Hive的占位符与文件的调用
概述
对于上述的工作,我们发现需要手动去写hql语句从而完成离线数据的ETL,但每天都手动来做显然是不合适的,所以可以利用hive的文件调用与占位符来解决这个问题。
Hive文件的调用
实现步骤:
1)编写一个文件,后缀名为 .hive,
比如我们现在我们创建一个01.hive文件
目的是在 hive的weblog数据库下,创建一个tb1表
01.hive 文件编写示例:
use weblog;
create table tb1 (id int,name string);
2)进入hive安装目录的bin目录
执行: sh hive -f 01.hive
注:-f 参数后跟的是01.hive文件的路径
3)测试hive的表是否创建成功
Hive占位符的使用
我们现在想通过hive执行文件,将 "tb1"这个表删除
则我们可以这样做
1)创建02.hive文件
编写示例:
use weblog;
drop table ${tb_name}
2)在bin目录下,执行:
sh hive -f 02.hive -d tb_name="tb1"
结合业务的实现
在hive最后插入数据时,涉及到一个日志的分区是以每天为单位,所以我们需要手动去写这个日期,比如 2017-8-20。
现在,我们学习了Hive文件调用和占位符之后,我们可以这样做
1)将hql语句里的日期相关的取值用占位符来表示,并写在weblog.hive文件里
编写示例:
use weblog;
insert overwrite table tongji select ${reportTime},tab1.pv,tab2.uv,tab3.vv,tab4.br,tab5.newip,tab6.newcust,tab7.avgtime,tab8.avgdeep from (select count(*) as pv from dataclear where reportTime = ${reportTime}) as tab1,(select count(distinct uvid) as uv from dataclear where reportTime = ${reportTime}) as tab2,(select count(distinct ssid) as vv from dataclear where reportTime = ${reportTime}) as tab3,(select round(br_taba.a/br_tabb.b,4)as br from (select count(*) as a from (select ssid from dataclear where reportTime=${reportTime} group by ssid having count(ssid) = 1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime=${reportTime}) as br_tabb) as tab4,(select count(distinct dataclear.cip) as newip from dataclear where dataclear.reportTime = ${reportTime} and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime < ${reportTime})) as tab5,(select count(distinct dataclear.uvid) as newcust from dataclear where dataclear.reportTime=${reportTime} and uvid not in (select dc2.uvid from dataclear as dc2 where dc2.reportTime < ${reportTime})) as tab6,(select round(avg(atTab.usetime),4) as avgtime from (select max(sstime) - min(sstime) as usetime from dataclear where reportTime=${reportTime} group by ssid) as atTab) as tab7,(select round(avg(deep),4) as avgdeep from (select count(distinct urlname) as deep from dataclear where reportTime=${reportTime} group by ssid) as adTab) as tab8;
2.在hive 的bin目录下执行:
sh hive -f weblog.hive -d reportTime="2017-8-20"
对于日期,如果不想手写的话,可以通过linux的指令来获取:
> date "+%G-%m-%d"
所以我们可以这样来执行hive文件的调用:
>sh hive -f 03.hive -d reportTime=date “+%G-%m-%d” (注:是键盘左上方的反引号)
也可以写为:
sh hive -f 03.hive -d reportTime=$(date "+%G-%m-%d")
Linux Crontab 定时任务
在工作中需要数据库在每天零点自动备份所以需要建立一个定时任务。
crontab命令的功能是在一定的时间间隔调度一些命令的执行。
可以通过 crontab -e 进行定时任务的编辑
crontab文件格式:
-
* * * * command
minute hour day month week command
分 时 天 月 星期 命令

0 0 * * * ./home/software/hive/bin/hive -f /home/software/hive/bin/03.hive -d reportTime=`
date %G-%y-%d`
每隔1分钟,执行一次任务
编写示例:
*/1 * * * * rm -rf /home/software/1.txt
每隔一分钟,删除指定目录的 1.txt文件
实时业务系统搭建
实现步骤:
1.启动zk集群
2.启动kafka集群
指令:sh kafka-server-start.sh ../config/server.properties
3.配置flume的agent
rmr /brokers
rmr /admin
rmr /isr_change_notification
rmr /controller_epoch
rmr /rmstore
rmr /consumers
rmr /config
配置示例:
a1.sources=r1
a1.channels=c1 c2
a1.sinks=k1 k2
