白葡萄酒质量探索
数据来自于uci机器学习数据库中的白葡萄酒部分
library(ggplot2)
library(gridExtra)
library(GGally)
# 加载数据
df <- read.csv('wineQualityWhites.csv')
汇总统计
# 察看数据结构
str(df)

从这里我们可以发现一共有4898行观测值,以及13个变量。
# 察看汇总分析
summary(df)

固定酸
# 画出固定酸含量分布图
ggplot(aes(x = fixed.acidity), data = df) +
geom_histogram(binwidth = 0.1) +
scale_x_continuous(breaks = seq(3.5, 15.5, 3))
summary(df$fixed.acidity)
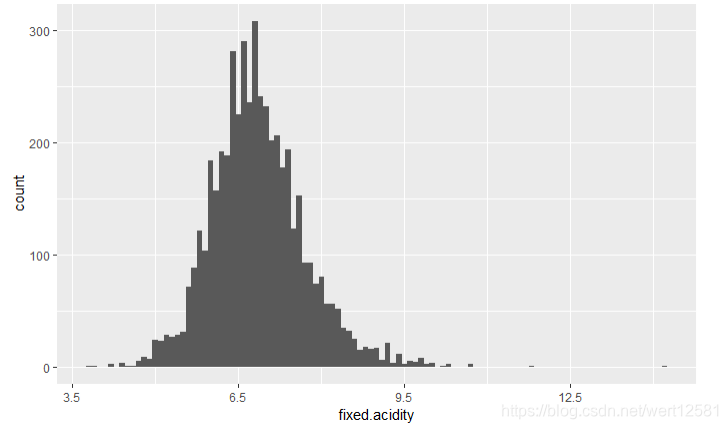
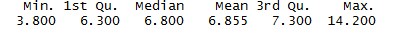
从结果中可以发现,固定酸的含量大致是一个正态分布。50%的数据分布在6.3-7.3(g/dm^3)的范围之内。中位数为6.800,平均值为 6.855。
挥发性酸
# 画出挥发酸含量分布图
ggplot(aes(x = volatile.acidity), data = df) +
geom_histogram(binwidth = 0.01) +
scale_x_continuous(breaks = seq(0.1, 1.2, 0.2))
summary(df$volatile.acidity)

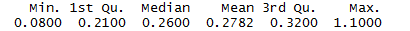
从结果中,我们可以发现,挥发酸的含量大致是一个正态分布。50%的数据分布在0.21-0.32(g/dm^3)的范围之内。中位数为0.26,平均值为 0.2782。
柠檬酸
# 画出柠檬酸的分布图
ggplot(aes(x = citric.acid), data = df) +
geom_histogram(binwidth = 0.01) +
scale_x_continuous(breaks = seq(0, 1.8, 0.2))
summary(df$citric.acid)
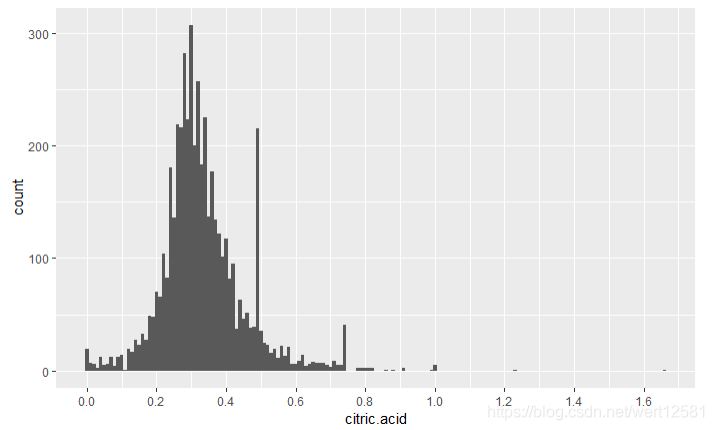

从结果中,我们可以发现,柠檬酸的含量大致是一个正态分布(除去右边的大于0.6的异常值)。50%的数据分布在0.27-0.39(g/dm^3)的范围之内。中位数为0.32,平均值为0.3342。同时由于,上述提到的三个变量都是酸,因此把固定酸,挥发酸,柠檬酸三项合起来定义一个新的特征总酸量。
残留糖分
# 画出残留糖分分布图
ggplot(aes(x = residual.sugar), data = df) +
geom_histogram(binwidth = 1)
summary(df$residual.sugar)
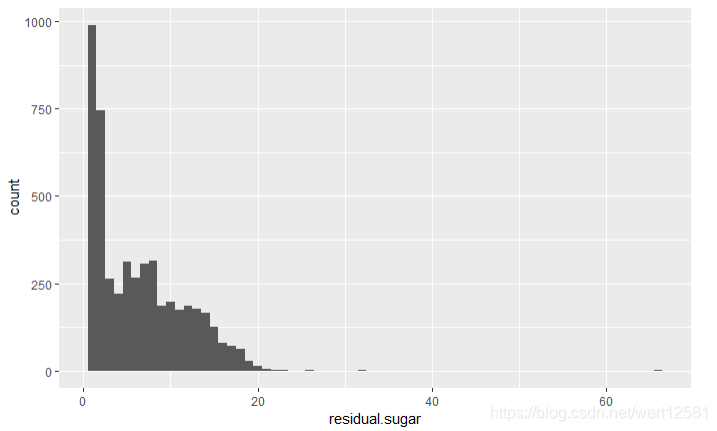

