区)一次操作比字节流(一次一个字节)效率高。
( 一 )以字节为导向的 stream------InputStream/OutputStream
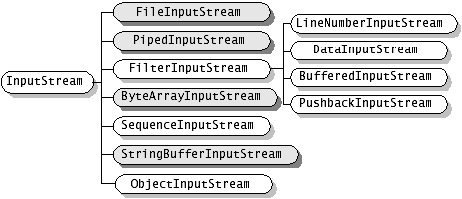
InputStream 和 OutputStream 是两个 abstact 类,对于字节为导向的 stream 都扩展这两个鸡肋(基类 ^_^ ) ;
1、 InputStream
1.1
ByteArrayInputStream -- 把内存中的一个缓冲区作为 InputStream 使用 .
construct---
(A)ByteArrayInputStream(byte[]) 创建一个新字节数组输入流( ByteArrayInputStream ),它从指定字节数组中读取数据( 使用 byte 作为其缓冲区数组)
(B)---ByteArrayInputStream(byte[], int, int) 创建一个新字节数组输入流,它从指定字节数组中读取数据。
---mark:: 该字节数组未被复制。
1.2
StringBufferInputStream -- 把一个 String 对象作为 InputStream .
construct---
StringBufferInputStream(String) 据指定串创建一个读取数据的输入流串。
注释:不推荐使用 StringBufferInputStream 方法。 此类不能将字符正确的转换为字节。
同 JDK 1.1 版中的类似,从一个串创建一个流的最佳方法是采用 StringReader 类。
1.3
FileInputStream -- 把一个文件作为 InputStream ,实现对文件的读取操作
construct---
(A)FileInputStream(File name) 创建一个输入文件流,从指定的 File 对象读取数据。
(B)FileInputStream(FileDescriptor) 创建一个输入文件流,从指定的文件描述器读取数据。
(C)-FileInputStream(String name) 创建一个输入文件流,从指定名称的文件读取数据。
method ---- read() 从当前输入流中读取一字节数据。
read(byte[]) 将当前输入流中 b.length 个字节数据读到一个字节数组中。
read(byte[], int, int) 将输入流中 len 个字节数据读入一个字节数组中。
1.4
PipedInputStream :实现了 pipe 的概念,主要在线程中使用 . 管道输入流是指一个通讯管道的接收端。
一个线程通过管道输出流发送数据,而另一个线程通过管道输入流读取数据,这样可实现两个线程间的通讯。
construct---
PipedInputStream() 创建一个管道输入流,它还未与一个管道输出流连接。
PipedInputStream(PipedOutputStream) 创建一个管道输入流 , 它已连接到一个管道输出流。
1.5
SequenceInputStream :把多个 InputStream 合并为一个 InputStream . “序列输入流”类允许应用程序把几个输入流连续地合并起来,
并且使它们像单个输入流一样出现。每个输入流依次被读取,直到到达该流的末尾。
然后“序列输入流”类关闭这个流并自动地切换到下一个输入流。
construct---
SequenceInputStream(Enumeration) 创建一个新的序列输入流,并用指定的输入流的枚举值初始化它。
SequenceInputStream(InputStream, InputStream) 创建一个新的序列输入流,初始化为首先 读输入流 s1, 然后读输入流 s2 。
2、 OutputSteam

2.1
ByteArrayOutputStream : 把信息存入内存中的一个缓冲区中 . 该类实现一个以字节数组形式写入数据的输出流。
当数据写入缓冲区时,它自动扩大。用 toByteArray() 和 toString() 能检索数据。
constructor
(A)--- ByteArrayOutputStream() 创建一个新的字节数组输出流。
(B)--- ByteArrayOutputStream() 创建一个新的字节数组输出流。
(C)--- ByteArrayOutputStream(int) 创建一个新的字节数组输出流,并带有指定大小字节的缓冲区容量。
toString(String) 根据指定字符编码将缓冲区内容转换为字符串,并将字节转换为字符。
write(byte[], int, int) 将指定字节数组中从偏移量 off 开始的 len 个字节写入该字节数组输出流。
write(int) 将指定字节写入该字节数组输出流。
writeTo(OutputStream) 用 out.write(buf, 0, count) 调用输出流的写方法将该字节数组输出流的全部内容写入指定的输出流参数。
2.2
FileOutputStream: 文件输出流是向 File 或 FileDescriptor 输出数据的一个输出流。
constructor
(A)FileOutputStream(File name) 创建一个文件输出流,向指定的 File 对象输出数据。
(B)FileOutputStream(FileDescriptor) 创建一个文件输出流,向指定的文件描述器输出数据。
(C)FileOutputStream(String name) 创建一个文件输出流,向指定名称的文件输出数据。
(D)FileOutputStream(String, boolean) 用指定系统的文件名,创建一个输出文件。
2.3
PipedOutputStream: 管道输出流是指一个通讯管道的发送端。 一个线程通过管道输出流发送数据,
而另一个线程通过管道输入流读取数据,这样可实现两个线程间的通讯。
constructor
(A)PipedOutputStream() 创建一个管道输出流,它还未与一个管道输入流连接。
(B)PipedOutputStream(PipedInputStream) 创建一个管道输出流,它已连接到一个管道输入流。
( 二 )以字符为导向的 stream Reader/Writer
以 Unicode 字符为导向的 stream ,表示以 Unicode 字符为单位从 stream 中读取或往 stream 中写入信息。
Reader/Writer 为 abstact 类
以 Unicode 字符为导向的 stream 包括下面几种类型:
1. Reader

1.1
CharArrayReader :与 ByteArrayInputStream 对应此类实现一个可用作字符输入流的字符缓冲区
