诊断内存的消耗
判断spark程序消耗了多少内存
- 首先,自己设置RDD的并行度,有两种方式:要不然,在parallelize()、textFile()等方法中,传入第二个参数,设置RDD的task / partition的数量;要不然,用SparkConf.set()方法,设置一个参数,
spark.default.parallelism,可以统一设置这个application所有RDD的partition数量。 - 其次,在程序中将RDD cache到内存中,调用RDD.cache()方法即可。
- 最后,观察Driver的Log,你会发现类似于:“INFO BlockManagerMasterActor: Added rdd_0_1 in memory on mbk.local:50311 (size: 717.5 KB, free: 332.3 MB)”的日志信息。这就显示了每个partition占用了多少内存。
- 将这个内存信息乘以partition数量,即可得出RDD的内存占用量。
spark.default.parallelism
- 参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
- 参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
高性能序列化类库
Spark自身对于序列化的便捷性和性能进行了一个取舍和权衡。默认,Spark倾向于序列化的便捷性,使用了Java自身提供的序列化机制——基于ObjectInputStream和ObjectOutputStream的序列化机制。因为这种方式是Java原生提供的,很方便使用。
- 分发给Executor上的Task
- 需要缓存的RDD(前提是使用序列化方式缓存)
- 广播变量
- Shuffle过程中的数据缓存
- 使用receiver方式接收的流数据缓存
- 算子函数中使用的外部变量
以上的六种数据,通过Java序列化(默认的序列化方式)形成一个二进制字节数组,大大减少了数据在内存、硬盘中占用的空间,减少了网络数据传输的开销,并且可以精确的推测内存使用情况,降低GC频率。
其好处很多,但是缺陷也很明显:把数据序列化为字节数组、把字节数组反序列化为对象的操作,是会消耗CPU、延长作业时间的,从而降低了Spark的性能.。少默认的Java序列化方式在这方面是不尽如人意的。Java序列化很灵活但性能较差,同时序列化后占用的字节数也较多。
所以官方也推荐尽量使用Kryo的序列化库(版本2)。官文介绍,Kryo序列化机制比Java序列化机制性能提高10倍左右,Spark之所以没有默认使用Kryo作为序列化类库,是因为它不支持所有对象的序列化,同时Kryo需要用户在使用前注册需要序列化的类型,不够方便。
/**
* Helper method to create a SparkEnv for a driver or an executor.
*/
private def create(
conf: SparkConf,
executorId: String,
bindAddress: String,
advertiseAddress: String,
port: Option[Int],
isLocal: Boolean,
numUsableCores: Int,
ioEncryptionKey: Option[Array[Byte]],
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {
val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER
......
val serializer = instantiateClassFromConf[Serializer](
"spark.serializer", "org.apache.spark.serializer.JavaSerializer")
logDebug(s"Using serializer: ${serializer.getClass}")
val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey)
//Task闭包函数使用Java序列化库
val closureSerializer = new JavaSerializer(conf)
......
}
针对下面这五种数据类型来切换到Kryo序列化库
- 需要缓存的RDD(前提是使用序列化方式缓存)
- 广播变量
- Shuffle过程中的数据缓存
- 使用receiver方式接收的流数据缓存
- 算子函数中使用的外部变量
其实从Spark 2.0.0版本开始,简单类型、简单类型数组、字符串类型的Shuffling RDDs 已经默认使用Kryo序列化方式了。
// SPARK-18617: As feature in SPARK-13990 can not be applied to Spark Streaming now. The worst
// result is streaming job based on `Receiver` mode can not run on Spark 2.x properly. It may be
// a rational choice to close `kryo auto pick` feature for streaming in the first step.