从图中可以看出,残留糖分不是正态分布也不像偏态分布,并且由于坐标之间差距很大,因此在下图使用Log10作伪标尺,再来确认一下分布。从数据上可以看出,50%的数据分布在1.7-9.9(g/dm^3)的范围内,中位数为5.2,平均数为6.391.
# 使用log10尺度来显示分布图
ggplot(aes(x = residual.sugar), data = df) +
geom_histogram(binwidth = 0.05) +
scale_x_log10() +
xlab('residual.sugar by log10')
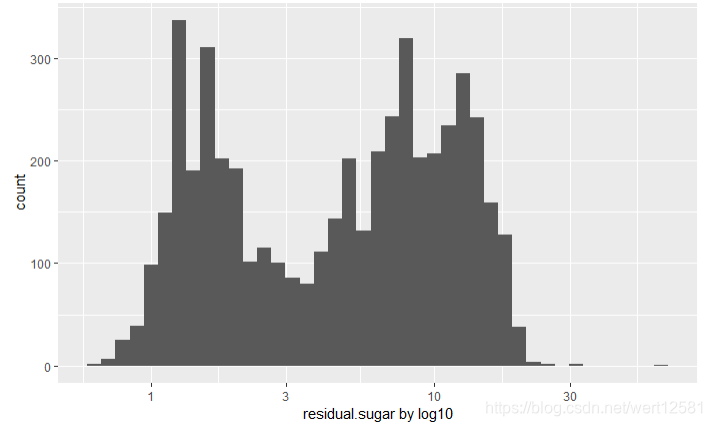
从图中可以发现,变成log10显示后,很明显残余糖分出现了一个双峰的形状。结合这个因素,我们新定义一个特征,类型。以5为分界线,定义干葡萄酒(dry)以及甜葡萄酒(sweet)。
# 建立新的变量type包含干与甜,并且画出分布图
df$type<-ifelse(df$residual.sugar >= 5, 'sweet', 'dry')
ggplot(aes(x = type), data = df) +
geom_bar(width = 0.3)
table(df$type)
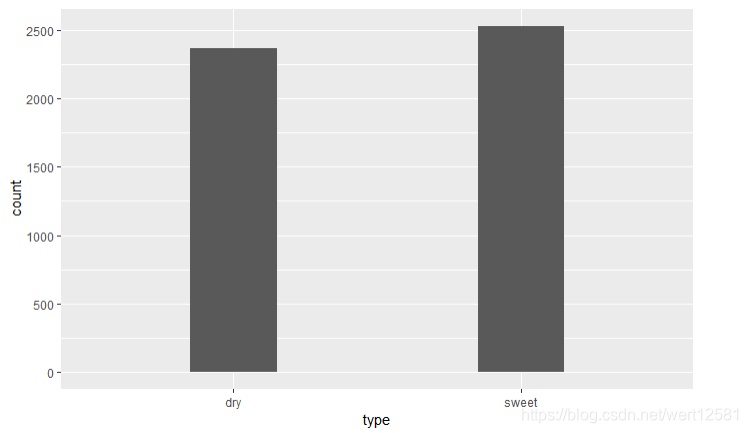
可以看到干葡萄酒和甜葡萄酒数量分别是2367,2531。
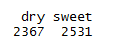
氯化物
# 画出氯化物含量分布图
ggplot(aes(x = chlorides), data = df) +
geom_histogram(binwidth = 0.005)
summary(df$chlorides)
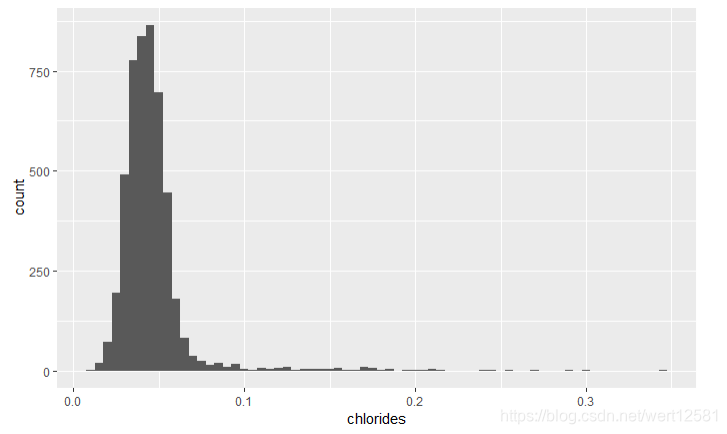

从结果中可以发现氯化物成一个长尾分布,50%的数据分布在0.036-0.05(g/dm^3)的范围之内。中位数为0.043,平均数为0.04577。
游离二氧化硫
# 画出游离二氧化硫分布图
ggplot(aes(x = free.sulfur.dioxide), data = df) +
geom_histogram(binwidth = 2)
summary(df$free.sulfur.dioxide)
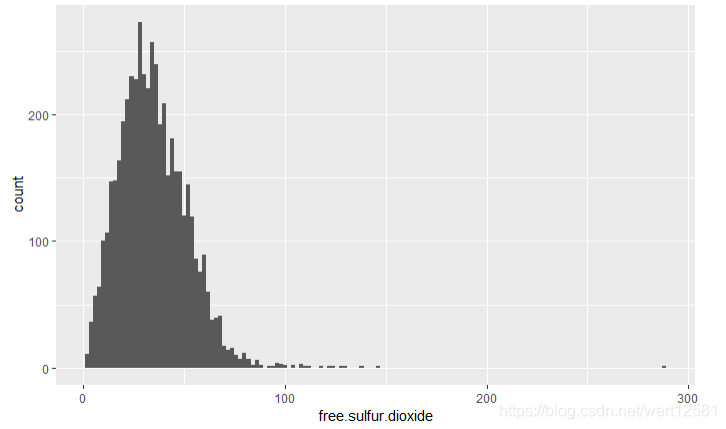

从结果中可以发现整体是一个长尾分布,50%的数据分布在23.00-35.31(mg/dm^3)之间,中位数为34.00,平均数为35.31。
总二氧化硫
# 画出总二氧化硫分布图
ggplot(aes(x = total.sulfur.dioxide), data = df) +
geom_histogram(binwidth = 3)
summary(df$total.sulfur.dioxide)
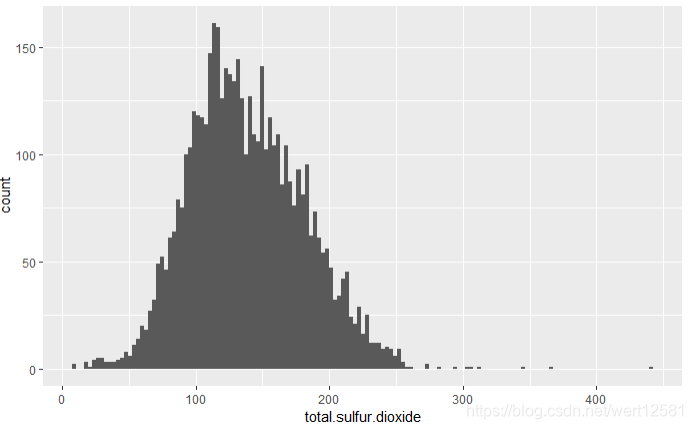
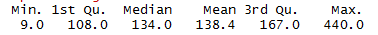
从结果中可以发现,50%的数据分布在108.-138.4(mg/dm^3)之间,中位数为134.00,平均数为138.4。
密度
# 画出密度分布图
ggplot(aes(x = density), data = df) +
geom_histogram(binwidth = 0.0003) +
scale_x_continuous(breaks = seq(.98, 1.04, 0.01))
summary(df$density)


从结果中可以看出,密度的分布区间很小,而且密度的大小与酒精的含量由一定的关系(酒精密度比水小酒精越多密度越小),之后在双变量研究中准备进行探究。
pH
# 画出pH分布图
ggplot(aes(x = pH),data = df) +
geom_histogram(binwidth = 0.01) +
scale_x_continuous(breaks = seq(2.7, 3.8, 0.1))
summary(df$pH)
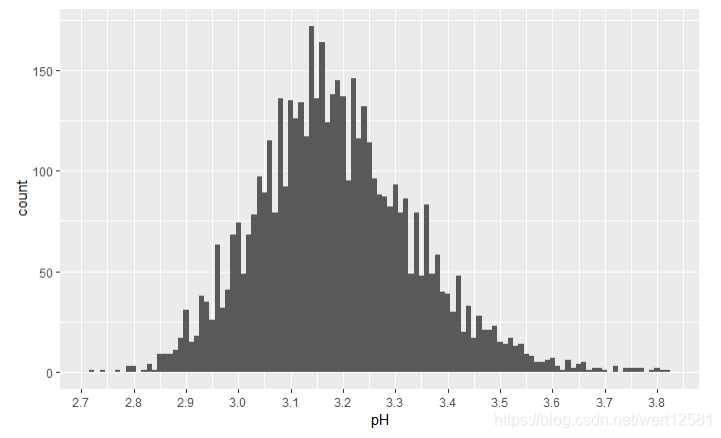