constructor
CharArrayReader(char[]) 用指定字符数组创建一个 CharArrayReader 。
CharArrayReader(char[], int, int) 用指定字符数组创建一个 CharArrayReader
1.2
StringReader : 与 StringBufferInputStream 对应其源为一个字符串的字符流。
StringReader(String) 创建一新的串读取者。
1.3
FileReader : 与 FileInputStream 对应
1.4
PipedReader :与 PipedInputStream 对应
2. Writer

2.1 CharArrayWrite : 与 ByteArrayOutputStream 对应
2.2 StringWrite :无与之对应的以字节为导向的 stream
2.3 FileWrite : 与 FileOutputStream 对应
2.4 PipedWrite :与 PipedOutputStream 对应
3、两种不同导向的 stream 之间的转换
3.1
InputStreamReader 和 OutputStreamReader :
把一个以字节为导向的 stream 转换成一个以字符为导向的 stream 。
InputStreamReader 类是从字节流到字符流的桥梁:它读入字节,并根据指定的编码方式,将之转换为字符流。
使用的编码方式可能由名称指定,或平台可接受的缺省编码方式。
InputStreamReader 的 read() 方法之一的每次调用,可能促使从基本字节输入流中读取一个或多个字节。
为了达到更高效率,考虑用 BufferedReader 封装 InputStreamReader ,
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
例如: // 实现从键盘输入一个整数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
String s =
null
;
InputStreamReader re =
new
InputStreamReader(System.in);
BufferedReader br =
new
BufferedReader(re);
try
{
s = br.readLine();
System.out.println(
"s= "
+ Integer.parseInt(s));
br.close();
}
catch
(IOException e)
{
e.printStackTrace();
}
catch
(NumberFormatException e)
// 当应用程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出该异常。
{
System.out.println(
" 输入的不是数字 "
);
}
|
InputStreamReader(InputStream) 用缺省的字符编码方式,创建一个 InputStreamReader 。
InputStreamReader(InputStream, String) 用已命名的字符编码方式,创建一个 InputStreamReader 。
OutputStreamWriter 将多个字符写入到一个输出流,根据指定的字符编码将多个字符转换为字节。
每个 OutputStreamWriter 合并它自己的 CharToByteConverter, 因而是从字符流到字节流的桥梁。
(三)Java IO 的一般使用原则 :
一、按数据来源(去向)分类:
1 、是文件: FileInputStream, FileOutputStream, ( 字节流 )FileReader, FileWriter( 字符 )
2 、是 byte[] : ByteArrayInputStream, ByteArrayOutputStream( 字节流 )
3 、是 Char[]: CharArrayReader, CharArrayWriter( 字符流 )
4 、是 String: StringBufferInputStream, StringBufferOuputStream ( 字节流 )StringReader, StringWriter( 字符流 )
5 、网络数据流: InputStream, OutputStream,( 字节流 ) Reader, Writer( 字符流 )
二、按是否格式化输出分:
1 、要格式化输出: PrintStream, PrintWriter
三、按是否要缓冲分:
1 、要缓冲: BufferedInputStream, BufferedOutputStream,( 字节流 ) BufferedReader, BufferedWriter( 字符流 )
四、按数据格式分:
1 、二进制格式(只要不能确定是纯文本的) : InputStream, OutputStream 及其所有带 Stream 结束的子类
2 、纯文本格式(含纯英文与汉字或其他编码方式); Reader, Writer 及其所有带 Reader, Writer 的子类
五、按输入输出分:
1 、输入: Reader, InputStream 类型的子类
2 、输出: Writer, OutputStream 类型的子类
六、特殊需要:
1 、从 Stream 到 Reader,Writer 的转换类: InputStreamReader, OutputStreamWriter
2 、对象输入输出: ObjectInputStream, ObjectOutputStream
3 、进程间通信: PipeInputStream, PipeOutputStream, PipeReader, PipeWriter
4 、合并输入: SequenceInputStream
5 、更特殊的需要: PushbackInputStream, PushbackReader, LineNumberInputStream, LineNumberReader
决定使用哪个类以及它的构造进程的一般准则如下(不考虑特殊需要):
首先,考虑最原始的数据格式是什么: 原则四
第二,是输入还是输出:原则五
第三,是否需要转换流:原则六第 1 点
第四,数据来源(去向)是什么:原则一
第五,是否要缓冲:原则三 (特别注明:一定要注意的是 readLine() 是否有定义,有什么比 read, write 更特殊的输入或输出方法)
第六,是否要格式化输出:原则二
五、(2)文件名为c:\1.txt,追加一行“abcd”,代码怎么写?