def getSerializer(ct: ClassTag[_], autoPick: Boolean): Serializer = {
// 校验keyClass、valueClass是否可以使用kryo
if (autoPick && canUseKryo(ct)) {
kryoSerializer
} else {
defaultSerializer
}
}
Kryo序列化机制
使用Kryo序列化机制,首先要用SparkConf设置一个参数,使用new SparkConf().set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")即可,即将Spark的序列化器设置为KryoSerializer。这样,Spark在内部的一些操作,比如Shuffle,进行序列化时,就会使用Kryo类库进行高性能、快速、更低内存占用量的序列化了
public class JavaKryoSerializer {
static class Words implements java.io.Serializable {
private static final long serialVersionUID = -1L;
public String[] line;
public Words() {
}
public Words(String[] line) {
super();
this.line = line;
}
}
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("JavaKryoSerializer").setMaster("local");
// 第一步: 使用Kryo序列化库
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
// 第二步:注册用户定义的类型
conf.set("spark.kryo.registrator", ToKryoRegistrator.class.getName());
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("spark.txt");
JavaRDD<Words> words = lines.flatMap(new FlatMapFunction<String, Words>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<Words> call(String line) throws Exception {
return Arrays.asList(new Words(line.split(" "))).iterator();
}
});
// 将RDD以序列化的形式缓存在内存中,因为其元素是words对象,所以使用Kryo的序列化方式缓存
words.persist(StorageLevel.MEMORY_ONLY_SER());
System.out.println(words.count());
sc.close();
}
public static class ToKryoRegistrator implements KryoRegistrator {
// 第三步:自定义类中实现KryoRegistrator接口的registerClasses方法
@Override
public void registerClasses(Kryo kryo) {
// 在Kryo序列化库中注册自定义的类
kryo.register(Words.class);
}
}
}
使用默认的Java序列化库的情况

使用Kryo序列化库的情况

Kryo序列化库主要参数
| Property Name | Default | Meaning |
|---|---|---|
| spark.serializer | rg.apache.spark. serializer.JavaSerializer | 序列化时用的类,需要申明为org.apache.spark.serializer.KryoSerializer。这个设置不仅控制各个worker节点之间的混洗数据序列化格式,同时还控制RDD存到磁盘上的序列化格式及广播变量的序列化格式。 |
| spark.kryo.registrator | (none) | 为Kryo设置这个类去注册你自定义的类。最后,如果你不注册需要序列化的自定义类型,Kryo也能工作,不过每一个对象实例的序列化结果都会包含一份完整的类名,浪费空间 |
| spark.kryo.classesToRegister | (none) | 如果您使用Kryo序列化,请给出一个以逗号分隔的自定义类名称list列表,以向Kryo注册。 |
| spark.kryo.referenceTracking | true | 跟踪对同一个对象的引用情况,这对发现有循环引用或同一对象有多个副本的情况是很有用的。设置为false可以提高性能 |
| spark.kryo.registrationRequired | false | 是否需要在Kryo登记注册?如果为true,则序列化一个未注册的类时会抛出异常 |