从结果中可以发现,pH大致是一个正态分布,50%的数据位于3.09-3.28之间。中位数为3.18,平均数为3.188。
硫酸钾
# 画出硫酸钾含量分布图
ggplot(aes(x = sulphates), data = df) +
geom_histogram(binwidth = 0.02)
summary(df$sulphates)
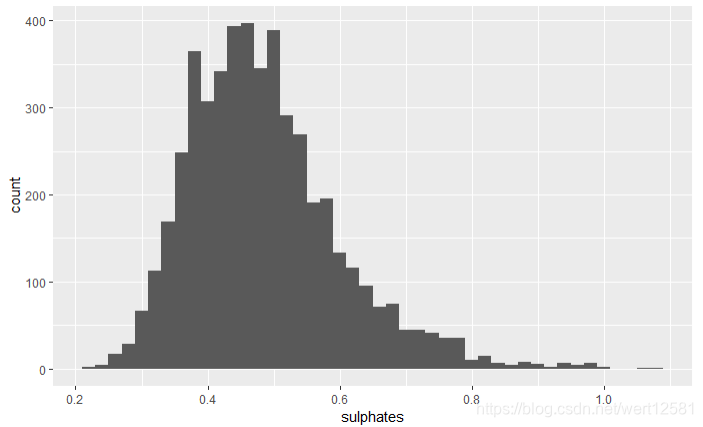

从结果中可以看出,硫酸钾的含量大致是正态分布(略为长尾)。50%的数据位于0.4100-0.5500(g/dm^3)之间,中位数为0.47,平均数为0.4898。
从上面的分析中可以看到有许多与酸有关的量。这里假设固定酸与游离酸的和中包含了柠檬酸及二氧化硫(txt文件中明没有说明是否包含,这里只是进行个人假设)。因此将固定酸于柠檬酸的和记做一个新的变量-总酸量。
从结果中可以发现,由于固定酸的含量远高于挥发酸的含量,以你总体的分布与固定酸的含量没有太大的变化。50%的数据分布在6.7-7.59(g/dm^3)的范围之内。中位数为7.07,平均值为7.133。
酒精度
# 画出酒精度分布图
ggplot(aes(x = alcohol), data = df) +
geom_histogram(binwidth = 0.1)
summary(df$alcohol)
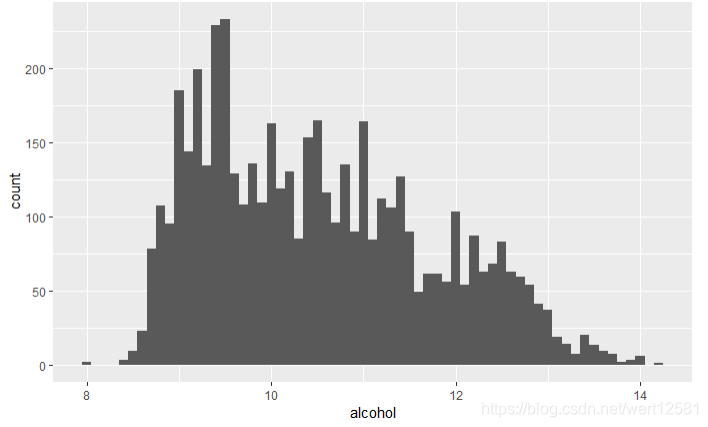
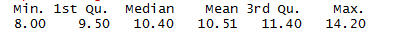
从结果中可以看出,酒精的含量也不是正态分布,但是酒精应该是对于葡萄酒评分的一个重要因素,因此在双变量及多变量分析中进行考察。50%的数据分布在9.5-11.4(volume%)之间,中位数为10.41,平均数为10.51。
质量
# 画出质量分布图
ggplot(aes(x = quality),data = df) +
geom_bar() +
scale_x_continuous(breaks = seq(3,9,1))
summary(df$quality)

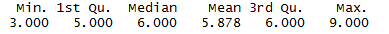
从结果中可以看出,50%的数据分布在5-6之间,因此以此为界,建立一个新的特征,评分,分为好,中,差。
# 新建rating变量,大于等于7时为good,5-6时为common,3-4为bad。并且画出rating的分布图
df$rating <- ifelse(df$quality >= 7, 'good', ifelse(df$quality >= 5, 'common','bad'))
ggplot(aes(x = rating), data = df) +
geom_bar(width = 0.3)
table(df$rating)
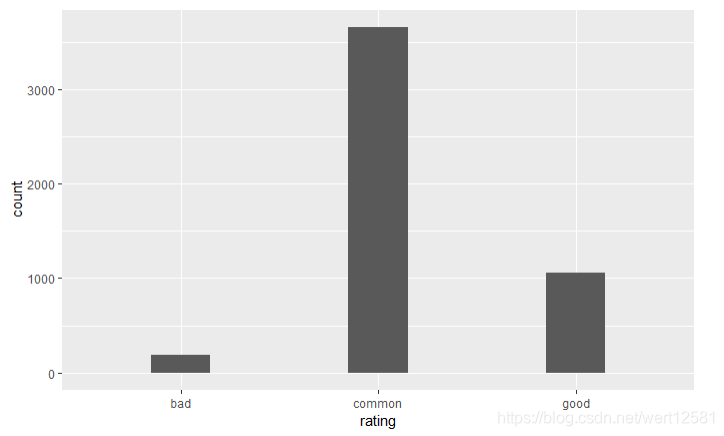