答:引用来源《Java追加文件内容的三种方法》,http://www.douban.com/note/313085450/
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
/**
* 描述:追加内容到文件末尾
* @author Roger Federer
*
*/
public
static
void
main(String[] args)
throws
IOException {
File fileOrFilename =
new
File(
"d://text.txt"
);
// 方法 一
//追加文件:使用FileOutputStream,在构造FileOutputStream时,把第二个参数设为true
BufferedWriter out =
new
BufferedWriter(
new
OutputStreamWriter(
new
FileOutputStream(fileOrFilename,
true
)));
out.write(
"first 第一种方式 \r\n"
);
out.close();
// 方法 二
//追加文件:使用FileWriter
// 根据给定的文件名以及指示是否附加写入数据的 boolean 值来构造 FileWriter 对象。
// 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
FileWriter fw =
new
FileWriter(fileOrFilename,
true
);
fw.write(
"second第二种方式\r\n"
);
fw.close();
//BufferedWriter output = new BufferedWriter(new FileWriter(f,true));
//方法 三
//追加文件:使用RandomAccessFile
// 打开一个随机访问文件流,按读写方式
RandomAccessFile randomFile =
new
RandomAccessFile(fileOrFilename,
"rw"
);
// 文件长度,字节数
long
fileLength = randomFile.length();
// 将文件指针移到文件尾
randomFile.seek(fileLength);
randomFile.writeBytes(
"third 追加的内容\r\n"
);
randomFile.close();
}
/**
* 在文件前面追加文件内容
*
* @param filePath
* @return
*/
public
static
void
fileAppender(String fileName, String contents)
throws
IOException {
BufferedReader reader =
new
BufferedReader(
new
FileReader(fileName));
String line =
null
;
// 一行一行的读
StringBuilder sb =
new
StringBuilder();
sb.append(contents);
while
((line = reader.readLine()) !=
null
) {
sb.append(line);
sb.append(
"\r\n"
);
}
reader.close();
//写回去
RandomAccessFile write =
new
RandomAccessFile(fileName,
"rw"
);
write.writeBytes(sb.toString());
//<---会产生中文乱码
write.close();
}
|
六、RunTimeException和CheckedException有什么区别,你们项目中你们怎么处理异常?
答: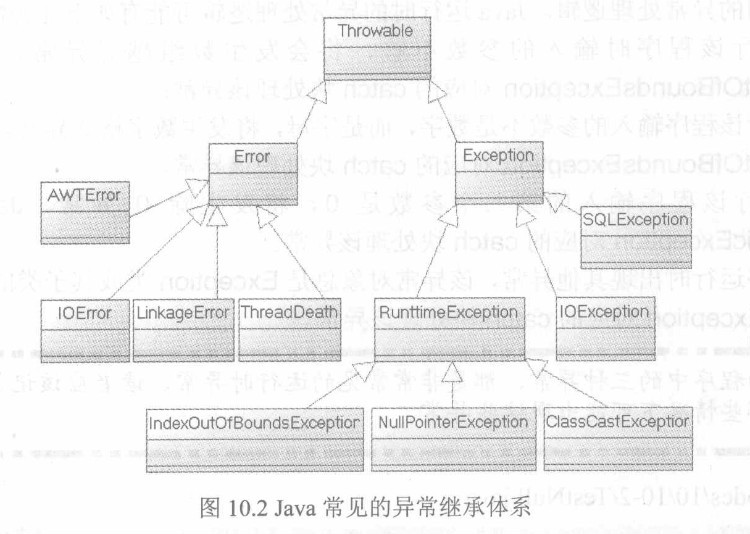
Java的异常被分为两大类:Checked异常和Runtime异常(运行时异常)。所有RuntimeException类及其子类实例被称为Runtime异常;不是RuntimeException类及其子类的异常实例则称为Checked异常。
只有Java语言提供了Checked异常,其他语言都没有提供Checked异常。Java认为Checked异常都是可以被处理(修复)的异常,所以Java程序必须显式处理Checked异常。
对于Checked异常的处理方式有两种:
(1)当前方法明确知道如何处理该异常,程序应该使用try...catch块来捕获该异常,然后对应的catch块中修补该异常。
(2)当前方法不知道如何处理这种异常,应该在定义该方法时声明抛出该异常。
Runtime异常则更加灵活,Runtime异常无须显式声明抛出,如果程序需要捕捉Runtime异常,也可以使用try...catch块来捕捉Runtime异常。
当使用throw语句自行抛出异常,如果throw语句抛出的异常是Checked异常,则该throw语句要么处于try块里,显式捕获该异常,要么放在一个带throws声明的方法中,即把该异常交给该方法的调用者处理;也就是说当出现了(不管是自行抛出的,还是系统抛出的)Checked异常,就要想办法去处理它,不能不理会它,要么显式地在try...catch块里捕获,处理它;要么把它放在一个带throws声明的方法中,把异常交给该方法的调用者处理。