| spark.kryo.unsafe | false | 是否使用基于不安全的Kryo序列化器。使用不安全的IO可以大大加快速度。 |
| spark.kryoserializer.buffer.max | 64m | 允许使用序列化buffer的最大值 |
| spark.kryoserializer.buffer | 64k | 每个Executor中的每个core对应着一个序列化buffer。如果你的对象很大,可能需要增大该配置项。其值不能超过spark.kryoserializer.buffer.max |
参考地址:http://spark.apache.org/docs/latest/configuration.html
优化Kryo类库的使用
-
优化缓存大小
如果注册的要序列化的自定义的类型,本身特别大,比如包含了超过100个field。那么就会导致要序列化的对象过大。此时就需要对Kryo本身进行优化。因为Kryo内部的缓存可能不够存放那么大的class对象。此时就需要调用SparkConf.set()方法,设置spark.kryoserializer.buffer.mb参数的值,将其调大。默认情况下它的值是2,就是说最大能缓存2M的对象,然后进行序列化。可以在必要时将其调大。比如设置为10。
-
预先注册自定义类型
虽然不注册自定义类型,Kryo类库也能正常工作,但是那样的话,对于它要序列化的每个对象,都会保存一份它的全限定类名。此时反而会耗费大量内存。因此通常都建议预先注册号要序列化的自定义的类。
拓展RDD的压缩
如果想进一步的节省内存、硬盘的空间,减少网络传输的数据量,可以配合的使用Spark支持的压缩方式(目前默认是lz4),广播变量、shuffle过程中的数据都默认使用压缩功能。(注意,RDD默认是不压缩的)
| Property Name | Default | Meaning |
|---|---|---|
| spark.io.compression.codec | lz4 | 压缩用于压缩内部数据,如RDD分区、事件日志、广播变量和shuffle输出。默认情况下,Spark提供三个压缩方式:lz4、lzf和snappy。您还可以使用完全限定的类名来指定编解码器。org.apache.spark.io.LZ4CompressionCodec, org.apache.spark.io.LZFCompressionCodec, org.apache.spark.io.SnappyCompressionCodec. |
| spark.broadcast.compress | true | 是否在发送之前压缩广播变量。默认压缩 |
| spark.shuffle.compress | true | shuffle中map的输出文件默认是压缩的 |
| spark.shuffle.spill.compress | true | 在shuffles中的切片数据默认是压缩的 |
| spark.rdd.compress | false | 是否压缩序列化的RDD分区数据,可以节省大量的空间以节省额外的CPU时间【默认不压缩】 (例如:在Java和scala中的StorageLevel.MEMORY_ONLY_SER 或者 在Python中的StorageLevel.MEMORY_ONLY) |
RDD持久化操作时使用压缩机制(注意,只有序列化后的RDD才能使用压缩机制)
conf.set("spark.rdd.compress", "true");

不过使用压缩机制,也会增加额外的开销,也会影响到性能
优化数据结构
要减少内存的消耗,除了使用高效的序列化库以外,还有一个很重要的事情,就是优化数据结构。从而避免Java语法特性中所导致的额外内存的开销,比如基于Java数据结构,以及包装类型。
- 优先使用数组以及字符串,而不是集合类。也就是说,优先用array,而不是ArrayList、LinkedList、HashMap等集合
- 避免使用多层嵌套的对象结构。比如说,
public class Teacher { private List<Student> students = new ArrayList<Student>() }。就是非常不好的例子。因为Teacher类的内部又嵌套了大量的小Student对象。用JSON字符串来存储数据,就是一个很好的选择。 - 对于有些能够避免的场景,尽量使用int替代String。因为String虽然比ArrayList、HashMap等数据结构高效多了,占用内存量少多了,但是之前分析过,还是有额外信息的消耗。比如之前用String表示id,那么现在完全可以用数字类型的int,来进行替代
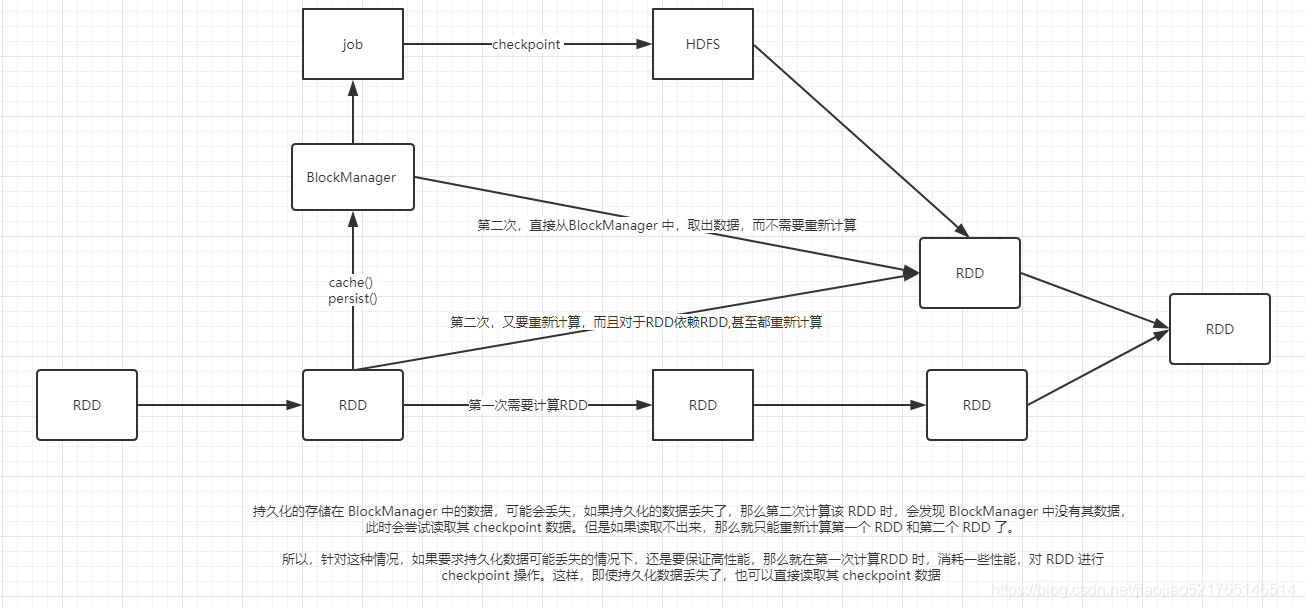
对多次使用的RDD进行持久化或Checkpoint
对某一个RDD,基于它进行了多次transformation或者action操作。那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算。此外,如果要保证在RDD的持久化数据可能丢失的情况下,还要保证高性能,那么可以对RDD进行Checkpoint操作。
提高并行度
实际上Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源。才能充分提高Spark应用程序的性能.