为了之后的数据准备
#由于X这个变量对于分析并没有什么用,因此在之后用于分析的dataframe中将X删除。
#同时,对于quality这个变量来说,它应该是factor,但是目前还是int,因此将它转化成有序factor。
df$quality.order <- factor(df$quality, ordered = TRUE)
df <- subset(df, select = -c(X))
str(df)
单变量分析
你的数据集结构是什么?
数据集中包含了4898条观测数据以及13个特征。这13个特征中X及质量以外的特征都是代表葡萄酒的测量数据,数据类型都是num。而质量中一共包含了3-9之间的整数打分。而X这个类似于编号的特征,并不是葡萄酒的特征,对于后续的分析没有作用。
与葡萄酒酸度有关的变量有:固定酸,挥发酸,柠檬酸,游离二氧化硫,总二氧化硫,硫酸钾,pH。
与葡萄酒甜度有关的变量有:残余糖分。
与葡萄酒咸度有关的变量有:氯化物含量。
其他变量:密度,酒精度。
其他观测结果:
质量在5-7的葡萄酒最多。
这份葡萄酒的数据中的甜度可以被分成两类,干葡萄酒与甜葡萄酒。
大多数变量都大致成正态分布或者在log10的尺度下成类似正态分布。
你的数据集内感兴趣的主要特性有哪些?
我所感兴趣的主要特征是质量,因为其他所有的特征总合起来会影响质量。
你认为数据集内哪些其他特征可以帮助你探索兴趣特点?
首先在单变量分析中发现,有干葡萄酒与甜葡萄酒,专家对于葡萄酒的评分应该以这两个类型为基础来进行的(猜测)。
因此在多变量分析中,可以使用干与甜再加上其他变量来进行分析。
对于其他变量暂时无法进行猜测,不过酒精度对于酒是一个重要的变量,应该对于分析有所帮助。
根据数据集内已有变量,你是否创建了任何新变量?
我创建了二个新的变量。
首先第一个是上面已经提到了的类型:type变量包含sweet与dry。
第二个是将评分根据3-4,5-6,7-9三个分成了三档:rating变量包含bad,common,good。
在已经探究的特性中,是否存在任何异常分布?你是否对数据进行一些操作,如清洁、调整或改变数据的形式?如果是,你为什么会这样做?
在探究中发现残余糖分的分布很不明显,并且基于数值上的差距较大,因此采用log10的标尺重新画了分布图。重新画了分布图后,发现出现了双峰的形式,基于此,对于葡萄酒的类型进行干与甜进行分类。
双变量绘图选择
相关系数矩阵
#画出变量之间的相关系数图
ggcorr(data = subset(df, select = -c(type,rating,quality.order)),
label = TRUE,
label_size = 4,
label_round = 2,
label_alpha = TRUE,
hjust = 0.8,
size = 3,
color = "grey50")
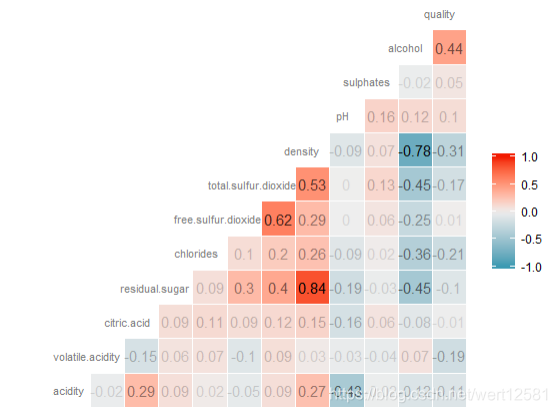
首先从相关系数图中可以发现的相关关系(并且之后准备进行分析的):
与质量有着相对较强关系的:
质量与酒精度有着正相关关系,相关系数0.44(数值上的与质量有关的最大相关系数)。
质量与密度有着负相关关系,相关系数为-0.31。
质量与总二氧化硫含量有着负相关关系,相关系数为-0.17。
质量与氯化物含量有着负相关关系,相关系数为-0.21。
质量与挥发酸含量有着负相关关系,相关系数为-0.19。
其他变量之间的较强关系:
酒精与密度有着负相关关系,相关系数-0.78。
pH与固定酸之间有着负相关关系,相关系数-0.43。
残余糖分与密度有着正相关关系,相关系数0.84。
酒精与氯化物有着负相关关系,相关系数-0.36.
酒精与总二氧化硫有着负相关关系,相关系数-0.45。
质量与酒精度箱形图
# 画出质量与酒精度箱形图
ggplot(aes(x = quality.order, y = alcohol), data = df) +
geom_boxplot() +
xlab('quality')
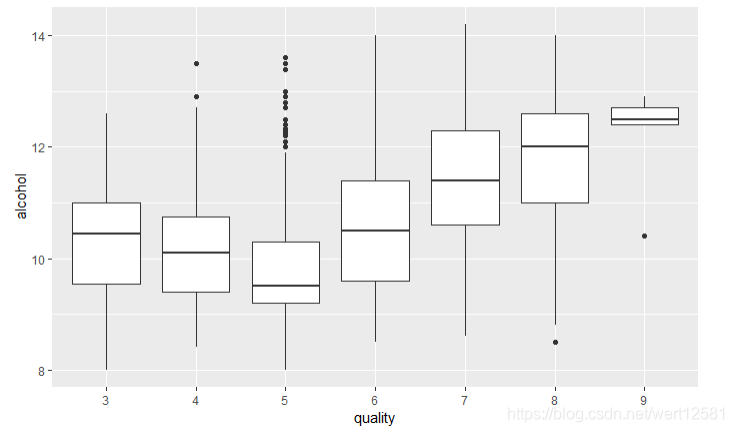
从图中可以看出,3-5的范围内,随着较高评分的酒对应着较低的酒精度。
而从5-9的范围内,较高评分的酒对应着较高的酒精度。
在此图的基础上,将箱形图以好,中,差三个不同的颜色涂色,并且以质量为好的酒的第一四分位数所对应的酒精度,画出一条线。
# 画出质量与酒精度箱形图并且,将箱形图以好,中,差三个不同的颜色涂色,并且以质量为好的酒的第一四分位数所对应的酒精度,画出一条线
ggplot(aes(x = quality.order, y = alcohol), data = df) +
geom_boxplot(alpha = 0.2, aes(fill = rating)) +
geom_hline(yintercept = quantile(subset(df,rating =='good')$alcohol, .25), linetype = 2, color = 'red') +
xlab('quality') +
scale_y_continuous(breaks = seq(8, 14, 1))
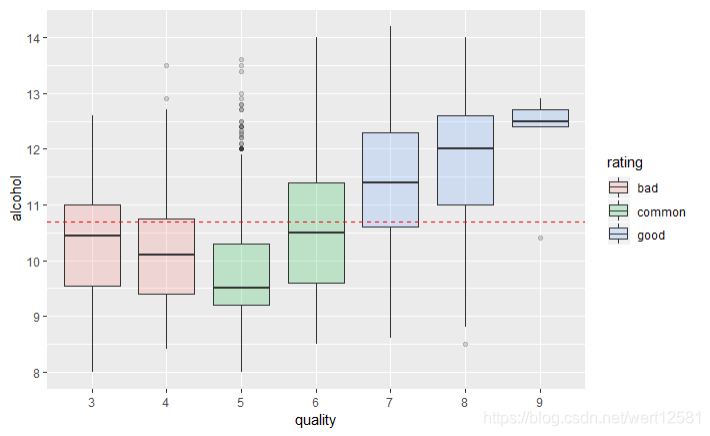
从这副图中可以清楚地看到,很大程度上酒精度的多少决定了酒的质量。不仅仅是因为,酒精度与质量的相关系数为比其他变量与质量的相关系数都要高(0.44),并且,从图中的红线可以看到,75%以上的质量为好的酒拥有10.7以上的酒精度。与此相对,从箱形图可以看出,质量为差的酒的酒精度大部分都低于这个值。
质量与密度含量箱形图
# 画出质量与密度含量箱形图
ggplot(aes(x = quality.order, y = density), data = df) +
geom_boxplot() +
ylim(0.99,1.001) +
xlab('quality')
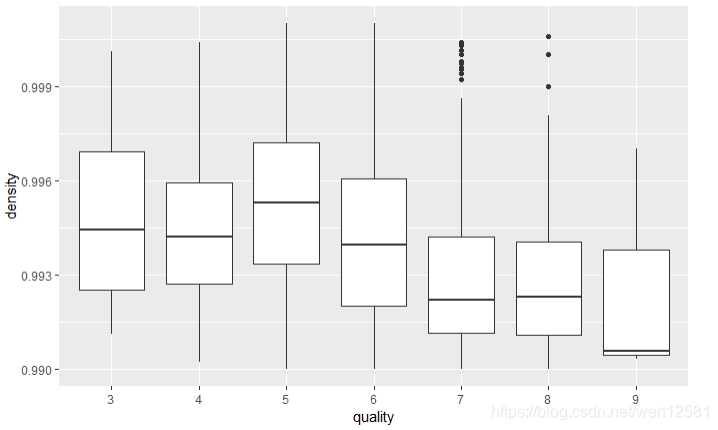
发现了与酒精度相反的趋势。
在3-5的范围内,质量高的酒拥有较高密度。
而在5-9的范围内,质量高的酒拥有拥有较低的密度。
不过由于酒精度与密度由较强的负相关性,相关系数-0.78。
这个结果意料之中。因为,酒精的密度小于水,酒精度越多,自然密度越小。
由于此处探讨了密度与酒精的关系,那么顺着这个思路,画出密度与酒精,密度与残余糖分的散点图,并画出回归线。
# 分别画出质量酒精度,质量残余糖分的散点图,并划出回归曲线
p1 = ggplot(aes(x = alcohol, y = density), data = df) +
geom_point(alpha = 0.1) +
xlim(min(df$alcohol), quantile(df$alcohol, 0.95)) +
ylim(min(df$density), quantile(df$density, 0.95)) +
geom_smooth(method = 'lm', color = 'blue')
p2 = ggplot(aes(x = residual.sugar, y = density), data = df) +
geom_point(alpha = 0.1) +
geom_smooth(method = 'lm', color = 'red') +
xlim(min(df$residual.sugar), quantile(df$residual.sugar, 0.95)) +
ylim(min(df$density), quantile(df$density, 0.95))
grid.arrange(p1, p2, ncol = 2)
cor(df$alcohol, df$density)
cor(df$residual.sugar, df$density)

