可视化Tensorflow
PlayGround
PlayGround是一个用于教学目的的简单神经网络的在线演示、实验的图形化平台,非常强大地可视化了神经网络的训练过程。使用它可以在浏览器里训练神经网络,对Tensorflow 有一个感性的认识。
PlayGround 界面从左到右由数据(DATA)、特征(FEATURES)、神经网络的隐藏层(HIDDEN LAYERS)和层中的连接线和输出(OPUPUT)几个部分组成,如图所示。

数据
在二维平面内,点被标记成两种颜色。深色(电脑屏幕显示为蓝色)代表正值,浅色(电脑屏幕显示为黄色)代表负值。这两种颜色表示想要区分的两类,如图所示。
网站提供了4 种不同形态的数据,分别是圆形、异或、高参和螺旋,如图所示。神经网络会根据所给的数据进行训练,再分类规律相同的点。


PlayGournd 中的数据配置非常灵活,可以调整噪声(noise)的大小。图下展示的是噪声为0、25 和50 时的数据分布。

PlayGournd 中也可以改变训练数据和测试数据的比例(ratio)。下图展示的是训练数据和测试数据比例为1 : 9 和9 : 1 时的情况。

此外,PlayGournd 中还可以调整输入的每批(batch)数据的多少,调整范围可以是1~30,就是说每批进入神经网络数据的点可以1~30个,如下图所示。

特征
接下来我们需要做特征提取(feature extraction),每一个点都有 和 两个特征,由这两个特征还可以衍生出许多其他特征,如 等,如图所示。

从颜色上,
的左边浅色(电脑屏幕显示为黄色)是负,右边深色(电脑屏幕显示为蓝色)是正,
表示此点的横坐标值。同理,
上边深色是正,下边浅色是负,
表示此点的纵坐标值。
是关于横坐标的“抛物线”信息,
是关于纵坐标的“抛物线”信息,
是“双曲抛物面”的信息,
是关于横坐标的“正弦函数”信息,
是关于纵坐标的“正弦函数”信息。
因此,我们要学习的分类器(classifier)就是要结合上述一种或者多种特征,画出一条或者多条线,把原始的蓝色和黄色数据分开。
隐藏层
我们可以设置隐藏层的多少,以及每个隐藏层神经元的数量,如下图所示。

隐藏层之间的连接线表示权重(weight),深色(蓝色)表示用神经元的原始输出,浅色(黄色)表示用神经元的负输出。连接线的粗细和深浅表示权重的绝对值大小。鼠标放在线上可以看到具体值,也可以修改值,如下图所示。
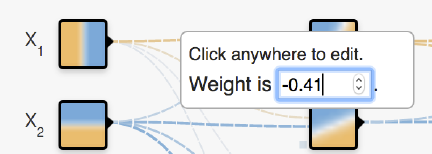
修改值时,同时要参虑激活函数,例如,当换成Sigmoid 时,会发现没有负向的黄色区域了,因为Sigmoid 的值域是(0,1),如下图所示。

下一层神经网络的神经元会对这一层的输出再进行组合。组合时,根据上一次预测的准确性,我们会通过反向传播给每个组合不同的权重。组合时连接线的粗细和深浅会发生变化,连接线的颜色越深越粗,表示权重越大。
输出
输出的目的是使黄色点都归于黄色背景,蓝色点都归于蓝色背景,背景颜色的深浅代表可能性的强弱。
我们选定螺旋形数据,7 个特征全部输入,进行试验。选择只有3 个隐藏层时,第一个隐藏层设置8 个神经元,第二个隐藏层设置4 个神经元,第三个隐藏层设置2 个神经元。训练大概2 分钟,测试损失(test loss)和训练损失(training loss)就不再下降了。训练完成时可以看出,我们的神经网络已经完美地分离出了橙色点和蓝色点,如下图所示。

假设我们只输入最基本的前4 个特征,给足多个隐藏层,看看神经网络的表现。假设加入6 个隐藏层,前4 层每层有8 个神经元,第五层有6 个神经元,第六层有2 个神经元。结果如下图所示。