Spark会自动设置以文件作为输入源的RDD的并行度,依据其大小,比如HDFS,就会给每一个block创建一个partition,也依据这个设置并行度。对于reduceByKey等会发生shuffle的操作,就使用并行度最大的父RDD的并行度即可。
可以手动使用textFile()、parallelize()等方法的第二个参数来设置并行度;也可以使用spark.default.parallelism参数,来设置统一的并行度。Spark官方的推荐是,设置集群总cpu数量的两倍~ 三倍的并行度,给集群中的每个cpu core设置2~3个task。
spark-submit设置了executor数量是10个,每个executor要求分配2个core,那么application总共会有20个core。此时可以设置new SparkConf().set("spark.default.parallelism", "60")来设置合理的并行度,从而充分利用资源。
广播共享数据
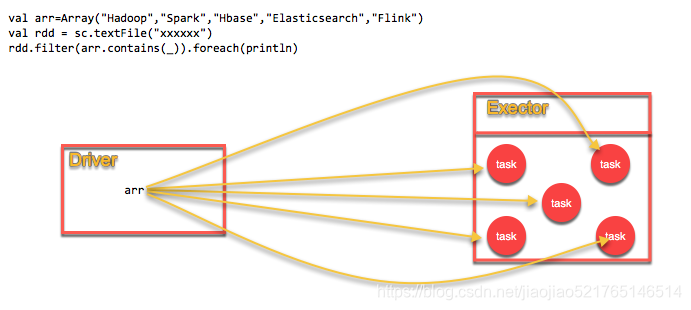
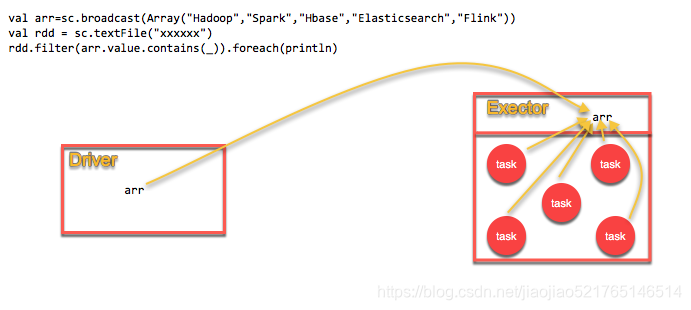
如果你的算子函数中,使用到了特别大的数据,那么,这个时候,推荐将该数据进行广播。这样的话,就不至于将一个大数据拷贝到每一个task上去。而是给每个节点拷贝一份,然后节点上的task共享该数据。这样的话,就可以减少大数据在节点上的内存消耗。并且可以减少数据到节点的网络传输消耗。
不使用广播变量
使用广播变量
广播变量使用