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.234.11:9000/weblog/reportTime=%Y-%m-%d
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=1000
a1.sinks.k2.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.brokerList=192.168.234.21:9092
a1.sinks.k2.topic=weblog
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.channels.c2.type=memory
a1.channels.c2.capacity=1000
a1.channels.c2.transactionCapacity=100
a1.sources.r1.channels=c1 c2
a1.sinks.k1.channel=c1
a1.sinks.k2.channel=c2
启动kafka:sh kafka-server-start.sh ../config/server.properties
4.创建kafka的topic
执行:
sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 2 --topic weblog
5.创建kafak的consumer,测试是否能够收到消息
执行: sh kafka-console-consumer.sh --zookeeper hadoop01:2181 --topic weblog
6.执行测试:
访问页面——>flume——>kafka
Kafka-Storm系统搭建
实现步骤:
- 创建java工程
- 导入storm依赖jar包、kafka依赖包、storm-kafka依赖包及相关依赖

3.移除重复的jar包
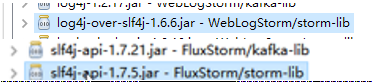
注意:删除1.75,留1.72的 - 开发代码
Storm业务处理说明
数据清洗:
去除多余的字段 只保留 有用的字段 并且对于ss字段做拆分
url、urlname、uvid、ssid、sscount、sstime、cip
WebLogTopology代码:
public class WebLogTopology {
public static void main(String[] args) throws Exception {
//1.指定zk集群地址
BrokerHosts hosts = new ZkHosts("192.168.234.21:2181,192.168.234.22:2181,192.168.234.23:2181");
//--设定hosts,topic,zkroot(zkroot需要提前在zk下创建完毕,
//本例中,应在zk下注册 /weblog/info 节点
SpoutConfig conf = new SpoutConfig(hosts, "weblog", "/weblog", "info");
conf.scheme = new SchemeAsMultiScheme(new StringScheme());
//--创建KafkaSpout,用于接收Kafka的消息源
KafkaSpout spout = new KafkaSpout(conf);
//--创建Bolt
PrintBolt printBolt = new PrintBolt();
//2.创建构建者
TopologyBuilder builder = new TopologyBuilder();
//3.组织拓扑
builder.setSpout("Weblog_spout", spout);
builder.setBolt("Print_Bolt", printBolt).shuffleGrouping("Weblog_spout");
//4.创建拓扑
StormTopology topology = builder.createTopology();
//5.提交到集群中运行 - 本地测试
LocalCluster cluster = new LocalCluster();
Config config = new Config();
cluster.submitTopology("Weblog_Topology", config, topology);
Thread.sleep(100 * 1000);
cluster.killTopology("Weblog_Topology");
cluster.shutdown();
}
}
PrintBolt代码:
public class PrintBolt extends BaseRichBolt {
private OutputCollector collector = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
Fields fields = input.getFields();
StringBuffer buf = new StringBuffer();
Iterator<String> it = fields.iterator();
while(it.hasNext()){
String key = it.next();
Object value = input.getValueByField(key);
buf.append(key+":"+value);
}
System.out.println(buf.toString());
collector.ack(input);
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
测试:当访问页面时,访问一次,Strom会接收一条信息并打印如下:

Storm业务处理—上
数据清洗
当Storm收到一条数据后:
str:http://localhost:8090/Demo/b.jsp|b.jsp|页面B|UTF-8|1024x768|24-bit|zh-cn|0|1|27.0 r0|0.5690286228250014|http://localhost:8090/Demo/a.jsp|Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2783.4 Safari/537.36|78024453153757966560|9974858526_1_1511218867768|0:0:0:0:0:0:0:1
接下来需要做数据清洗,去除多余的字段,保留有用字段。
url、urlname、uvid、ssid、sscount、sstime、cip
流式的业务处理
pv—点击量,一条日志就是一次pv,可以实时处理
vv—独立会话,根据ssid实现流式处理
uv—独立访客数,根据uvid可以实时处理
此外,