从这里可以很明显看出酒精度与残余糖分对于密度的影响。
酒精负相关,残余糖分正相关。
酒精的负相关在上面已经解释过了。
而糖分也很明显,糖溶于水后体积基本不变,而质量则会明显增长。因此正相关。
从这里我们可以发现密度几乎就与残余糖分和酒精度有关。这就说明,密度拥有第二高的正相关系数,基本都是因为酒精度的原因。
更加强调了,酒精度对于酒的质量的重要性。
质量与总二氧化硫含量含量箱形图
# 画出质量与总二氧化硫含量含量箱形图
ggplot(aes(x = quality.order, y = total.sulfur.dioxide), data = df) +
geom_boxplot() +
xlab('quality')
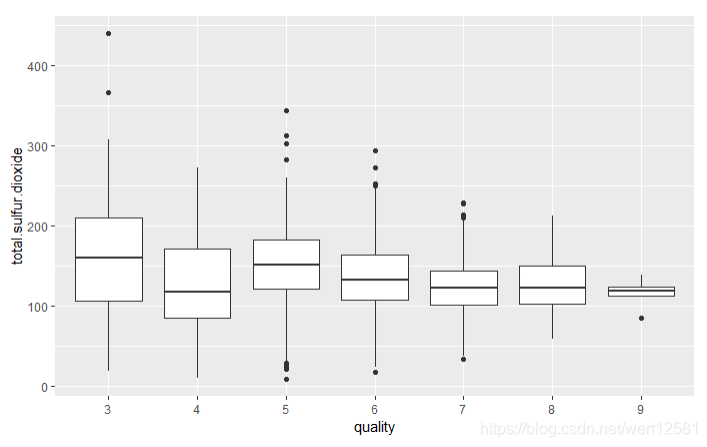
没有发现明显的趋势,质量高的酒所含有的总二氧化硫的量处在一个中间的位置,基本无法说明什么。
氯化物与酒精度箱形图
# 画出氯化物与酒精度箱形图
ggplot(aes(x = quality.order, y = chlorides), data = df) +
geom_boxplot() +
xlab('quality')
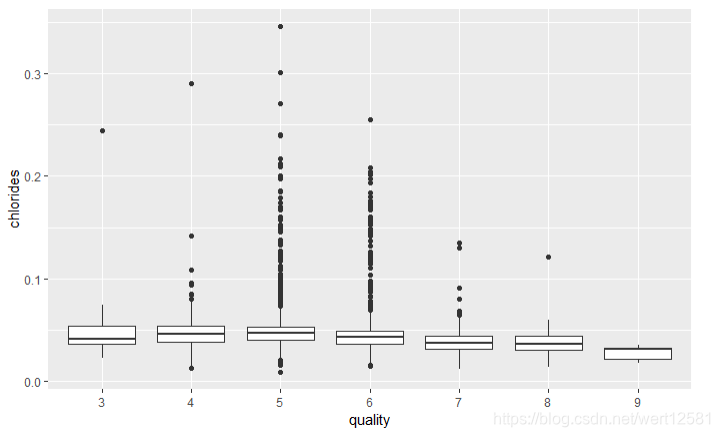
虽然可以看出质量较高的葡萄酒对应着较低的氯化物,不过趋势不是很明显,不是主要因素。
挥发酸与酒精度箱形图
# 画出挥发酸与酒精度箱形图
ggplot(aes(x = quality.order, y = volatile.acidity), data = df) +
geom_boxplot() +
xlab('quality')
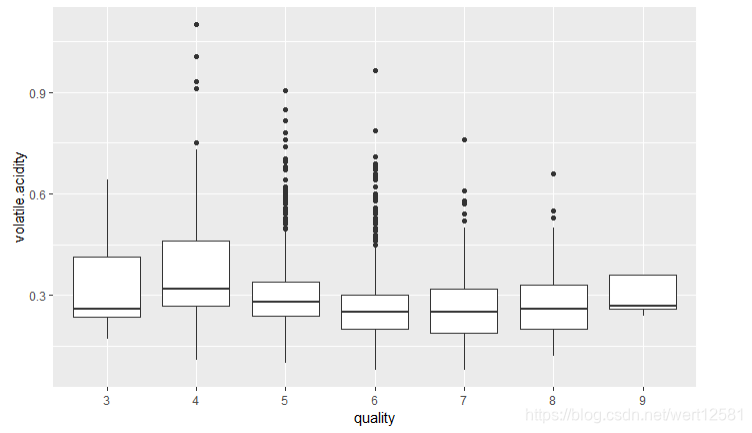
并没有发现什么特别明显的关系,因为根据txt文档所说如果挥发酸含量过高,会发出令人感觉不愉快的气味,这个应该会影响评分。
不过从结果来看,虽然质量较高(7-9)的酒的挥发性酸相比于质量一般和差(4-6)的酒的挥发性酸来说比较少。不过评分最低的3的酒中的挥发性酸含量也不多,说明这不是决定性的因素。
固定酸与pH散点图
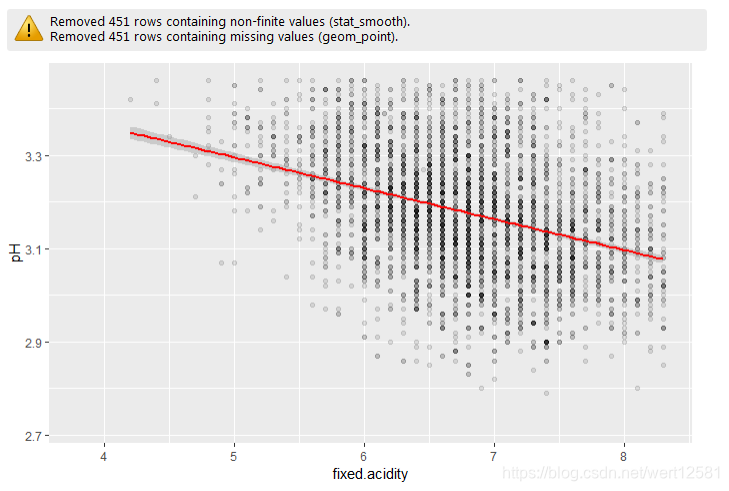
# 画出固定酸与pH散点图,并添加回归曲线
ggplot(aes(x = fixed.acidity, y = pH), data = df) +
geom_point(alpha = 0.1) +
geom_smooth(method = 'lm', color = 'red') +
xlim(min(df$fixed.acidity), quantile(df$fixed.acidity, 0.95)) +
ylim(min(df$pH), quantile(df$pH, 0.95))
cor(df$fixed.acidity, df$pH)
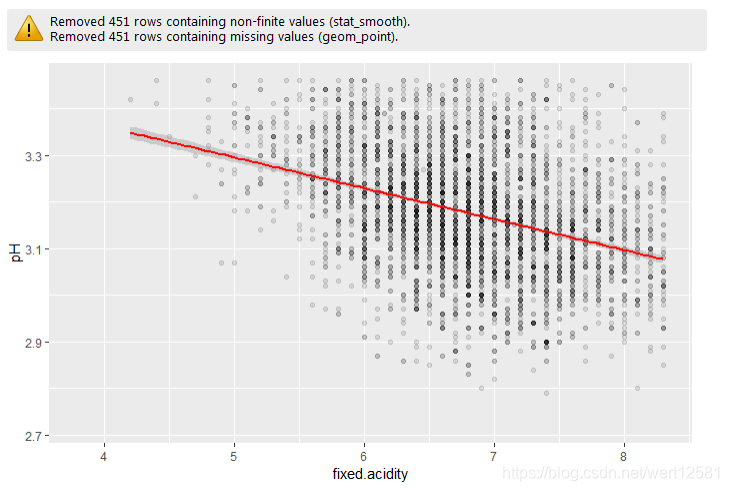
对于固定酸和pH之间的关系进行了散点图绘制,并且添加了回归线,很明显显示出了负相关关系。
氯化物含量与酒精含量散点图
# 画出氯化物含量与酒精含量散点
ggplot(aes(x = chlorides, y = alcohol), data = df) +
geom_point() +
geom_smooth(method = 'lm', color = 'red') +
xlim(min(df$chlorides), quantile(df$chlorides, 0.95))
可以看出,随着氯化物含量的增加酒精的含量酒精度在下降。这个结果很意外,暂时难以解释,能够想得到的原因或许是因为盐分高的葡萄所含的果肉较少?这个以现在的知识和这个数据集难以解释。但是在多变量分析中还是需要看一下,质量等因素的改变,会不会使得这个趋势发生改变。
二氧化硫含量与酒精含量散点图
# 画出氯化物含量与酒精含量散点
ggplot(aes(x = total.sulfur.dioxide, y = alcohol), data = df) +
geom_point() +
geom_smooth(method = 'lm', color = 'red') +
xlim(min(df$total.sulfur.dioxide), quantile(df$total.sulfur.dioxide, 0.95))