val lookupCache=sc.broadcast(
Map(111->"class1",112->"class1",113->"class2")
)
数据本地化
数据本地化可以对Spark任务的性能产生重大影响。如果数据和操作数据的代码在一块,计算通常会很快。但是如果数据和代码不在一起,就必须将一方移动到另一方。通常,将序列化的代码块从一个地方发送到另一个地方要比发送数据更快,因为代码的大小比数据要小得多(这也是大数据计算核心思想之一:计算向数据移动)。Spark基于这个数据本地化的原则构建task的调度算法。
数据本地化是指数据与运行代码之间的距离。根据数据的当前位置,有几个本地化级别。从近到远:
- PROCESS_LOCAL 数据位于与运行代码相同的JVM中。这是最好的地方。
- NODE_LOCAL 数据位于同一节点上。示例:可能在同一个节点上的HDFS中,或者在同一个节点上的另一个executor中。这比PROCESS_LOCAL稍微慢一些,因为数据必须在进程之间来回移动
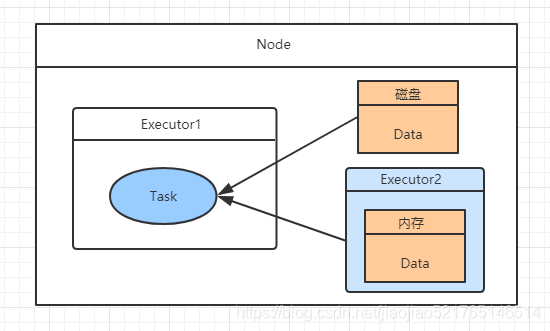
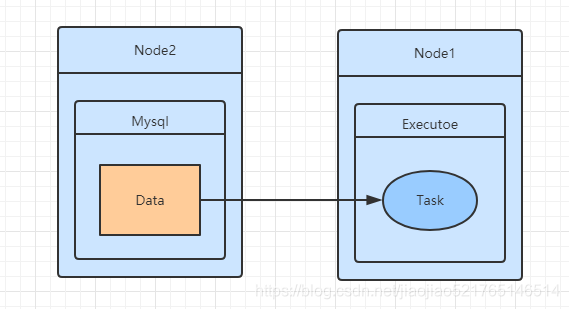
- NO_PREF 数据在任何地方都可以同样快速地访问,并且没有本地偏好。
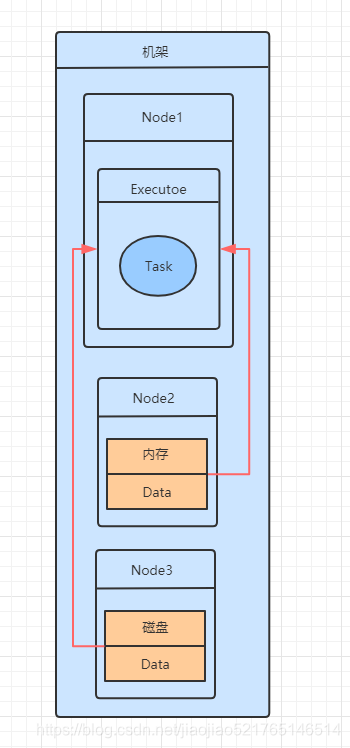
- RACK_LOCAL 数据位于同一台服务器上。数据在同一机架上的不同服务器上,所以需要通过网络发送,通常是通过一个交换机。