br—跳出率,一天内跳出的会话总数/会话总数,不适合实时处理
avgtime—一天内所有会话的访问时常的平均值,不适合实时处理
avgdeep—平均访问深度,不适合实时处理
综上,我们可以看到并不是所有的业务都适合实时处理的。
业务代码实现
ClearBolt代码:
public class ClearBolt extends BaseRichBolt{
private OutputCollector collector = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
String value = input.getStringByField("str");
String [] attrs = value.split("\\|");
String url = attrs[0];
String urlname = attrs[1];
String uvid = attrs[13];
String ssid = attrs[14].split("_")[0];
String sscount = attrs[14].split("_")[1];
String sstime = attrs[14].split("_")[2];
String cip = attrs[15];
collector.emit(input,new Values(url,urlname,uvid,ssid,sscount,sstime,cip));
collector.ack(input);
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("url","urlname","uvid","ssid","sscount","sstime","cip"));
}
}
PvBlot代码:
public class PvBolt extends BaseRichBolt {
private static int pv=0;
private OutputCollector collector = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
pv++;
List<Object> values=input.getValues();
values.add(pv);
collector.emit(values);
collector.ack(input);
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("url","urlname","uvid","ssid","sscount","sstime","cip","pv"));
}
}
VvBolt代码:
public class VvBolt extends BaseRichBolt {
private OutputCollector collector = null;
private static int vv=1;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
String sscount = input.getStringByField("sscount");
if(sscount.equals("0")){
vv++;
}
List<Object> values = input.getValues();
values.add(vv);
collector.emit(input,values);
collector.ack(input);
} catch (Exception e) {
e.printStackTrace();
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("url","urlname","uvid","ssid","sscount","sstime","cip","pv","vv"));
}
}
UvBolt代码:
public class UvBolt extends BaseRichBolt{
private Map<String, Integer> uvMap=new HashMap<>();
private OutputCollector collector = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
String uvid=input.getStringByField("uvid");
List<Object> values=input.getValues();
if(uvMap.containsKey(uvid)){
values.add(uvMap.size());
collector.emit(values);
collector.ack(input);
}else{
uvMap.put(uvid,1);
values.add(uvMap.size());
collector.emit(values);
collector.ack(input);
}
} catch (Exception e) {
collector.fail(input);
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("url","urlname","uvid","ssid","sscount","sstime","cip","pv","vv","uv"));
}
}
WebLogTopology代码:
public class WebLogTopology {
public static void main(String[] args) throws Exception {
BrokerHosts hosts = new ZkHosts("192.168.234.21:2181,192.168.234.22:2181,192.168.234.23:2181");
SpoutConfig conf = new SpoutConfig(hosts, "weblog", "/weblog", UUID.randomUUID().toString());
conf.scheme = new SchemeAsMultiScheme(new StringScheme());
KafkaSpout spout = new KafkaSpout(conf);
PrintBolt printBolt = new PrintBolt();
ClearBolt clearBolt=new ClearBolt();
PvBolt pvBolt=new PvBolt();
VvBolt vvBolt=new VvBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("Weblog_spout", spout);
builder.setBolt("Clear_Blot",clearBolt).shuffleGrouping("Weblog_spout");