如果throw语句抛出的异常是Runtime异常,则该语句无须放在try块里,也无须放在带throws声明抛出的方法中;程序既可以显式使用try...catch来捕获,并处理异常,也可以完全不处理该异常,把异常交给该方法调用者处理。(http://blog.163.com/quanquan127@126/blog/static/6884772520126394334182/)
ArithmeticException(除数为0的异常), BufferOverflowException(缓冲区上溢异常), BufferUnderflowException(缓冲区下溢异常), IndexOutOfBoundsException(出界异常), NullPointerException(空指针异常), EmptyStackException(空栈异常), IllegalArgumentException(不合法的参数异常), NegativeArraySizeException, NoSuchElementException, SecurityException, SystemException, UndeclaredThrowableException
1. java.lang.NullPointerException
异常的解释是"程序遇上了空指针",简单地说就是调用了未经初始化的对象或者是不存在的对象,即把数组的初始化和数组元素的初始化混淆起来了。数组的初始化是对数组分配需要的空间,而初始化后的数组,其中的元素并没有实例化,依然是空的,所以还需要对每个元素都进行初始化(如果要调用的话)
2. java.lang.ClassNotFoundException 异常的解释是"指定的类不存在"。
3. java.lang.ArithmeticException 这个异常的解释是"数学运算异常",比如程序中出现了除以零这样的运算就会出这样的异常。
4. java.lang.ArrayIndexOutOfBoundsException
异常的解释是"数组下标越界",现在程序中大多都有对数组的操作,因此在调用数组的时候一定要认真检查,看自己调用的下标是不是超出了数组的范围,一般来说,显示(即直接用常数当下标)调用不太容易出这样的错,但隐式(即用变量表示下标)调用就经常出错了,还有一种情况,是程序中定义的数组的长度是通过某些特定方法决定的,不是事先声明的,这个时候,最好先查看一下数组的length,以免出现这个异常。
5. java.lang.IllegalArgumentException
这个异常的解释是"方法的参数错误",比如g.setColor(int red,int green,int blue)这个方法中的三个值,如果有超过255的也会出现这个异常,因此一旦发现这个异常,我们要做的,就是赶紧去检查一下方法调用中的参数传递是不是出现了错误。
6. java.lang.IllegalAccessException
这个异常的解释是"没有访问权限",当应用程序要调用一个类,但当前的方法即没有对该类的访问权限便会出现这个异常。对程序中用了Package的情况下要注意这个异常(http://www.cnblogs.com/qinqinmeiren/archive/2010/10/14/2151702.html)
七、Spring如何处理数据库事务,你们项目中怎么处理数据库事务的?
答:
我们都知道事务的概念,那么事务的传播特性是什么呢?(此处着重介绍传播特性的概念,关于传播特性的相关配置就不介绍了,可以查看spring的官方文档)
在我们用SSH开发项目的时候,我们一般都是将事务设置在Service层 那么当我们调用Service层的一个方法的时候它能够保证我们的这个方法中执行的所有的对数据库的更新操作保持在一个事务中,在事务层里面调用的这些方法要么全部成功,要么全部失败。那么事务的传播特性也是从这里说起的。
如果你在你的Service层的这个方法中,除了调用了Dao层的方法之外,还调用了本类的其他的Service方法,那么在调用其他的 Service方法的时候,这个事务是怎么规定的呢,我必须保证我在我方法里掉用的这个方法与我本身的方法处在同一个事务中,否则如果保证事物的一致性。事务的传播特性就是解决这个问题的,“事务是会传播的”在Spring中有针对传播特性的多种配置我们大多数情况下只用其中的一种:PROPGATION_REQUIRED:这个配置项的意思是说当我调用service层的方法的时候开启一个事务(具体调用那一层的方法开始创建事务,要看你的aop的配置),那么在调用这个service层里面的其他的方法的时候,如果当前方法产生了事务就用当前方法产生的事务,否则就创建一个新的事务。这个工作使由Spring来帮助我们完成的。
以前没有Spring帮助我们完成事务的时候我们必须自己手动的控制事务,例如当我们项目中仅仅使用hibernate,而没有集成进 spring的时候,我们在一个service层中调用其他的业务逻辑方法,为了保证事物必须也要把当前的hibernate session传递到下一个方法中,或者采用ThreadLocal的方法,将session传递给下一个方法,其实都是一个目的。现在这个工作由 spring来帮助我们完成,就可以让我们更加的专注于我们的业务逻辑。而不用去关心事务的问题。
默认情况下当发生RuntimeException的情况下,事务才会回滚,所以要注意一下 如果你在程序发生错误的情况下,有自己的异常处理机制定义自己的Exception,必须从RuntimeException类继承 这样事务才会回滚!