可以看出,随着二氧化硫含量的上升,酒精度下降。这有可能是出于防腐目的。因为酒精含量少了,细菌微生物容易滋生,需要添加较多的二氧化硫(个人猜测)。
葡萄酒类型(干,甜)与质量关系图
# 画出葡萄酒类型(干,甜)与质量关系的分布图
ggplot(aes(fill = type, x = quality), data = df)+
geom_bar(position = "dodge")
print('dry')
summary(subset(df, type == 'dry')$quality)
print('sweet')
summary(subset(df, type == 'sweet')$quality)

从图中可以发现,干葡萄酒的质量要高于甜葡萄酒一些,这个原因可能是因为评审的专家偏好干葡萄酒,也很可能是由于前面分析的酒精度的影响。这个具体的原因需要到多变量绘图与分析中解决。
双变量分析
探讨你在这部分探究中观察到的一些关系。这些感兴趣的特性与数据集内其他特性有什么关系?
从相关系数图中可以了解到,感兴趣的特征(质量)与很多变量都没有特别大的相关系数,但是质量与酒精度,密度,总二氧化硫,挥发酸,氯化物之间的相关性较强。
你是否观察到主要特征与其他特性之间的有趣关系?
(这个问题与上一个问题感觉重复了,按照英文版的问题Did you observe any interesting relationships between the other features (not the main feature(s) of interest)?改为回答其他特征之间的关系)
从绘图以及相关系数中发现,密度与酒精度和残余糖分之间有很强的相关性。这是因为,酒精的密度小与水,酒精度越高,酒的密度自然越小。而残余糖分溶解于酒中,但是体积基本不变,只是导致质量的增加。因此残余糖分越多,密度越高。
从氯化物含量与酒精含量中发现了,氯化物含量越多酒精度越低,这是没有想象到的。
你发现最强的关系是什么?
从两个层面来说明这个最强的关系。
1.质量与其他变量之间的最强关系:
质量与酒精度之间的关系,正相关系数达到了0.44。这与之前的猜测很符合,酒精度对酒的质量有很大的影响。
2.其他变量之间的最强关系:
密度与酒精度和残余糖分之间的关系。
密度与酒精度,相关系数-0.78。
密度与残余糖分,相关系数0.84。
多变量绘图选择
在之前的分析中,发现酒精度拥有最强的影响,因此多变量分析中将其中一个特征固定为酒精度来进行分析。
酒精,质量,酒的类型(干与甜)之间的箱形图
# 画出酒精,质量,酒的类型(干与甜)之间的箱形图
ggplot(aes(x = quality.order, y = alcohol), data = df) +
geom_boxplot(aes(color = df$type)) +
xlab('quality')
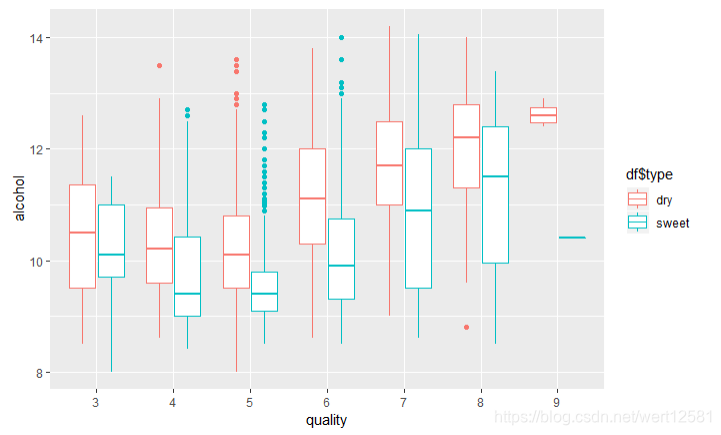
从图中可以发现,双变量最后的分析中,干葡萄酒比甜葡萄酒的总体分数要高的原因,看来不在于干,甜本身,并不是专家的口味有偏好,而是因为干葡萄酒中的酒精的整体含量要高于甜葡萄酒。说明不管是干还是甜,都是主要以酒精度的高低来进行酒的质量的判断。而这个原因有可能是因为,残余糖分多的葡萄酒的发酵相对来说不完全(糖分没有完全转化为酒精),导致的甜葡萄酒普遍酒精度较低。
酒精,质量,总二氧化硫之间的散点图(以甜与干进行了分类)
# 画出酒精,质量,总二氧化硫之间的散点图(以甜与干进行了分类)
p1 = ggplot(aes(x = total.sulfur.dioxide, y = alcohol), data = df) +
geom_jitter(aes(color = rating)) +
scale_color_brewer(type = 'seq',palette = 'PuOr') +
theme_dark() +
facet_wrap(.~type)
p2 = ggplot(aes(x = total.sulfur.dioxide, y = alcohol), data = subset(df, rating != 'common')) +
geom_jitter(aes(color = rating)) +
scale_color_brewer(type = 'seq',palette = 'PuOr') +
theme_dark() +
facet_wrap(.~type)
grid.arrange(p1, p2, ncol = 1)
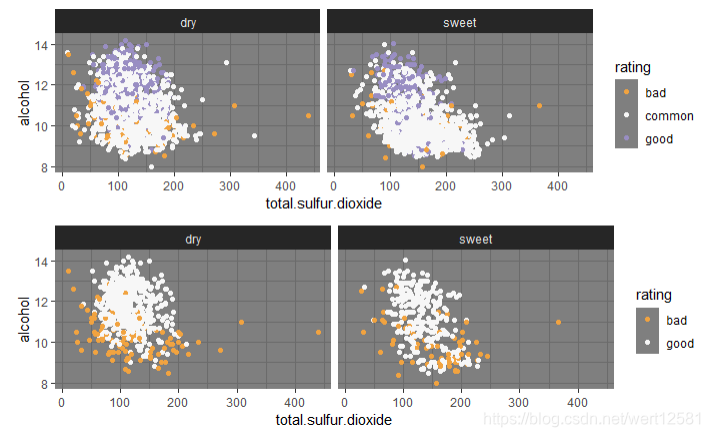
从散点图结果中可以发现,从质量为中等的酒中并没有看到什么特别的倾向。因此单独画了好与坏的酒的散点图。发现,好的酒基本都集中在酒精度高的地方。然后,在干葡萄与甜葡萄酒的对比中,发现干葡萄酒的总二氧化硫含量要低一些。这与整体的趋势也很符合,干葡萄酒的酒精度要比甜葡萄酒高,所以二氧化硫含量低也时符合趋势的。
酒精,质量,氯化物之间的散点图(以甜与干进行了分类)