builder.setBolt("Pv_Bolt", pvBolt).shuffleGrouping("Clear_Blot");
builder.setBolt("Vv_Bolt",vvBolt).shuffleGrouping("Pv_Bolt");
builder.setBolt("Print_Bolt", printBolt).shuffleGrouping("Vv_Bolt");
StormTopology topology = builder.createTopology();
LocalCluster cluster = new LocalCluster();
Config config = new Config();
cluster.submitTopology("Weblog_Topology", config, topology);
}
}
HbaseBolt
HbaseBolt代码:
public class HBaseBolt extends BaseRichBolt{
private OutputCollector collector = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
try {
FluxInfo fi = new FluxInfo();
fi.setUrl(input.getStringByField("url"));
fi.setUrlname(input.getStringByField("urlname"));
fi.setUvid(input.getStringByField("uvid"));
fi.setSsid(input.getStringByField("ssid"));
fi.setSstime(input.getStringByField("sstime"));
fi.setSscount(input.getStringByField("sscount"));
fi.setCip(input.getStringByField("cip"));
HBaseDao.saveToHbase(fi);
collector.ack(input);
} catch (Exception e) {
e.printStackTrace();
collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
HbaseDao代码:
public class HBaseDao {
public static void saveToHbase(FluxInfo fi){
HTable tab = null;
try {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum",
"192.168.150.137:2181,192.168.150.138:2181,192.168.150.139:2181");
//2.创建HTable对象
tab = new HTable(conf,"t2".getBytes());
//3.向表中存入数据
Put put = new Put(fi.getRK().getBytes());
put.add("cf1".getBytes(), "url".getBytes(), fi.getUrl().getBytes());
put.add("cf1".getBytes(), "urlname".getBytes(), fi.getUrlname().getBytes());
put.add("cf1".getBytes(), "uvid".getBytes(), fi.getUvid().getBytes());
put.add("cf1".getBytes(), "ssid".getBytes(), fi.getSsid().getBytes());
put.add("cf1".getBytes(), "sscount".getBytes(), fi.getSscount().getBytes());
put.add("cf1".getBytes(), "sstime".getBytes(), fi.getSstime().getBytes());
put.add("cf1".getBytes(), "cip".getBytes(), fi.getCip().getBytes());
tab.put(put);
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.关闭连接
try {
tab.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
FluxInfo代码:
import java.util.Random;
import org.junit.Test;
public class FluxInfo {
private String url;
private String urlname;
private String uvid;
private String ssid;
private String sscount;
private String sstime;
private String cip;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getUrlname() {
return urlname;
}
public void setUrlname(String urlname) {
this.urlname = urlname;
}
public String getUvid() {
return uvid;
}
public void setUvid(String uvid) {
this.uvid = uvid;
}
public String getSsid() {
return ssid;
}
public void setSsid(String ssid) {
this.ssid = ssid;
}
public String getSscount() {
return sscount;
}
public void setSscount(String sscount) {
this.sscount = sscount;
}
public String getSstime() {
return sstime;
}
public void setSstime(String sstime) {
this.sstime = sstime;
}
public String getCip() {
return cip;
}
public void setCip(String cip) {
this.cip = cip;
}
public String getRK(){
return sstime+"_"+uvid+"_"+ssid+"_"+(int)(Math.random()*100);
