SparkStreaming介绍
概述

Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数
据的能力,以吞吐量高和容错能力强著称。

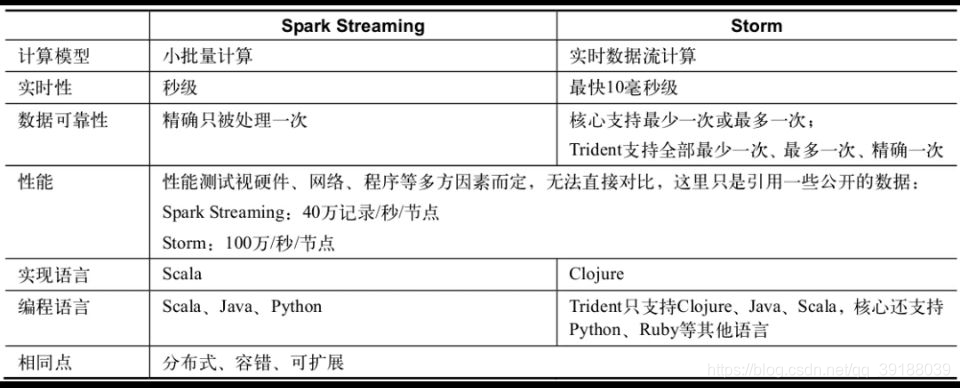
SparkStreaming VS Storm
大体上两者非常接近,而且都处于快速迭代过程中,即便一时的对比可能某一方占优势。
在Spark老版本中,SparkStreaming的延迟级别达到秒级,而Storm可以达到毫秒级别。而
在最新的2.0版本之后,SparkStreaming能够达到毫秒级。
但后者可能很快就追赶上来。比如在性能方面,Spark Streaming刚发布不久,有基准测试显
示性能超过Storm几十倍,原因是Spark Streaming采用了小批量模式,而Storm是一条消息
一条消息地计算。但后来Storm也推出了称为Trident的小批量计算模式,性能应该不是差距
了。而且双方都在持续更新,底层的一个通信框架的更新或者某个路径的代码优化都可能让性
能有较大的提升。
目前,sparkStreaming还不能达到一条一条记录的精细控制,还是以batch为单位。所以像
Storm一般用于金融领域,达到每笔交易的精细控制。
但是两者的基因不同,更具体地说就是核心数据抽象不同。这是无法改变的,而且也不会轻易
改变,这样的基因也决定了它们各自最适合的应用场景。
Spark Streaming的核心抽象是DSTream,里面是RDD,下层是Spark核心DAG调度,所以
Spark Streaming的这一基因决定了其粒度是小批量的,无法做更精细地控制。数据的可靠性
也是以批次为粒度的,但好处也很明显,就是有可能实现更大的吞吐量。
另外,得益于Spark平台的良好整合性,完成相同任务的流式计算程序与历史批量处理程序的
代码基本相同,而且还可以使用平台上的其他模块比如SQL、机器学习、图计算的计算能力,
在开发效率上占有优势。而Storm更擅长细粒度的消息级别的控制,比如延时可以实现毫秒
级,数据可靠性也是以消息为粒度的。
核心数据抽象的不同导致了它们在计算模式上的本质区别。Spark Streaming在本质上其实是
像MR一样的批处理计算,但将批处理的周期从常规的几十分钟级别尽可能缩短至秒级(毫秒
级),也算达到了实时计算的延时指标。而且,它支持各类数据源,基本可以实现流式计算的
功能,但延时无法进一步缩短了。但Storm的设计初衷就是实时计算,毫秒级的计算当然不在
话下,而且后期通过更高级别的Trident也实现了小批次处理功能。
架构及原理
架构设计
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理
系统,可以对多种数据源(如Kafka、Flume、Twitter、ZeroMQ和TCP
套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外
部文件系统、数据库或应用到实时仪表盘。

Spark Streaming是将流式计算分解成一系列短小的批处理作业,也就是
把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段
的数据DStream(Discretized-离散化 Stream),每一段数据都转换成
Spark中的RDD(Resilient Distributed Dataset),然后将Spark
Streaming中对DStream的Transformations操作变为针对Spark中对
RDD的Transformations操作,将RDD经过操作变成中间结果保存在内存
中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到
外部设备。
对DStream的处理,每个DStream都要按照数据流到达的先后顺序依次
进行处理。即SparkStreaming天然确保了数据处理的顺序性。
这样使所有的批处理具有了一个顺序的特性,其本质是转换成RDD的血
缘关系。所以,SparkStreaming对数据天然具有容错性保证。
为了提高SparkStreaming的工作效率,你应该合理的配置批的时间间
隔, 最好能够实现上一个批处理完某个算子,下一个批子刚好到来。
各概念阐述
数据挖掘