Spring事务传播特性总结:
1.只要定义为spring的bean就可以对里面的方法使用@Transactional注解。
2.Spring的事务传播是Spring特有的。不是对底层jdbc的代理。
3.使用spring声明式事务,spring使用AOP来支持声明式事务,会根据事务属性,自动在[方法调用之前决定是否开启一个事务],并在[方法执行之后]决定事务提交或回滚事务。
4.Spring支持的PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:
PROPAGATION_REQUIRES_NEW:二个事务没有信赖关系,不会存在A事务的成功取决于B事务的情况。有可能存在A提交B失败。A失败(比如执行到doSomeThingB的时候抛出异常)B提交,AB都提交,AB都失败的可能。
PROPAGATION_NESTED:与PROPAGATION_REQUIRES_NEW不同的是,内嵌事务B会信赖A。即存在A失败B失败。A成功,B失败。A成功,B成功。而不存在A失败,B成功。
5. 特别注意PROPAGATION_NESTED的使用条件:使用JDBC 3.0驱动时,仅仅支持DataSourceTransactionManager作为事务管理器。需要JDBC 驱动的java.sql.Savepoint类。有一些JTA的事务管理器实现可能也提供了同样的功能。使用PROPAGATION_NESTED,还需要把PlatformTransactionManager的nestedTransactionAllowed属性设为true;而 nestedTransactionAllowed属性值默认为false;
6.特别注意PROPAGATION_REQUIRES_NEW的使用条件:JtaTransactionManager作为事务管理器
的AOP简介与事务传播特性总结2009-10-26 16:56srping用到的另外一项技术就是AOP(Aspect-Oriented Programming, 面向切面编程),它是一种新的方法论, 是对传统 OOP(Object-Oriented Programming, 面向对象编程)的补充。AOP 的主要编程对象是切面(aspect), 而切面模块化横切关注点。在应用 AOP 编程时, 仍然需要在定义公共功能, 但可以明确的定义这个功能在哪里, 以什么方式应用, 并且不必修改受影响的类. 这样一来横切关注点就被模块化到特殊的对象(切面)里。每个事物逻辑位于一个位置, 代码不分散,便于维护和升级,业务模块更简洁, 只包含核心业务代码。
现实中使用spring最多的就是声明式事务配置功能。下面就来了解其aop在事务上应用。首先要了解的就是AOP中的一些概念:
Aspect(切面):指横切性关注点的抽象即为切面,它与类相似,只是两者的关注点不一样,类是对物体特征的抽象,而切面是横切性关注点的抽象。
joinpoint(连接点):所谓连接点是指那些被拦截到的点。在spring中,这些点指的是方法,因为spring只支持方法类型的连接点,实际上joinpoint还可以是field或类构造器)。
Pointcut(切入点):所谓切入点是指我们要对那些joinpoint进行拦截的定义。
Advice(通知):所谓通知是指拦截到joinpoint之后所要做的事情就是通知.通知分为前置通知,后置通知,异常通知,最终通知,环绕通知。
Target(目标对象):代理的目标对象。
Weave(织入):指将aspects应用到target对象并导致proxy对象创建的过程称为织入。
Introduction(引入):在不修改类代码的前提下,Introduction可以在运行期为类动态地添加一些方法或Field。
所谓AOP,我的理解就是应该是这样一个过程,首先需要定义一个切面,这个切面是一个类,里面的方法就是关注点(也是通知),或者说里面的方法就是用来在执行目标对象方法时需要执行的前置通知,后置通知,异常通知,最终通知,环绕通知等等。有了切面和通知,要应用到目标对象,就需要定义这些通知的切入点,换句话说就是需要对哪些方法进行拦截,而这些被拦截的方法就是连接点,所谓连接点也就是在动态执行过程,被织入切面的方法(至少在spring中只能对方法进行拦截)。因此,在动态过程中通知的执行就属于织入过程,而被织入这些通知的对象就是目标对象了。
通常应用中,被织入的都是事务处理,对事务的织入不是普通简单的织入,它有着事务特有的特性——
事务的传播特性:
1. PROPAGATION_REQUIRED: 如果存在一个事务,则支持当前事务。如果没有事务则开启新的事物。
2. PROPAGATION_SUPPORTS: 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。
3. PROPAGATION_MANDATORY: 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
4. PROPAGATION_REQUIRES_NEW: 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
5. PROPAGATION_NOT_SUPPORTED: 总是非事务地执行,并挂起任何存在的事务。
6. PROPAGATION_NEVER: 总是非事务地执行,如果存在一个活动事务,则抛出异常
7.(spring)PROPAGATION_NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行。
这些都是事务特有的特性,比如前面分析的,如果两个在代码上不相关的操作,需要放在同一个事务中,这就需要利用到传播特性了,这时后调用的方法的传播特性的值就应该是PROPAGATION_REQUIRED。在spring中只需要进行这样的配置,就实现了生命式的事物处理。
通常应用中,被织入的都是事务处理,对事务的织入不是普通简单的织入,它有着事务特有的特性——
事务的传播特性:
1. PROPAGATION_REQUIRED: 如果存在一个事务,则支持当前事务。如果没有事务则开启新的事物。
2. PROPAGATION_SUPPORTS: 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。
3. PROPAGATION_MANDATORY: 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
4. PROPAGATION_REQUIRES_NEW: 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
5. PROPAGATION_NOT_SUPPORTED: 总是非事务地执行,并挂起任何存在的事务。
6. PROPAGATION_NEVER: 总是非事务地执行,如果存在一个活动事务,则抛出异常
7.(spring)PROPAGATION_NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行。
这些都是事务特有的特性,比如前面分析的,如果两个在代码上不相关的操作,需要放在同一个事务中,这就需要利用到传播特性了,这时后调用的方法的传播特性的值就应该是PROPAGATION_REQUIRED。在spring中只需要进行这样的配置,就实现了生命式的事务处理。
最后一点需要提及的就是Spring事务的隔离级别:
1. ISOLATION_DEFAULT:这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别。
2. ISOLATION_READ_UNCOMMITTED:这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
3. ISOLATION_READ_COMMITTED:保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。
4. ISOLATION_REPEATABLE_READ:这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
5. ISOLATION_SERIALIZABLE 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读外,还避免了幻像读。
除了第一个是spring特有的,另外四个与JDBC的隔离级别相对应。第二种隔离级别会产生脏读,不可重复读和幻像读,特别是脏读,一般情况下是不允许的,所以这种隔离级别是很少用到的。大多说数据库的默认格里基本是第三种。它能消除脏读,但是可重复读保证不了。第四种隔离级别也有一些数据库作为默认的隔离级别,比如MySQL。最后一种用的地方不多,除非是多数据访问的要求特别高,否则轻易不要用它,因为它会严重影响数据库的性能。
八、一个类用一个成员变量x,另一个类继承了该类,构造方法调用了父类的构造方法,,如何实现equals()方法和hashCode()方法,使两个类对象比较时对象相等,hashCode相等?
