1.创建对应的工作目录/usr/ywq/hadoop,并解压hadoop到相应的目录:

2.配置环境变量
export JAVA_HOME=/usr/local/ywq/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:${HADOOP_HOME}/lib
export M2_HOME=/usr/local/ywq/apache-maven-3.5.4
export PATH=${JAVA_HOME}/bin:${M2_HOME}/bin:$PATH:${ZOOKEEPER_HOME}/bin:${HADOOP_HOME}/bin
export ZOOKEEPER_HOME=/usr/ywq/zookeeper/zookeeper-3.5.4-beta
export HADOOP_HOME=/usr/ywq/hadoop/hadoop-2.7.3使用以下命令使 profile 生效:
source /etc/profile
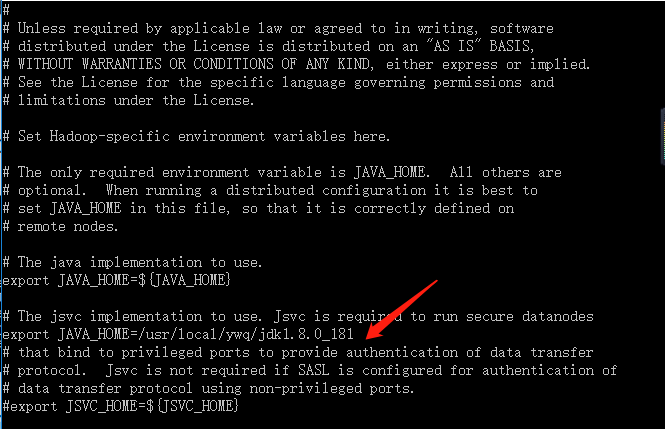
3.编辑 hadoop 环境配置文件 hadoop-env.s
输入内容:export JAVA_HOME=/usr/java/jdk1.8.0_171

4.修改core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/ywq/hadoop/hadoop-2.7.3/hdfs/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
</configuration>5.yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>6.编写slaves文件

7.编写master文件
![]()
8.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/ywq/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>9.marped-site.xml
首先将模板文件复制为 xml 文件,对其进行编辑:

<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>10.分发hadoop:
scp -r /usr/ywq/hadoop root@slave1:/usr/ywq
scp -r /usr/ywq/hadoop root@slave2:/usr/ywq
注意:slave 节点上还需要配置环境变量,参考 第二个步骤
11.master 中格式化 hadoop
./hadoop namenode -format (或者bin/hdfs namenode -format(注意目录))

12.各节点进行如下
master:
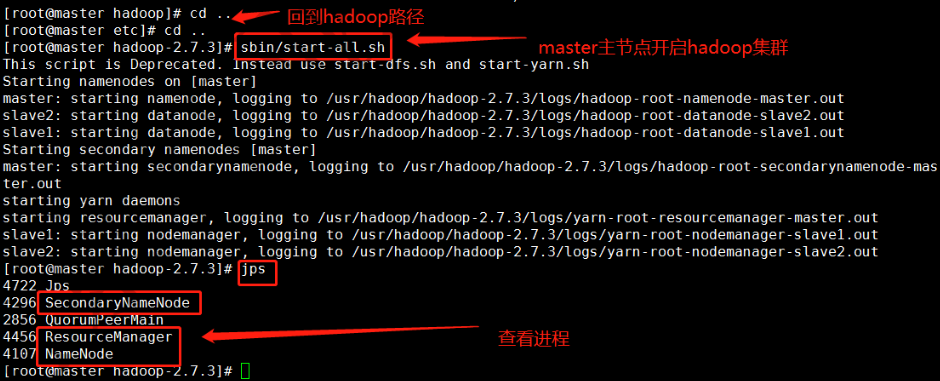
slave1:

slave2:

13.在浏览器中访问主节点 master:50070(50070 是 hdfs 的 web 管理页面)
注意,如果发现集群已启动,但是访问不了,可能是防火墙没有关闭。

在本地浏览器里访问如下地址:
自动跳转到了cluster页面

14.查看hdfs

bin/hdfs dfs -ls / 在最开始的是一个空的文件系统所以什么也没有
bin/hdfs dfs -mkdir /a 在hdfs 上传到 a 文件夹