# 画出酒精,质量,氯化物之间的散点图(以甜与干进行了分类)
p1 = ggplot(aes(x = chlorides, y = alcohol), data = df) +
geom_jitter(aes(color = rating)) +
xlim(min(df$chlorides), quantile(df$chlorides, 0.95)) +
scale_color_brewer(type = 'seq',palette = 'PuOr') +
theme_dark() +
facet_wrap(.~type)
p2 = ggplot(aes(x = chlorides, y = alcohol), data = subset(df, rating != 'common')) +
geom_jitter(aes(color = rating)) +
xlim(min(df$chlorides), quantile(df$chlorides, 0.95)) +
scale_color_brewer(type = 'seq',palette = 'PuOr') +
theme_dark() +
facet_wrap(.~type)
grid.arrange(p1, p2, ncol = 1)
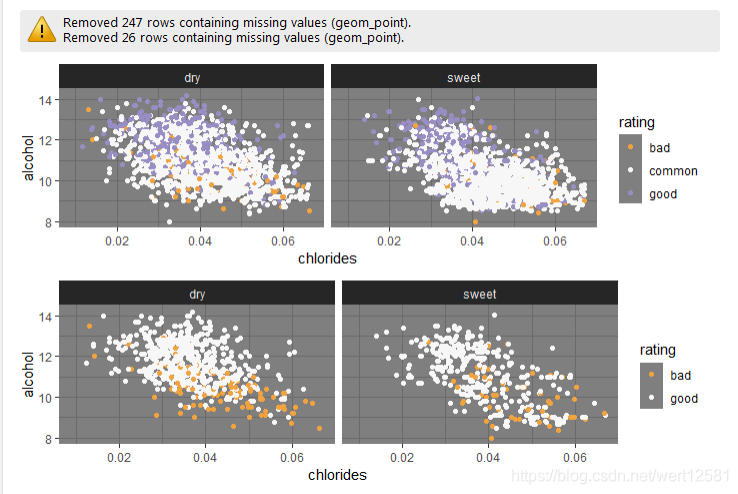
可以发现,不论是质量该还是质量低,不论是干还是甜,都大致拥有,酒精度与氯化物成负相关关系的趋势,说明这个趋势是一个普遍的趋势,与品质,种类没有特别大的关系。并且,酒精含量依然是决定好坏的主要因素。因为不管质量好差,氯化物的分布都比较广,但是好的酒都主要集中在酒精度高的地方。
多变量分析
探讨你在这部分探究中观察到的一些关系。通过观察感兴趣的特性,是否存在相互促进的特性?
1.专家对于干葡萄酒与甜葡萄酒之间并没有什么偏好,主要是根据酒精度的多少进行判断。
2.多个变量似乎不对于评分有什么主要的综合影响,主要的影响因素还是酒精度。
这些特性之间是否存在有趣或惊人的联系呢?
1.发现了,干葡萄酒的酒精度普遍较高,甜葡萄酒的酒精度相对来说低一些,这导致了干葡萄酒的总体评分高一些。而这个原因有可能是甜葡萄酒中的糖分没有发酵较不完全导致的。
2.虽然有很多特征,不过最终决定就的评分高低的还是酒精度。
3.酒精度与总二氧化硫量成反比。由于二氧化硫是添加的,因此这个反比的原因,有可能是酒精度低的酒更加需要防腐。
4.酒精度与氯化物含量成反比。这个原因以个人知识和数据集暂时无法解答,非常令我意外。
选项:你是否创建过数据集的任何模型?讨论你模型的优缺点。
无
定稿图与总结
绘图一
# 选取了质量的分布图,用theme_update(plot.title = element_text(hjust = 0.5))进行的title居中
theme_update(plot.title = element_text(hjust = 0.5))
ggplot(aes(x = quality), data = df) +
geom_bar(aes(y = (..count..)/sum(..count..))) +
scale_x_continuous(breaks = seq(3, 9, 1)) +
scale_y_continuous(labels = scales::percent) +
labs(x = 'quality of white wine',
y = 'percent of samples',
title = 'Distribution of quality')
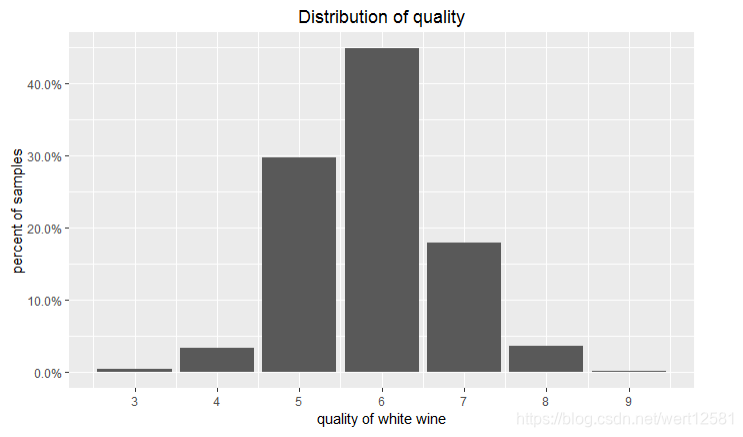
描述一
从白葡萄酒质量的分布图中可以发现,质量处在中间的5-6的葡萄酒占了大多数,按照y轴来计算,大约占了全部的75%。这样说明这个样本是有偏的,这也暗示了,我们从这份数据中得到的分析结果比较有局限性。
绘图二
# 选取了质量与酒精度箱形图并且,将箱形图以好,中,差三个不同的颜色涂色,并且以质量为好的酒的第一四分位数所对应的酒精度,画出一条线
ggplot(aes(x = quality.order, y = alcohol), data = df) +
geom_boxplot(alpha = 0.2, aes(fill = rating)) +
geom_hline(yintercept = quantile(subset(df,rating =='good')$alcohol, .25), linetype = 2, color = 'red') +
labs(x = 'quality of white wine',
y = 'alcohol(vol%)',
title = 'Relationship between alcohol and quality') +
scale_y_continuous(breaks = seq(8, 14, 1))
by(df$alcohol, df$rating, summary)
cor(df$quality, df[,2:11])