答:引用来源《equals方法和hashCode方法详解》,http://blog.csdn.net/lubiaopan/article/details/4791427
一、初识equals()和hashCode()方法
1、首先需要明确知道的一点是:hashCode()方法和equals()方法是在Object类中就已经定义了的,所以在java中定义的任何类都会有这两个方法。原始的equals()方法用来比较两个对象的地址值,而原始的hashCode()方法用来返回其所在对象的物理地址,下面来看一下在Object中的定义:
equals:
public boolean equals(Object obj) {//很明显,比较的是两个对象的地址是否相同
return (this == obj);
}
hashCode:
public native int hashCode();//由native修饰,对应一个本地实现
2、如果定义了一个类A,只要它没有重写这两个方法,这两个方法的意义就是如上面所述。请看下面的示例:
示例一
public class Test{
public static void main(String args[]){
Demo d1=new Demo(1,”abc“);
Demo d2=new Demo(1,”abc“);
System.out.println(d1.equals(d2));//输出false,虽然d1和d2的参数都是(1,abc),但是他们指向不同的内存地址
System.out.println(d1.hashCode());
System.out.println(d2.hashCode());//d1和d2的hashCode不同
}
}
class Demo{
int a;
String b;
public Demo(int a,String b){
this.a=a;
this.b=b;
}
}
二、equals()和hashCode()的重写
前面说到,因为这两个方法都是在Object类中定义,所以java中定义的所有类都会有这两个方法,并且根据实际需要可以重写这两个方法,当方法被重写后,他们所代表的意义就会发生变化,看下面的代码:
示例二
public class TestString{
public static void main(String args[]){
String s1=new String("abc");
String s2=new String("abc");
System.out.println(s1.equals(s2));//输出true,因为String类重写了equals()方法,虽然s1和s2此时指向的地址空间不同,它比较的不再是地址而是String的内容, 此时s1和s2都是"abc",故返回true
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());//你会发现s1和s2的hashCode相同,因为String同样重写了hashCole()方法,返回的不再是地址,而是根据具体的字符串算出的一个值
}
}
三、equals()和hashCode()方法是怎样被重写的
1、我们来看一下String类中这两个方法的定义:
equals()方法:
public boolean equals(Object anObject) {
if (this == anObject) {//首先进行两个对象地址的比较,如果地址相同了,那么,对象的内容也肯定相同
return true;
}
if (anObject instanceof String) {//比较两个String对象的内容是否相同,相同返回true,不同返回false
String anotherString = (String)anObject;
int n = count;
if (n == anotherString.count) {
char v1[] = value;
char v2[] = anotherString.value;
int i = offset;
int j = anotherString.offset;
while (n-- != 0) {
if (v1[i++] != v2[j++])
return false;
}
return true;
}
}
return false;
}
hashCode()方法:
public int hashCode() {
int h = hash;
if (h == 0) {
int off = offset;
char val[] = value;
int len = count;
for (int i = 0; i < len; i++) {//通过一个特定的算法算出一个hash值,此时的hash值不是对象的地址,而是决定于String的内容是什么,只要两个字符串内容相同,他们的hashCode就相同
h = 31*h + val[off++];
}
hash = h;
}
return h;
}
2、下面我们改写示例一的代码,对equals和hashCode进行重写:
示例三(粉色部分为改动的代码)
class Demo{
int a;
String b;
public Demo(int a,String b){
this.a=a;
this.b=b;
}
public int hashCode(){
return a*(b.hashCode());
}
public boolean equals(Object o){
Demo d=(Demo)o;
return (this.a==d.a)&&(this.b.equals(d.b));
}
}
public class Test{
public static void main(String args[]){
Demo d1=new Demo(1,"abc");
Demo d2=new Demo(1,"abc");
System.out.println(d1.equals(d2));//输出为true,由于重写了equals(),此时比较的不再是对象地址,而是对象内容此时两个对象的内容都是(1,abc)
System.out.println(d1.hashCode());
System.out.println(d2.hashCode());//d1和d2的hash值相同,由于重写了hashCode (),此时返回的不再是地址,而是根据对象内容算出的一个值
}
}
3、小结
1、String 、Math、Integer以及Double等这些封装类已经对equals()和hashCode()方法进行了重写,这两个方法在这些类中已经改变了其本来意义;
2、如果X.equals(Y),那么它们的X和Y的hashCode值一定相同(这也是java规范中规定的),不管equals进行的是地址比较还是内容比较;
3、如果两个对象X和Y的hashCode相同,但是X.equals(Y)不一定成立(比如:如果示例三中只重写了hashCode方法,没有重写equals方法,那么System.out.println(d1.equals(d2))一定会输出false);
四、equals()和hashCode()方法的应用
HashSet集合:
Hashset是java中一个非常重要的集合类,Hashset中不能有重复的元素,当一个元素添加到集合中的时候,Hashset判断元素是否重复的依据是这样的:
1)判断两个对象的hashCode是否相等
如果不相等,认为两个对象也不相等,完毕