数据挖掘:也就是data mining,是一个很宽泛的概念,也是一个新兴学科,旨在如何从海量数据
中挖掘出有用的信息来。
数据挖掘这个工作BI(商业智能)可以做,统计分析可以做,大数据技术可以做,市场运营也可
以做,或者用excel分析数据,发现了一些有用的信息,然后这些信息可以指导你的business,这也
属于数据挖掘。
机器学习

机器学习:machine learning,是计算机科学和统计学的交叉学科,基本目标是学习一个x->y的函数
(映射),来做分类、聚类或者回归的工作。之所以经常和数据挖掘合在一起讲是因为现在好多
数据挖掘的工作是通过机器学习提供的算法工具实现的,例如广告的ctr预估,PB级别的点击日志
在通过典型的机器学习流程可以得到一个预估模型,从而提高互联网广告的点击率和回报率;个
性化推荐,还是通过机器学习的一些算法分析平台上的各种购买,浏览和收藏日志,得到一个推
荐模型,来预测你喜欢的商品。
深度学习

深度学习:deep learning,机器学习里面现在比较火的一个topic,本身是神经网络算法的衍生,在
图像,语音等富媒体的分类和识别上取得了非常好的效果,所以各大研究机构和公司都投入了大
量的人力做相关的研究和开发。
总结:数据挖掘是个很宽泛的概念,数据挖掘常用方法大多来自于机器学习这门学科,深度学习
也是来源于机器学习的算法模型,本质上是原来的神经网络。

“人工智能”一词最初是在1956 年Dartmouth学会上提出的。从那以后,研究者们发展了众多
理论和原理,人工智能的概念也随之扩展。人工智能(Artificial Intelligence),英文缩写为AI。
它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术
科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类
智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语
言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以
设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。
人工智能是对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、
也可能超过人的智能。

数据挖掘体系

GPU计算
机器学习的应用
什么是机器学习
机器学习是是一门多领域交叉学科。涉及概率论、统计学、逼近论、凸分析、算法复杂度理论
等多门学科。机器学习的算法在数据挖掘里被大量使用。
此外它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领
域。
机器学习的应用
市场分析和管理
比如:目标市场,客户关系管理(CRM),市场占有量分析,交叉销售,市场分割
1.比如做目标市场分析:
构建一系列的“客户群模型”,这些顾客具有相同特征:兴趣爱好,收入水平,消费习惯,等
等。确定顾客的购买模式
CTR估计(广告点击率预测)比如通过逻辑回归来实现。
2.比如做交叉市场分析:
货物销售之间的相互联系和相关性,以及基于这种联系上的预测
风险分析和管理,风险预测,客户保持,保险业的改良,质量控制,竞争分析
1.比如做公司分析和风险管理:
财务计划——现金流转分析和预测
资源计划——总结和比较资源和花费
竞争分析——对竞争者和市场趋势的监控
对顾客按等级分组和基于等级的定价过程
对定价策略应用于竞争更激烈的市场中
保险公司对于保险费率的厘定
欺骗检测和异常模式的监测(孤立点)
欺诈行为检测和异常模式
1.比如对欺骗行为进行聚类和建模,并进行孤立点分析
2.汽车保险:相撞事件的分析
3.洗钱:发现可疑的货币交易行为
4.医疗保险:职业病人,医生或以及相关数据分析
5.电信:电话呼叫欺骗行为,根据呼叫目的地,持续事件,日或周呼叫次数,分析该模型发现
与期待标准的偏差
6.零售产业:比如根据分析师估计有38%的零售额下降是由于雇员的不诚实行为造成的
7.反恐
文本挖掘
1.新闻组
2.电子邮件(垃圾邮件的过滤)可以通过贝叶斯来实现
3.文档归类
4.评论自动分析
5.垃圾信息过滤
6.网页自动分类等
天文学
例如:JPL实验室和Palomar天文台层借助于数据挖掘工具
推荐系统
当当网的图书推荐
汽车之家的同类汽车推荐
淘宝的同类商品推荐
新浪的视频推荐
百度知道的问题推荐
社交推荐
职位推荐
智能博弈
棋谱学习
频繁模式挖掘
购物篮商品分析,典型案例:啤酒-尿布

模式识别
1.语音识别
2.图像识别
指纹、虹膜纹识别
脸像识别
车牌识别
动态图像识别
小波分析
未完待续