}
}
启动Hbase
1.进入Hbase安装目录的bin目录
执行:sh start-hbase.sh
2.执行 sh hbase shell 客户端
建表: create 'weblog' 'info'
3.启动Storm进行测试,看数据是否能进入到hbase中
启动Storm集群,打jar进行测试
1.启动nimbus 后台进程
执行: ./storm nimbus >/dev/null 2>&1 &
2.启动supervisor 后台进程
执行:./storm supervisor >/dev/null 2>&1 &
3.启动 ui 后台进程
执行:./storm ui >/dev/null 2>&1 &
Storm集群的启动

Storm伪实时处理—tick机制
TickBolt_1代码:
public class TickBolt_1 extends BaseRichBolt{
@Override
public Map<String, Object> getComponentConfiguration() {
Config config=new Config();
config.put(config.TOPOLOGY_TIC1K_TUPLE_FREQ_SECS,5);
return config;
}
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
System.out.println("tick1");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}
TickBolt_2代码:
public class TickBolt_2 extends BaseRichBolt{
@Override
public Map<String, Object> getComponentConfiguration() {
Config config=new Config();
config.put(config.TOPOLOGY_TICK_TUPLE_FREQ_SECS,7);
return config;
}
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
System.out.println("tick2");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
}
TickTopology代码:
public class TickTopology {
public static void main(String[] args) {
Config config=new Config();
//config.put(config.TOPOLOGY_TICK_TUPLE_FREQ_SECS,1);
TickBolt_1 tickBolt1=new TickBolt_1();
TickBolt_2 tickBolt2=new TickBolt_2();
TopologyBuilder builder=new TopologyBuilder();
builder.setBolt("tick1", tickBolt1);
builder.setBolt("tick2", tickBolt2);
StormTopology topology=builder.createTopology();
LocalCluster cluster=new LocalCluster();
cluster.submitTopology("Tick_Topology",config,topology);
}
}
贝叶斯定理
贝叶斯介绍
英国数学家,贝叶斯在数学方面主要研究概率论.对于统计决策函数、统计推断、统计的估算等做出了贡献。
他对统计推理的主要贡献是使用了"逆概率"这个概念,并把它作为一种普遍的推理方法提出来。贝叶斯定理原本是概率论中的一个定理,这一定理可用一个数学公式来表达,这个公式就是著名的贝叶斯公式。
贝叶斯定理
公式:
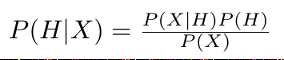
求得是后验概率
等式右侧为先验概率
案例说明一:
假设:H代表胃癌事件,X代表胃疼事件。则P(H | X)表示的是:当一个人胃疼时,是胃癌的概率有多少? P(H | X)称为后验概率,我们利用贝叶斯公式的目的就是求得这个后验概率是多少。
而求后验的前提是要知道 P(X | H ),P(H ),以及P(X )的概率。
针对本例,这三个是可以根据临床试验数据得到的,
P ( X | H)表示的是:胃癌发生时,胃疼的概率,假设是:85%。P ( X | H)称为先验概率,先验概率一般是由大量过去的经验总结得到,或者也可以通过抽样得到。
比如说:电商的28定律(20%的热门商品集中了80%的访问流量)就是一个总结得到的先验概率,当然我们也可以通过抽样,通过实验数据来得到这个结论,根据大数定律,当实验样本越大,越接近于正确结论。
P(H )表示的是:总人群患胃癌的概率:0.1%
P ( X)表示的是:总人群患胃疼的概率:40%
有了以上数据后,问:当一个人胃疼时,他患胃癌的概率 P(X | H )是多少?
结果是:0.85*0.001%0.4=0.002125=0.021
即当一个人胃疼时,是胃癌的概率是2.1%。这个概率是很小的。
案例说明二:
比如我们要判断某一封邮件是否是垃圾邮件,假设:H代表此邮件是垃圾邮件
X代表此邮件里出现了"美女"词汇。则P(H | X )表示的是:当一封邮件里出现"美女"词汇时,它是垃圾邮件的概率。
为了求得这个后验概率,我们需要知道P( X | H ) 、P ( H )、P(X )的概率
P(X | H)表示一封垃圾邮件里,出现"美女"词汇的概率。关键这个先验概率怎么求得,因为这个问题并不像胃癌案例那样受到广泛关注,所以并没有现成的先验概率供使用,所以这个概率需要我们通过实验样本来获取。
实现步骤:
1.从已有的垃圾邮件箱里随机收取100封垃圾邮件,然后统计每封垃圾邮件里,出现"美女"的次数,假设最后的结果:100封垃圾邮件里,有20封出现了"美女"。
则:P(X | H)=20%
当然,这个先验概率如果为了更准确,可以扩大样本数据或增加实验次数。
2.接下来求P( H )和P(X)
P(H )表示的是一封邮件是垃圾邮件的概率,
P ( X )表示的是一封邮件里出现"美女"的概率,
这两个也没有现成的先验概率,所以需要通过实验获取。
我们可以从邮件箱里(包含正常邮件和垃圾邮件),随机抽取500封邮件,然后统计有多少封是垃圾邮件,以及统计每逢邮件里出现 "美女"的次数。
假设:500封邮件里,出现了60封垃圾邮件。
500封邮件里,出现了200次"美女”
则: P(H)=60/500 % P( X)=200/500 %
所以综上,我们可以利用贝叶斯来对邮件过滤,当收到一封邮件时,这封邮件包含了"美女"词汇,请问它是正常邮件还是垃圾邮件?