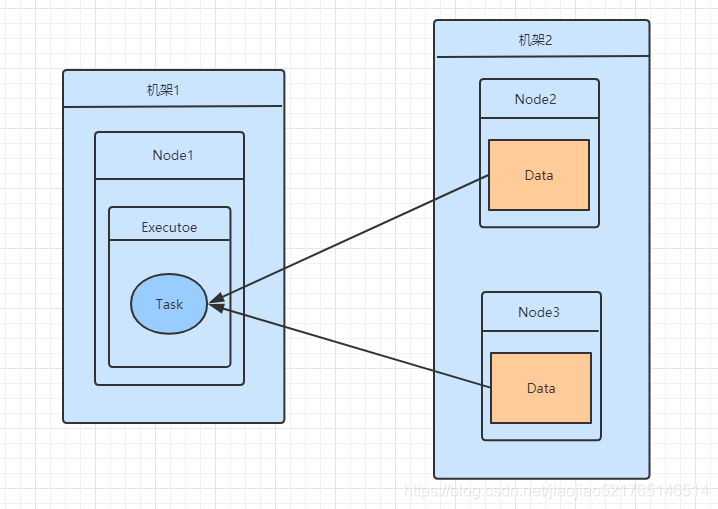
- ANAY 数据在网络上的其他地方,而不是在同一个机架上。
原理
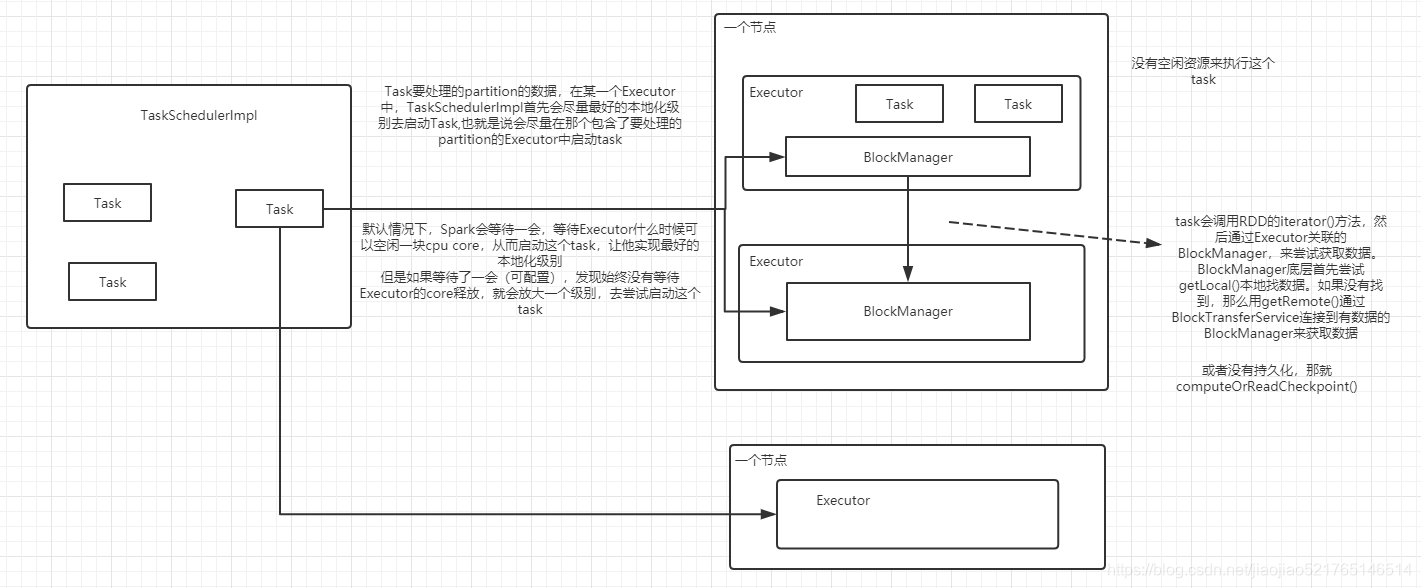
Driver端的TaskScheduler在分发任务前,都会通过MapOutputTracker查询Task任务所需数据的位置信息,优先将Task发送到资源充足且数据所在节点的Executor的线程池中。Task在线程池中排队等待执行,如果等待时间超过3s(默认值,可能更长),重试5次,依然无法执行的话,TaskScheduler就认为这个节点没有计算能力(即资源被其他任务占完了)。TaskScheduler会降低数据本地化级别,将Task按照NODE_LOCAL重新发送,如果还无法执行,就继续降低数据本地化级别。
如何调节数据本地化级别
通过改变数据本地化级别之间的超时等待时间。Spark官网对相关配置项有详细的介绍。
- spark.locality.wait 默认3s
- spark.locality.wait.process 默认与spark.locality.wait保持一致,可以单独指定
- spark.locality.wait.node 默认与spark.locality.wait保持一致,可以单独指定
- spark.locality.wait.rack 默认与spark.locality.wait保持一致,可以单独指定
修改的等待时间不能太长,因为时间太长,虽然每个Task的本地化级别提高了,但是整个Application的执行时间会由于等待时间过长而大大加长,从而失去了调节本地化级别的意义。