描述二
从中可以发现,很大程度上酒精度的多少决定了酒的质量。不仅仅是因为,酒精度与质量的相关系数为比其他变量与质量的相关系数都要高(0.44),并且,从图中的红线可以看到,75%以上的质量为好的酒拥有10.7以上的酒精度。与此相对,从箱形图可以看出,接近于75%的质量为差的酒的酒精度都低于这个值。
绘图三
# 选取了质量与type的分布图和酒精,质量,挥发酸之间的散点图(以甜与干进行了分类)这两幅图。并在最下面显示了两者的酒的总数
p1 = ggplot(aes(fill = type, x = quality), data = df)+
geom_bar(position = "dodge") +
xlab('quality of white wine') +
ylab('number of wine') +
ggtitle('boxplot of quaity vs type')
type_of_wine <- df$type
p2 = ggplot(aes(x = quality.order, y = alcohol), data = df) +
geom_boxplot(aes(color = type_of_wine)) +
xlab('quality of white wine') +
ylab('alcohol(vol%)') +
ggtitle('boxplot of alcohol vs quality group by type')
grid.arrange(p1, p2, ncol = 1)
table(df$type)
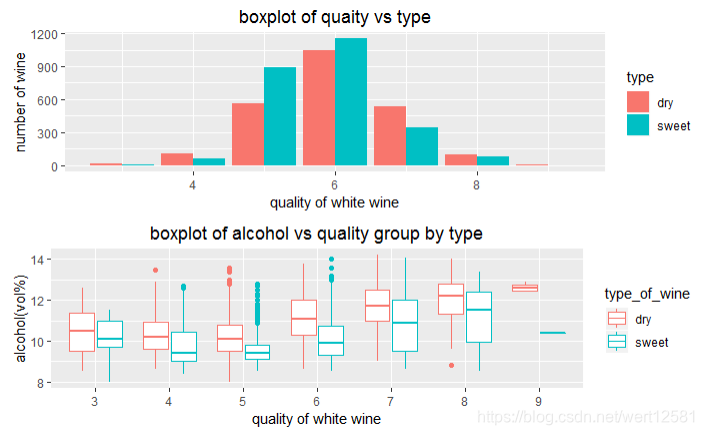
描述三
从上面的图中可以发现,干葡萄酒的数量与甜葡萄酒的数量类似(稍微少一些),但是,从分布图中可以发现,干葡萄酒的分布在高质量处要多于甜葡萄酒。这说明,整体的质量较高干葡萄酒的质量要高于甜葡萄酒一些,这个原因可能是因为评审的专家偏好干葡萄酒,也很可能是由于前面分析的酒精度的影响。而结合下面的图之后可以发现,干葡萄酒比甜葡萄酒的总体分数要高的原因,看来不在于干,甜本身,并不是专家的口味有偏好,而是因为干葡萄酒中的酒精的整体含量要高于甜葡萄酒。说明不管是干还是甜,都是主要以酒精度的高低来进行酒的质量的判断。而这个原因有可能是因为,残余糖分多的葡萄酒的发酵相对来说不完全(糖分没有完全转化为酒精),导致的甜葡萄酒普遍酒精度较低。
反思
这一次白葡萄酒的EDA中我学到了很多知识。 首先是EDA的整体流程,要从简单的地方入手,寻找规律,从已经找到的规律中继续出发,进行双变量以及多变量的分析。这样循序渐进的过程,能够帮助我更好的了解数据集,这样才能够做更好的分析。
其次对于ggplot以及相关的包的学习方法。我对于这些包中的很多知识都是通过stackoverflow以及官方文档中找到的,这是以后学习中需要坚持的,从网上的资源找到合适的答案是数据分析师和程序员都必须具备的知识。
第三,整个探索过程中,遇到了很多问题,特别是一开始想要主观去判断,觉得用主观就能够解决很多问题,于是直接进行双变量分析,但是马上发现寸步难行,这就是第一点所说的,对于数据集压根就不熟悉,于是没法深入探索。
第四,在调整了思路后首先,从单变量分析中了解数据的大体规模与范围,这样进入第二阶段的双变量分析和多变量分析就不会犯很容易发生的错误。比如之前我在多变量分析中,发现了柠檬酸含量在0.25-0.5的范围中的时候才能有好的酒。可是后来察看柠檬酸的含量的时候发现,柠檬酸的含量本来就在这个范围之中。我的结论毫无用处。若是我了解了数据集,就不会出现这个问题。
第五,了解了行业知识对于数据分析是多么重要。若是我熟悉葡萄酒的重要变量,或许我能够得到更深层次的结论。
参考资料
stackoverflow
ggplot2官方文档
https://dzchilds.github.io/eda-for-bio/