如果相等,转入2)
(这一点只是为了提高存储效率而要求的,其实理论上没有也可以,但如果没有,实际使用时效率会大大降低,所以我们这里将其做为必需的)
2)判断两个对象用equals运算是否相等
如果不相等,认为两个对象也不相等
如果相等,认为两个对象相等(equals()是判断两个对象是否相等的关键)
为什么是两条准则,难道用第一条不行吗?不行,因为前面已经说了,hashcode()相等时,equals()方法也可能不等,所以必须用第2条准则进行限制,才能保证加入的为非重复元素。
示例四
import java.util.*;
public class TestString{
public static void main(String args[]){
HashSet<String> hSet=new HashSet<String>();
String s1=new String("abc");
String s2=new String("abc");
hSet.add(s1);
hSet.add(s2);
System.out.println(hSet.size());//输出1
}
}
解析:以上代码输出1,即hSet中只有一个元素。当添加s2时,发现s1和s2的hashCode相同;然后调用equals方法返回true,hSet会以为两个元素相同,不会添加s2。
示例五
import java.util.*;
public class TestString{
public static void main(String args[]){
HashSet<String> hSet=new HashSet<String>();
String s1=new String("abc");
String s2=new String("123");
hSet.add(s1);
hSet.add(s2);
System.out.println(hSet.size());//输出2
}
}
解析:以上代码输出2,即hSet中有两个元素。当添加s2时,发现s1和s2的hashCode不同,然后s2将添加进去。
示例六
import java.util.*;
public class Test{
public static void main(String args[]){
HashSet<Demo> hSet=new HashSet<Demo>();
Demo d1=new Demo(1,"abc");
Demo d2=new Demo(1,"abc");
hSet.add(d1);
hSet.add(d2);
System.out.println(hSet.size());//输出2
}
}
class Demo{
int a;
String b;
public Demo(int a,String b){
this.a=a;
this.b=b;
}
}
解析:以上代码输出2,即hSet中有两个元素。当添加d2,发现d1和d2的hashCode不同,然后d2将添加进去。
示例七
import java.util.*;
public class Test{
public static void main(String args[]){
HashSet<Demo> hSet=new HashSet<Demo>();
Demo d1=new Demo(1,"abc");
Demo d2=new Demo(1,"abc");
hSet.add(d1);
hSet.add(d2);
System.out.println(hSet.size());//输出2
}
}
class Demo{
int a;
String b;
public Demo(int a,String b){
this.a=a;
this.b=b;
}
public boolean equals(Object o){
Demo d=(Demo)o;
return (this.a==d.a)&&(this.b.equals(d.b));
}
}
解析:以上代码输出2,即hSet中有两个元素。当添加d2,发现d1和d2的hashCode相同,然后调用equals方法(此处的equals方法未被重写),d1和d2的地址不同,故将d2添加到hSet中去。
示例八
import java.util.*;
public class Test{
public static void main(String args[]){
HashSet<Demo> hSet=new HashSet<Demo>();
Demo d1=new Demo(1,"abc");
Demo d2=new Demo(1,"abc");
hSet.add(d1);
hSet.add(d2);
System.out.println(hSet.size());//输出1
}
}
class Demo{
int a;
String b;
public Demo(int a,String b){
this.a=a;
this.b=b;
}
public int hashCode(){
return a*(b.hashCode());
}
public boolean equals(Object o){
Demo d=(Demo)o;
return (this.a==d.a)&&(this.b.equals(d.b));
}
}
解析:以上代码输出2,即hSet中有两个元素。当添加d2,发现d1和d2的hashCode相同,然后调用equals方法(此处的equals方法已被重写,注意和示例七进行对比),d1和d2的内容也相同,故将d2不能添加到hSet中去。还可以构造其他示例,我在这里就不一一列举了,读者可以自己进行验证。
小结:当我们向HashSet中添加元素的时候,我们必须明确判断元素间不同的依据是什么,然后确定是两个方法都重写,还是只重写其中的一个方法,或者是两个方法都不用重写。这些都需要视具体的应用而定,但是有一点必须要保证,那就是:如果X.equals(Y),那么它们的X和Y的hashCode值一定要相同。下面以hibernate框架为例进行分析:
关于在hibernate的pojo类中,重写equals()和hashcode()的问题:
1),重点是equals,重写hashCode只是技术要求(为了提高效率)
2),为什么要重写equals呢,因为在java的集合框架中,是通过equals来判断两个对象是否相等的
3),在hibernate中,经常使用set集合来保存相关对象,而set集合是不允许重复的。我们再来谈谈前面提到在向hashset集合中添加元素时,怎样判断对象是否相同的准则,前面说了两条,其实只要重写equals()这一条也可以。
但当hashset中元素比较多时,或者是重写的equals()方法比较复杂时,我们只用equals()方法进行比较判断,效率也会非常低,所以引入了hashcode()这个方法,只是为了提高效率,但是我觉得这是非常有必要的(所以我们在前面以两条准则来进行hashset的元素是否重复的判断)。
比如可以这样写:
public int hashCode(){
return 1;}//等价于hashcode无效
这样做的效果就是在比较哈希码的时候不能进行判断,因为每个对象返回的哈希码都是1,每次都必须要经过比较equals()方法后才能进行判断是否重复,这当然会引起效率的大大降低。
九、Struts+Spring+Hibernate三大框架,对于项目开发有何作用,相比其它Java Web开发框架有什么优缺点?
