直接进入正题:一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析。但是一些简单的动态页面比如翻页等动态异步就不用大动干戈的使用Selenium等测试工具框架模拟浏览器执行js操作,直接发送post请求即可。
下面介绍中基协的异步翻页爬取:
创建爬虫不再赘述。
一、页面分析
1.首先右键==》检查==》打开如下界面:

最简单的检验异步方式:点击下一页,发现网页并没有刷新,异步加载石锤了。
2.进入Network调试,使用XHR过滤(XMLHttpRequest对象可以在不向服务器提交整个页面的情况下,实现局部更新网页。)
通过翻页可以看到明显的加载请求:

3.详细请求:

以上的Request URL就是我们要的url请求地址了:
http://gs.amac.org.cn/amac-infodisc/api/pof/manager?rand=0.6415105865638795&page=0&size=20。
可以发现,每次翻页请求改变的只是page以及随机数rand。
4.请求参数
可以看到这个post请求只有三个参数:
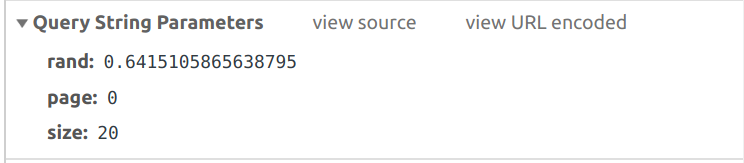
5.查看响应:
一般Ajax请求的数据都是结构化数据。

以上可以看到我们想要的数据:数据集合content、每页数量numberOfElements、数据总量totalElements、总页数totalPages。
内心偷乐吧,也不需要xpath或者css解析了,后面拿到数据直接json解析就好了,非常方便。
二、代码实现
class Amac2Spider(scrapy.Spider):
name = 'amac2'
allowed_domains = ['gs.amac.org.cn']
# custome_setting可用于自定义每个spider的设置,而setting.py中的都是全局属性的,当你的
# scrapy工程里有多个spider的时候这个custom_setting就显得很有用了
custom_settings = {
"DEFAULT_REQUEST_HEADERS": {
'authority': 'gs.amac.org.cn',
#请求报文可通过一个“Accept”报文头属性告诉服务端 客户端接受什么类型的响应。
'accept': 'application/json, text/javascript, */*; q=0.01',
#指定客户端可接受的内容编码
'accept-encoding': 'gzip, deflate',
#指定客户端可接受的语言类型
'accept-language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4',
#跨域的时候get,post都会显示origin,同域的时候get不显示origin,post显示origin,说明请求从哪发起,仅仅包括协议和域名
'origin': 'http://gs.amac.org.cn',
#表示这个请求是从哪个URL过来的,原始资源的URI
'referer': 'http://gs.amac.org.cn/amac-infodisc/res/pof/manager/index.html',
#设置请求头信息User-Agent来模拟浏览器
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
#cookie也是报文属性,传输过去
'cookie': 'cna=/oN/DGwUYmYCATFN+mKOnP/h; tracknick=adimtxg; _cc_=Vq8l%2BKCLiw%3D%3D; tg=0; thw=cn; v=0; cookie2=1b2b42f305311a91800c25231d60f65b; t=1d8c593caba8306c5833e5c8c2815f29; _tb_token_=7e6377338dee7; CNZZDATA30064598=cnzz_eid%3D1220334357-1464871305-https%253A%252F%252Fmm.taobao.com%252F%26ntime%3D1464871305; CNZZDATA30063600=cnzz_eid%3D1139262023-1464874171-https%253A%252F%252Fmm.taobao.com%252F%26ntime%3D1464874171; JSESSIONID=8D5A3266F7A73C643C652F9F2DE1CED8; uc1=cookie14=UoWxNejwFlzlcw%3D%3D; l=Ahoatr-5ycJM6M9x2/4hzZdp6so-pZzm; mt=ci%3D-1_0',
#就是告诉服务器我参数内容的类型
'Content-Type': 'application/json',
}
}
#需要重写start_requests方法
def start_requests(self):
#网页里ajax链接
url = "http://gs.amac.org.cn/amac-infodisc/api/pof/manager?"
#所有请求集合
requests = []
#这里只模拟一页range(0, 1)
for i in range(0, 1):
random_random = random.random()
#封装post请求体参数
my_data = {'page': '111', 'size': '20','rand':str(random_random)}
#模拟ajax发送post请求
request = scrapy.Request(url, method='POST',
callback=self.parse_model,
body=json.dumps(my_data),
encoding='utf-8')
requests.append(request)
return requests
def parse_model(self, response):
#可以利用json库解析返回来得数据,在此省略
jsonBody = json.loads(response.body)
#拿到数据,再处理就简单了。不再赘述
pass
这样就可以愉快的实现了scrapy抓取ajax异步数据~