经计算可得:P(H | X)=0.2*(60/500)/ (200/500)=0.06=6%
总结:本例中,根据概率的阈值,来判定一封邮件是否是垃圾邮件。比如算得的概率是80%,则可以认定此邮件是垃圾邮件
即这封邮件是垃圾邮件的概率是6%,一般地,垃圾邮件设定的阈值在60%~100%。而6%<60%,所以这封邮件是一封正常邮件。
针对本例,如果换个条件,比如:P(X )表示的是一封邮件里出现"发票"的概率,
P(X | H)=0.9 一封垃圾邮件里出现"发票"的概率是90%
P(H)=0.2 一封邮件是垃圾邮件的概率是20%
P(X)=0.25 "发票"在邮件中出现的概率25%
最后算得:
当一封邮件含有 "发票"时,它是垃圾邮件的概率是 0.9*0.2/0.25=75%
它是垃圾邮件
贝叶斯公式实际可以做如下变形:
P(X | H)· P(H)/P(X)=P(H | X)
先验概率 · 似然比 = 后验概率
贝叶斯决策理论方法是统计模型决策中的一个基本方法,其基本思想是:
1、已知类条件概率密度参数表达式和先验概率。
2、利用贝叶斯公式转换成后验概率。
3、根据后验概率大小进行决策分类。
案例说明三:
根据上两个案例,可以将贝叶斯公式进行变换得到下面的公式:

H1和H2是两个事件,一般是对立事件,即P(H1)+P(H2)=100%
P(E | H1)表示当满足H1条件时,发生E事件的概率。 P(E | H2)同理
P(H1 | E)或 P(H2 | E)表示的是当E事件发生时,H1或H2发生的概率,即我们要求的后验概率。
场景说明:
一机器在良好状态生产合格产品几率是90%,在故障状态生产合格产品几率是30%,机器良好的概率是75%,若一日第一件产品是合格品,那么此日机器良好的概率是多少。
P(H | X )
P ( X | H )=0.9
P ( H )=0.75
P(X )=
这道题心算即可——
(1)先验比率是75% : (1-75%) = 3 : 1;
(2)似然比率(Likelihood ratio)= 90% : 30% = 3;
(3)两者相乘,得后验比率 = 9 : 1;然后
(4)标准化(normalize),得后验概率 = 9 / (9+1) = 90%。
解释:
假设美国和日本要打架,美国军事战斗力是75%,日本军事战斗力是25%。
问:此时,美国和日本的战力比是多少?
答:75% : 25% = 3 : 1。
问:现在,德国发明了一种新型战斗机,能增强军事战斗力,卖给了美国和日本。但是美国和日本的军事体量不同,美国引进这种战斗机后,战斗力增加了 90 倍;而日本引入之后战斗力只增加 30 倍。
请问,两国引入这种战斗机后,目前的战力比是多少?