答:引用来源,http://jingyan.baidu.com/article/7908e85c4d2a70af481ad20e.html
典型的J2EE三层结构,分为表现层、中间层(业务逻辑层)和数据服务层。三层体系将业务规则、数据访问及合法性校验等工作放在中间层处理。客户端不直接与数据库交互,而是通过组件与中间层建立连接,再由中间层与数据库交互。
1、表现层是传统的JSP技术,自1999年问世以来,经过多年的发展,其广泛的应用和稳定的表现,为其作为表现层技术打下了坚实的基础。
中间层采用的是流行的Spring+Hibernate,为了将控制层与业务逻辑层分离,又细分为以下几种。
2、Web层,就是MVC模式里面的“C”(controller),负责控制业务逻辑层与表现层的交互,调用业务逻辑层,并将业务数据返回给表现层作组织表现,该系统的MVC框架采用Struts。
3、Service层(就是业务逻辑层),负责实现业务逻辑。业务逻辑层以DAO层为基础,通过对DAO组件的正面模式包装,完成系统所要求的业务逻辑。
4、DAO层,负责与持久化对象交互。该层封装了数据的增、删、查、改的操作。
5、PO,持久化对象。通过实体关系映射工具将关系型数据库的数据映射成对象,很方便地实现以面向对象方式操作数据库,该系统采用Hibernate作为ORM框架。
6、Spring的作用贯穿了整个中间层,将Web层、Service层、DAO层及PO无缝整合,其数据服务层用来存放数据。
7、一个良好的框架可以让开发人员减轻重新建立解决复杂问题方案的负担和精力;它可以被扩展以进行内部的定制化;并且有强大的用户社区来支持它。框架通常能很好的解决一个问题。然而,你的应用是分层的,可能每一个层都需要各自的框架。仅仅解决UI问题并不意味着你能够很好的将业务逻辑和持久性逻辑和UI 组件很好的耦合。
优缺点:
Struts:
优点:首先他是开源的,使开发者可以更深了解他的原理和内部实现机制, 可扩展性
采用MVC模式分离业务逻辑层 显示层 模型层 低耦合,结构清晰,使开发者专注于业务逻辑
还有丰富的标签库供使用
支持国际化
还有很高的重用性
缺点: Struts将MVC中的控制层 一分为三 在获得结构更加清晰的同时,也增加了系统的复杂度
ActionForms使用不便、无法进行单元测试
对servlet依赖性过强,struts在处理action时 必须要依赖 httprequest和 HttpResponse 对象
Hibernate
优点: 他是数据库连接的中间件,而且对程序的依赖性很小 透明性 使用了java的反射机制
轻量级 他对jdbc进行了轻量级的封装 而且可以在程序中取代EJB的cmp,完成持久化
性能很好,而且还是轻量级 很灵活
他支持多种数据库 的 1对多的复杂关系
可以完全使用面向对象的思想去编程
使用了JTA JDBC 和 JNDI技术
缺点:一个持久化类不能映射多个表
相对内存消耗JDBC是最省内存的,hibernate次之 ejb Bean 最差
Spring
优点:spring 是基于ioc(控制反转)和aop(面向切面编程) 的框架
而且封装了所有的事务,不需要程序员自己去提交事务,一切都由web容器去控制,省去了很多代码
spring采用了单态和工厂模式 采用mvc模式下的java程序 尽管已经把层与层之间的关系耦合度降低,但还是有联系, 这时候使用spring 把所有bean都交由web容器去控制 创建和销毁,这样才真正的降低了耦合度, 而且bean的创建的生命周期都在web容器里控制,而且他从工厂里实例的bean都是单态的,当然可以加一个属性让他不是单态
面向接口编程,只需要知道要实现的接口就可以,不需要知道他的具体实现
使用spring框架有利于单元测试
十、解释一下云计算技术,你用过哪些云计算开源框架,有何优缺点?
答:引用来源,百度百科
云计算 (cloud computing)是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。云是网络、互联网的一种比喻说法。过去在图中往往用云来表示电信网,后来也用来表示互联网和底层基础设施的抽象。因此,云计算甚至可以让你体验每秒10万亿次的运算能力,拥有这么强大的计算能力可以模拟核爆炸、预测气候变化和市场发展趋势。用户通过电脑、笔记本、手机等方式接入数据中心,按自己的需求进行运算。
对云计算的定义有多种说法。对于到底什么是云计算,至少可以找到100种解释。[现阶段广为接受的是美国国家标准与技术研究院(NIST)定义:云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 进入可配置的计算资源共享池(资源包括网络,服务器,存储,应用软件,服务),这些资源能够被快速提供,只需投入很少的管理工作,或与服务供应商进行很少的交互。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
十一、斐波那契数列,又称黄金分割数列,指的是这样一个数列:0、1、1、2、3、5、8、13、21、……在数学上,斐波纳契数列。用递归算法写出。
答:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public
class
Test {
/*
斐波那契数列: 0、1、1、2、3、5、8
可以这样理解 f0 = 0; f1 = 1; fn = f(n-1) + f(n - 2) (n >= 2)
*/
public
static
void
main(String[] args) {
System.out.println(f(
5
));
}
public
static
int
f(
int
n) {
if
(n ==
1
|| n ==
2
) {
return
1
;
}
else
{
return
f(n -
1
) + f(n -
2
);
}
}
}
|
http://my.oschina.net/huangzhuang/blog/380578 --博客来源