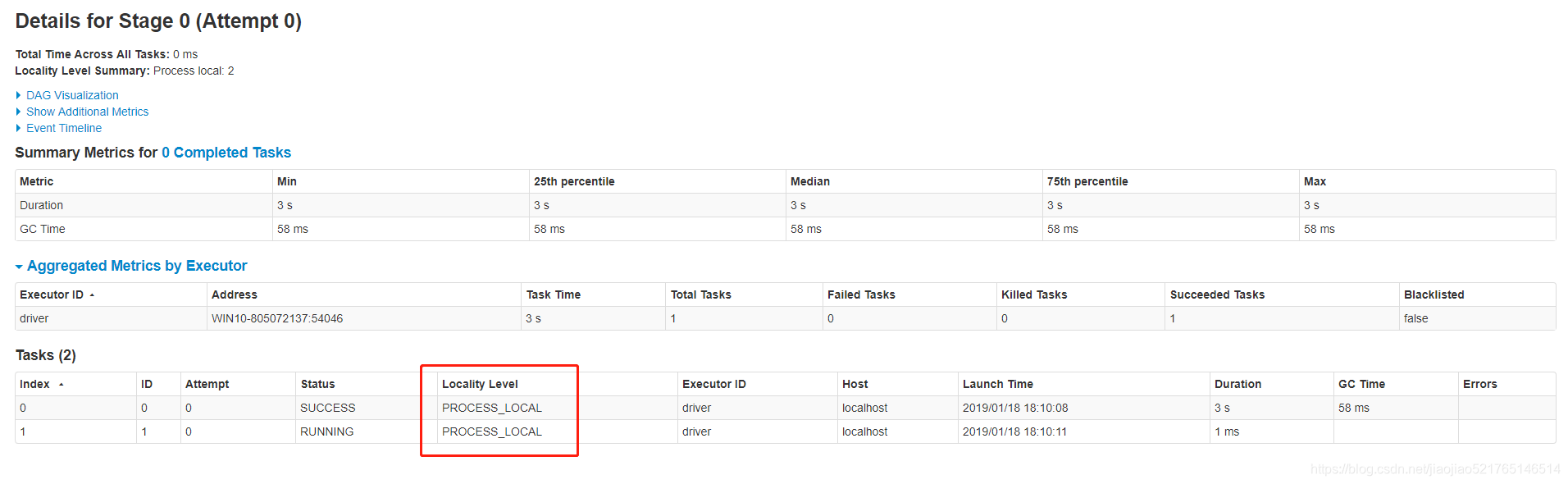
查看本地化级别
- 通过Task日志查看
- Web UI界面找到对应的任务,进入任务的明细界面
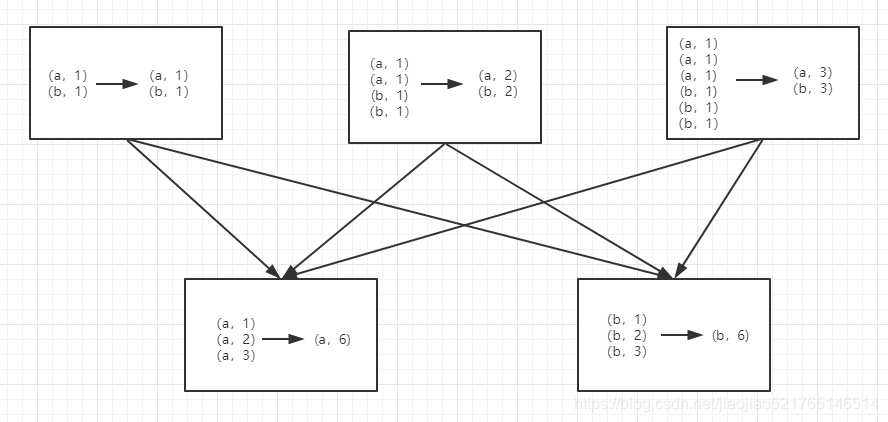
reduceByKey和groupByKey
reduceByKey(func, numPartitions=None)
reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
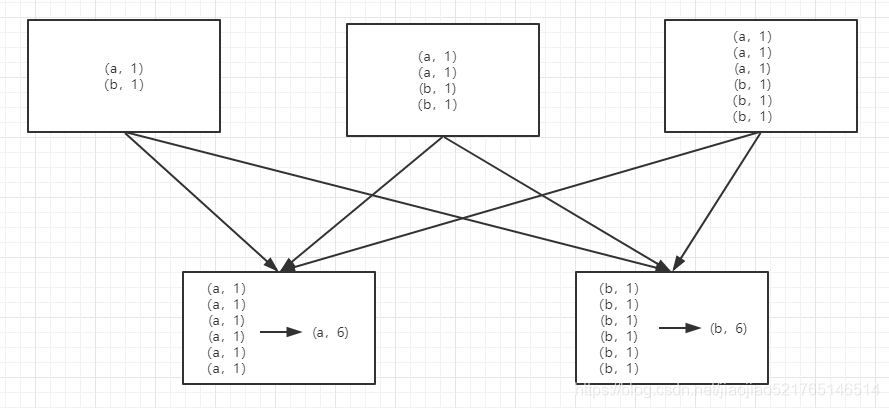
groupByKey(numPartitions=None)
groupByKey也是对每个key进行操作,但只生成一个sequence。需要特别注意“Note”中的话,它告诉我们:如果需要对sequence进行aggregation操作(注意,groupByKey本身不能自定义操作函数),那么,选择reduceByKey/aggregateByKey更好。这是因为groupByKey不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
在进行大量数据的reduce操作时候建议使用reduceByKey。不仅可以提高速度,还是可以防止使用groupByKey造成的内存溢出问题
在对大数据进行复杂计算时,reduceByKey优于groupByKey。