我们发现,通过增加神经元的个数和神经网络的隐藏层数,即使没有输入许多特征,神经网络也能正确地分类。但是,假如我们要分类的物体是猫猫狗狗的图片,而不是肉眼能够直接识别出特征的黄点和蓝点呢?这时候怎样去提取那些真正有效的特征呢?
有了神经网络,我们的系统自己就能学习到哪些特征是有效的、哪些是无效的,通过自己学习的这些特征,就可以做到自己分类,这就大大提高了我们解决语音、图像这种复杂抽象问题的能力。
TensorBoard
TensorBoard 是TensorFlow 自带的一个强大的可视化工具,也是一个Web 应用程序套件。
TensorBoard 目前支持7 种可视化,即SCALARS、IMAGES、AUDIO、GRAPHS、DISTRIBUTIONS、HISTOGRAMS 和EMBEDDINGS。这7 种可视化的主要功能如下。
- SCALARS:展示训练过程中的准确率、损失值、权重/偏置的变化情况。
- IMAGES:展示训练过程中记录的图像。
- AUDIO:展示训练过程中记录的音频。
- GRAPHS:展示模型的数据流图,以及训练在各个设备上消耗的内存和时间。
- DISTRIBUTIONS:展示训练过程中记录的数据的分布图。
- HISTOGRAMS:展示训练过程中记录的数据的柱状图。
- EMBEDDINGS:展示词向量(如Word2vec)后的投影分布。
TensorBoard 通过运行一个本地服务器,来监听6006 端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。我们看一下TensorBoard能够绘制出哪些东西。
TensorBoard 的可视化界面如图所示。

从图中可以看到,在标题处有上述几个可视化面板,下面通过一个示例,分别介绍这些可视化面板的功能。
这里,我们运行手写数字识别的入门例子,如下:
python tensorflow-1.1.0/tensorflow/examples/tutorials/mnist/mnist_with_summaries.py
然后,打开TensorBoard 面板:
tensorboard ––logdir=/tmp/mnist/logs/mnist_with_summaries
这时,输出:
Starting TensorBoard 39 on port 6006
(You can navigate to http://192.168.0.101:6006)
我们就可以在浏览器中打开http://192.168.0.101:6006,查看面板的各项功能。
SCALARS 面板
SCALARS 面板的左边是一些选项,包括Split on undercores(用下划线分开显示)、Datadownloadlinks(数据下载链接)、Smoothing(图像的曲线平滑程度)以及Horizontal Axis(水平轴)的表示,其中水平轴的表示分3 种(STEP 代表迭代次数,RELATIVE 代表按照训练集和测试集的相对值,WALL 代表按照时间),如下图左边所示。下图右边给出了准确率和交叉熵损失函数值的变化曲线(迭代次数是1000 次)。

SCALARS 面板中还绘制了每一层的偏置(biases)和权重(weights)的变化曲线,包括每次迭代中的最大值、最小值、平均值和标准差,如下图所示。

IMAGES 面板
下图展示了训练数据集和测试数据集经过预处理后图片的样子。

AUDIO 面板
AUDIO 面板是展示训练过程中处理的音频数据。这里暂时没有找到合适的例子,读者了解即可。
GRAPHS 面板
GRAPHS 面板是对理解神经网络结构最有帮助的一个面板,它直观地展示了数据流图。
下图所示界面中节点之间的连线即为数据流,连线越粗,说明在两个节点之间流动的张量(tensor)越多。

在GRAPHS 面板的左侧,可以选择迭代步骤。可以用不同Color(颜色)来表示不同的Structure(整个数据流图的结构),或者用不同Color 来表示不同Device(设备)。例如,当使用多个GPU 时,各个节点分别使用的GPU 不同。
当我们选择特定的某次迭代(如第899 次)时,可以显示出各个节点的Compute time(计算时间)以及Memory(内存消耗),如下图所示。

DISTRIBUTIONS 面板
DISTRIBUTIONS 面板和接下来要讲的HISTOGRAMS 面板类似,只不过是用平面来表示来自特定层的激活前后、权重和偏置的分布。下图展示的是激活之前和激活之后的数据分布。

HISTOGRAMS 面板
HISTOGRAMS 主要是立体地展现来自特定层的激活前后、权重和偏置的分布。下图展示的是激活之前和激活之后的数据分布。

EMBEDDINGS 面板
EMBEDDINGS 面板在MNIST 这个示例中无法展示,Word2vec等网络能看到这个面板的词嵌入投影。
小结
可视化是研究深度学习的一个重要方向,有利于我们直观地探究训练过程中的每一步发生的变化。TensorFlow 提供了强大的工具TensorBoard,不仅有完善的API 接口,而且提供的面板也非常丰富。以后我们会讲解实现TensorBoard 的API、TensorFlow 的调试工具,调试和可视化配合起来,有利于精准地调整模型。