答:美国战斗力: 3 x 90 = 270,日本战斗力 :1 x 30 = 30。
美国:日本 = 270 : 30 = 9 : 1
即美国军事力量目前占90%,日本军事力量10%。如果美国打日本,有9成把握取胜。
【解释】
现在让我把上面的故事翻译一下,套到题目上。
(1) 你一开始有两个假说,良好(H1)和故障(H2),
H1和H2的先验概率比 = P(H1) : P(H2) = 3 : 1。【用P(良好) = 75%即可推出。】
(2)现在你拿到了一个证据E:第一天产品是合格的。这个证据的作用,在于改变两个假说的概率之比。
根据贝叶斯定理,这个「1 个零件合格」的证据会产生两个效果:
a. 会让 「机器良好」(H1) 的相对概率增加 90 倍 【因为 P(E|H1) = 90% 】,及
b. 会让 「机器故障」(H2) 的相对概率增加 30 倍 【因为 P(E|H2) = 30% 】。
【公式上看,应该是分别缩减到 0.9 倍和 0.3 倍,但是化为整数比较容易思考。】
(3) 根据(2),我们有了证据 E 之后,良好和故障的概率之比变为 3 x 90 : 1 x 30 = 270 : 30 = 9 : 1。
(4) 根据现有条件,其实还算不出 P(良好|1个合格) 。要算出 P(良好|1个合格) 的具体数值,还须明确给出一个条件,即「良好」和「故障」已经包括所有的假设了:
P(良好|1个合格) + P(故障|1个合格) = 1。
然后联立刚才得到的
P(良好|1个合格) : P(故障|1个合格) = 9 : 1,可解出
P(良好|1个合格) = 90%。

对应刚才的推理的,是贝叶斯定理常见形式的一个变体——分别对H1、H2列式,两式相除即可得。
最左边一项是先验比率(美国:日本=75:25),
中间一项是似然比率(新型战机对美国和日本的战力影响,90:30),
最右边一项是后验比率(最后的结果,9:1)。
朴素贝叶斯分类器

代码示例:
>data <- matrix(c("sunny","hot","high","weak","no",
"sunny","hot","high","strong","no",
"overcast","hot","high","weak","yes",
"rain","mild","high","weak","yes",
"rain","cool","normal","weak","yes",
"rain","cool","normal","strong","no",
"overcast","cool","normal","strong","yes",
"sunny","mild","high","weak","no",
"sunny","cool","normal","weak","yes",
"rain","mild","normal","weak","yes",
"sunny","mild","normal","strong","yes",
"overcast","mild","high","strong","yes",
"overcast","hot","normal","weak","yes",
"rain","mild","high","strong","no"),
byrow = TRUE,
dimnames = list(day = c(),condition = c("outlook","temperature","humidity","wind","playtennis")),
nrow=14, ncol=5);
#计算先验概率
> prior.yes = sum(data[,5] == "yes") / length(data[,5]);
> prior.no = sum(data[,5] == "no") / length(data[,5]);
> naive.bayes.prediction <- function(condition.vec) {
# Calculate unnormlized posterior probability for playtennis = yes.
playtennis.yes <-
sum((data[,1] == condition.vec[1]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(outlook = f_1 | playtennis = yes)
sum((data[,2] == condition.vec[2]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(temperature = f_2 | playtennis = yes)
sum((data[,3] == condition.vec[3]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(humidity = f_3 | playtennis = yes)
sum((data[,4] == condition.vec[4]) & (data[,5] == "yes")) / sum(data[,5] == "yes") * # P(wind = f_4 | playtennis = yes)
prior.yes; # P(playtennis = yes)
# Calculate unnormlized posterior probability for playtennis = no.
playtennis.no <-
sum((data[,1] == condition.vec[1]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(outlook = f_1 | playtennis = no)
sum((data[,2] == condition.vec[2]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(temperature = f_2 | playtennis = no)
sum((data[,3] == condition.vec[3]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(humidity = f_3 | playtennis = no)
sum((data[,4] == condition.vec[4]) & (data[,5] == "no")) / sum(data[,5] == "no") * # P(wind = f_4 | playtennis = no)
prior.no;# P(playtennis = no)
return(list(post.pr.yes = playtennis.yes,
post.pr.no = playtennis.no,
prediction = ifelse(playtennis.yes >= playtennis.no, "yes", "no"))); }
> naive.bayes.prediction(c("overcast", "mild", "normal", "weak"));
$post.pr.yes
[1] 0.05643739
$post.pr.no
[1] 0
$prediction
[1] "yes"
结果:
Tom会打网球
上一篇 37.大数据之旅——网站流量统计项目